米国ザ コカ・コーラ カンパニーの日本法人。清涼飲料水の製品企画、研究開発、原液製造、宣伝・マーケティングなどを行う。従業員数は 487 人(2017 年 3 月 31 日時点)。炭酸飲料「コカ・コーラ」のほか、「ジョージア」、「爽健美茶」など多くのメガブランドを擁する。
BigQuery、Google Cloud Storage、Google Cloud Machine Learning Engine、Cloud Auto ML、Cloud Dataflow、Cloud Datalab、Google Cloud Interconnect など
法人向けの事務用品通販サービス(個人向けにも「LOHACO」という名称で EC サービスを展開中)。全国に 9 か所の物流センターを構えることで、都市部では注文当日、翌日の配送を実現している(社名の由来は「明日来る」から)。従業員数は連結子会社含め 3,200 名。EC サイトから物流までの全工程を独自に運用している。
Google Cloud Platform 入門編トレーニング「初めての Google Cloud Platform」日時:2019 年 2 月 20 日(水)13:00-18:00会場:ベルサール渋谷ファースト Google Cloud Platform 認定トレーナー 技術教育エンジニア 古賀 聖人氏 Google Cloud ソリューション アーキテクト 中井 悦司 機械学習講座「エンドツーエンドで学ぶ GCP を活用した機械学習モデルの構築」日時:2019 年 3 月 6 日(水) 14:00-17:00会場:Google 六本木オフィス Google Cloud ソリューション アーキテクト 中井 悦司 Big Data 講座「GCP を活用した効率的なビッグデータの利活用方法」日時:2019 年 3 月 14 日(木) 14:00-17:00会場:Google 六本木オフィス Google Cloud Japan カスタマーエンジニア 脇阪 洋平 アーキテクト デザイン講座「アーキテクチャ原則とパターンで学ぶ、実践的な GCP 使いこなし講座」日時:2019 年 3 月 19 日(火)14:00-17:00会場:Google 六本木オフィス Google Cloud カスタマーエンジニア 福田 潔 Google Cloud カスタマー エンジニア 水江 伸久
Google Cloud Speech-to-Text、BigQuery、Google Cloud Storage、Google App Engine、Google Compute Engine など
国内 5 大商社の一角を担う丸紅株式会社の 100% 子会社として、先端技術の発掘・開発、コンサルティングから、システム企画・設計・開発、データセンター サービスの提供などまでを行うシステム インテグレーター。コンピュータ、ネットワーク、情報システムなどにおける最先端技術を基軸として、あらゆる産業の IT ライフサイクル全般に対するソリューションを提供しています。従業員数は 564 名(2018 年 4 月 1 日現在)
# DDPG's way of value estimation def get_qval(self, observation, action): """Get Q-val.""" return self.critic.get_qval(observation, action) # TD3 and C2A2's way of value estimation def get_qval(self, observation, action): """Get Q-val.""" q_val1 = self.critic1.get_qval(observation, action) q_val2 = self.critic2.get_qval(observation, action) return np.minimum(q_val1, q_val2) # DDPG and TD3's way for action selection def action(self, observation): """Return an action according to the agent's policy.""" return self.actor.get_action(observation) # C2A2's way for action selection def action(self, observation): """Return an action according to the agent's policy.""" action1 = self.actor1.get_action(observation) action2 = self.actor2.get_action(observation) q_val1 = self.get_qval(observation, action1) q_val2 = self.get_qval(observation, action2) q_val1 = np.expand_dims(q_val1, axis=-1) q_val2 = np.expand_dims(q_val2, axis=-1) return np.where(q_val1 > q_val2, action1, action2)
# DDPG's way of value estimation
def get_qval(self, observation, action):
"""Get Q-val."""
return self.critic.get_qval(observation, action)
# TD3 and C2A2's way of value estimation
q_val1 = self.critic1.get_qval(observation, action)
q_val2 = self.critic2.get_qval(observation, action)
return np.minimum(q_val1, q_val2)
# DDPG and TD3's way for action selection
def action(self, observation):
"""Return an action according to the agent's policy."""
return self.actor.get_action(observation)
# C2A2's way for action selection
action1 = self.actor1.get_action(observation)
action2 = self.actor2.get_action(observation)
q_val1 = self.get_qval(observation, action1)
q_val2 = self.get_qval(observation, action2)
q_val1 = np.expand_dims(q_val1, axis=-1)
q_val2 = np.expand_dims(q_val2, axis=-1)
return np.where(q_val1 > q_val2, action1, action2)
import gym env = gym.make('BipedalWalker-v2') obs = env.reset()
import gym
env = gym.make('BipedalWalker-v2')
obs = env.reset()
agent = Agent(...) done = False while not done: action = agent.take_action(obs) obs, reward, done , info = env.step(action)
agent = Agent(...)
done = False
while not done:
action = agent.take_action(obs)
obs, reward, done , info = env.step(action)
hyperparameter.yaml
gcloud ml engine submit
gym
import argparse parser = argparse.ArgumentParser() ... parser.add_argument( '--batch_size', help = 'Batch size for agent.', type = int, default = 64 ) ... args = parser.parse_args() run_model(args)
import argparse
parser = argparse.ArgumentParser()
...
parser.add_argument(
'--batch_size',
help = 'Batch size for agent.',
type = int,
default = 64
)
args = parser.parse_args()
run_model(args)
Model
metrics
model = Model(...) ... model.compile(loss='rmse', metrics=['rmse'])
model = Model(...)
model.compile(loss='rmse', metrics=['rmse'])
# Initialize a tensor. import keras.backend as K reward_tensor = K.variable(value=0) # Create custom reward. K.get_session().run(tf.global_variables_initializer()) def reward(y_true, y_pred): return self.reward_tensor model.compile(loss='rmse', metrics=reward]) # At each iteration, update tensor: for _ in range(nepochs): ... K.set_value(self.reward_tensor, self.cur_reward) ...
# Initialize a tensor.
import keras.backend as K
reward_tensor = K.variable(value=0)
# Create custom reward.
K.get_session().run(tf.global_variables_initializer())
def reward(y_true, y_pred):
return self.reward_tensor
model.compile(loss='rmse', metrics=reward])
# At each iteration, update tensor:
for _ in range(nepochs):
K.set_value(self.reward_tensor, self.cur_reward)
episode_reward = tf.placeholder(dtype=tf.float32, shape=[]) tf.summary.scalar('reward', episode_reward) with tf.Session() as sess: ... merge = tf.summary.merge_all() summary = sess.run(merge, feed_dict={episode_reward: reward}) train_writer.add_summary(summary, iteration) ...
episode_reward = tf.placeholder(dtype=tf.float32, shape=[])
tf.summary.scalar('reward', episode_reward)
with tf.Session() as sess:
merge = tf.summary.merge_all()
summary = sess.run(merge, feed_dict={episode_reward: reward})
train_writer.add_summary(summary, iteration)
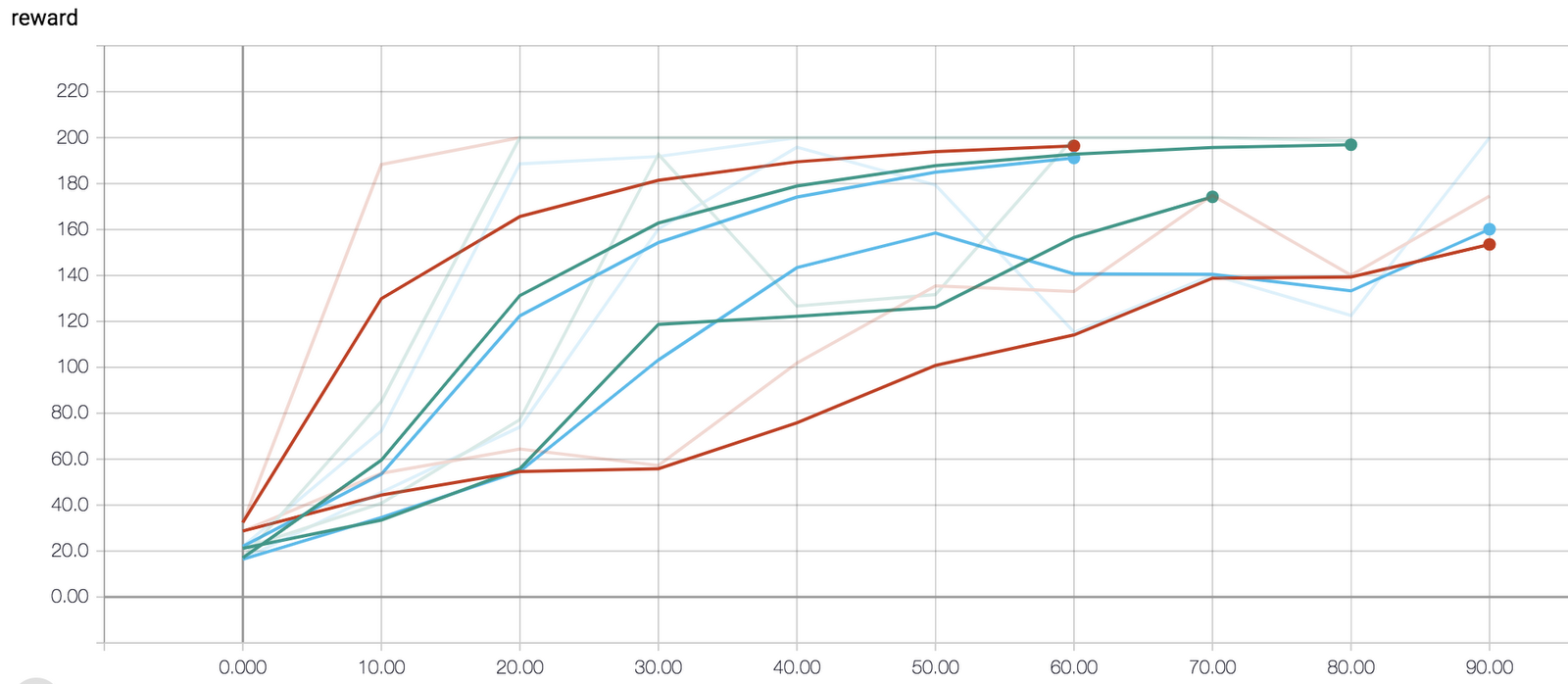
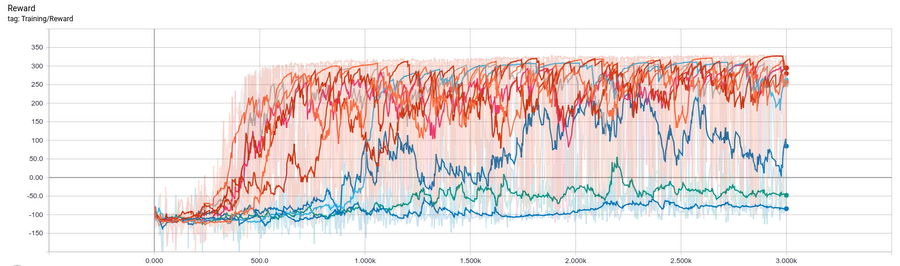
reward
--job-dir
TF_CONFIG
# Append trial_id to path if we are doing hp tuning. trial_id = json.loads( os.environ.get('TF_CONFIG', '{}') ).get('task', {}).get('trial', '') model_dir_hp = os.path.join(model_dir, trial_id)
# Append trial_id to path if we are doing hp tuning.
trial_id = json.loads(
os.environ.get('TF_CONFIG', '{}')
).get('task', {}).get('trial', '')
model_dir_hp = os.path.join(model_dir, trial_id)
__init__.py
setup.py
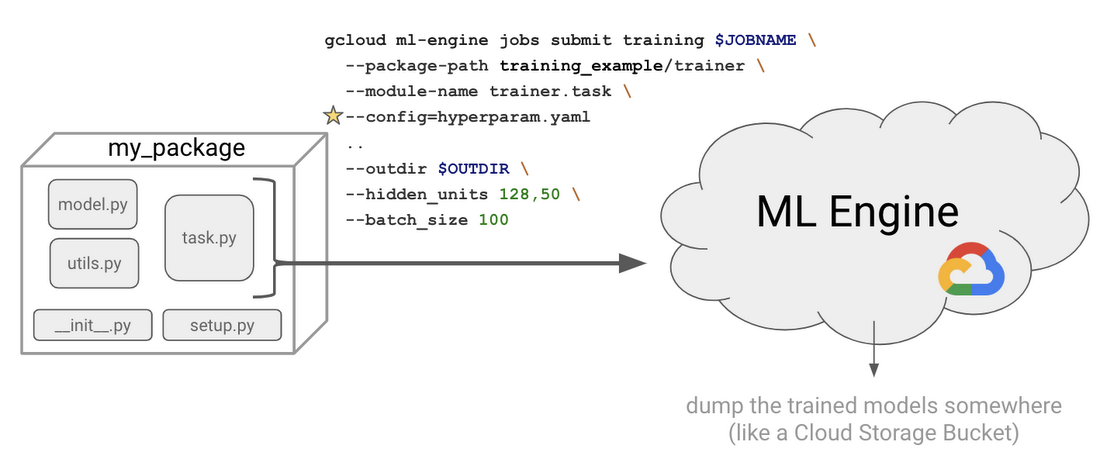
rl_on_gcp # root directory setup.py # says how to install your package trainer # package name, “trainer” is convention # .py files specific to your job, e.g. model.py __init__.py # python convention indicating this is a package
rl_on_gcp # root directory
setup.py # says how to install your package
trainer # package name, “trainer” is convention
# .py files specific to your job, e.g. model.py
__init__.py # python convention indicating this is a package
yaml
maxTrials
maxParallelTrials
algorithm
GRID_SEARCH
trainingInput: scaleTier: BASIC_GPU hyperparameters: maxTrials: 40 maxParallelTrials: 5 enableTrialEarlyStopping: False goal: MAXIMIZE hyperparameterMetricTag: reward params: - parameterName: update_target type: INTEGER minValue: 5000 maxValue: 20000 scaleType: UNIT_LOG_SCALE - parameterName: init_eta type: DOUBLE minValue: 0.8 maxValue: 0.95 scaleType: UNIT_LOG_SCALE - parameterName: learning_rate type: DOUBLE minValue: 0.00001 maxValue: 0.001 scaleType: UNIT_LOG_SCALE - parameterName: batch_size type: DISCRETE discreteValues: - 4 - 16 - 32 - 64 - 128 - 256 - 512
trainingInput:
scaleTier: BASIC_GPU
hyperparameters:
maxTrials: 40
maxParallelTrials: 5
enableTrialEarlyStopping: False
goal: MAXIMIZE
hyperparameterMetricTag: reward
params:
- parameterName: update_target
type: INTEGER
minValue: 5000
maxValue: 20000
scaleType: UNIT_LOG_SCALE
- parameterName: init_eta
type: DOUBLE
minValue: 0.8
maxValue: 0.95
- parameterName: learning_rate
minValue: 0.00001
maxValue: 0.001
- parameterName: batch_size
type: DISCRETE
discreteValues:
- 4
- 16
- 32
- 64
- 128
- 256
- 512
JOBNAME=rl_job_hp_$(date -u +%y%m%d_%H%M%S) REGION=us-central1 BUCKET=your-bucket gcloud ml-engine jobs submit training $JOBNAME \ --package-path=$PWD/rl_on_gcp/trainer \ --module-name=trainer.trainer \ --region=$REGION \ --staging-bucket=gs://$BUCKET \ --config=hyperparam.yaml \ --runtime-version=1.10 \ --\ --steps=100000\ --start_train=10000\ --buffer_size=10000\ --model_dir='gs://your-bucket/rl_on_gcp'
JOBNAME=rl_job_hp_$(date -u +%y%m%d_%H%M%S)
REGION=us-central1
BUCKET=your-bucket
gcloud ml-engine jobs submit training $JOBNAME \
--package-path=$PWD/rl_on_gcp/trainer \
--module-name=trainer.trainer \
--region=$REGION \
--staging-bucket=gs://$BUCKET \
--config=hyperparam.yaml \
--runtime-version=1.10 \
--\
--steps=100000\
--start_train=10000\
--buffer_size=10000\
--model_dir='gs://your-bucket/rl_on_gcp'
--config
"discount_rate": "0.83375867407642434", "n_games_per_update": "4", "n_hidden": "16", "learning_rate": "0.055623309804870541"
"discount_rate": "0.83375867407642434",
"n_games_per_update": "4",
"n_hidden": "16",
"learning_rate": "0.055623309804870541"