Cloud TPU Pod の ML パフォーマンス ―― TensorFlow モデルを高速かつ低コストでトレーニング

Google Cloud Japan Team
※この投稿は米国時間 2018 年 12 月 13 日に Google Cloud blog に投稿されたものの抄訳です。
データ サイエンティストや機械学習(ML)エンジニア、ML 研究者は、モデルのトレーニングが完了するのを数日あるいは数週間も待たなければならないとしたら、自身の生産性を最大限に発揮することはできません。
MLPerf は、一般的な ML 問題を所定の精度でトレーニングするのにかかる時間を測定するベンチマーク スイートです。業界の幅広い企業が支援するこのスイートの初期バージョンである MLPerf v0.5 のベンチマーク コンテストが公開され、その中には私たちが提出した Google Cloud インフラストラクチャ上の GPU と TPU のテスト結果が含まれています。ただし、実際の ML の難しさは現在の MLPerf のトレーニング タスクを大きく上回るため、MLPerf はまだ、非常に大きな問題でトレーニングを行う場合のシステム パフォーマンスを反映していません。
そこで私たちは、大規模な設定での ML トレーニング パフォーマンスをより忠実に表すケース スタディとして、MLPerf モデルの 1 つである ResNet-50 v1.5 を、画像分類データセットとして有名な ImageNet でトレーニングすることにしました。このケース スタディでは、膨大な画像を処理する際に観察される定常的なトレーニング パフォーマンスに焦点を当てます。こうしたスケーリング パフォーマンスは、機械翻訳や音声認識、言語モデリング、GAN(敵対的生成ネットワーク)トレーニング、強化学習など、ML アプリケーション分野で広く見られます。
パフォーマンス比較
Google Cloud Platform(GCP)は、あらゆるタイプの機械学習アクセラレータを提供しています。ここでは、Cloud TPU Pod と、NVIDIA Tesla V100 GPU を接続した Google Cloud VM を取り上げます。現在アルファ リリースされている Cloud TPU Pod は、数百個に上る Google のカスタム Tensor Processing Unit(TPU)チップと数十台のホスト マシンで構築された密結合型のスーパーコンピュータです。これらはすべて超高速のカスタム インターコネクトで接続されています。以下で紹介する結果を誰でも完全に再現できるように、私たちはオープンソースの TensorFlow 1.12 で実装された ResNet-50 v1.5(GPU バージョン、TPU バージョン)を使用しました。大規模な ML トレーニング シナリオ(eBay による数千または数億の商品画像に関するトレーニングを想像してください)をシミュレートするため、GPU システムと TPU システムの両方で、測定開始前にウォームアップ エポックを実行します。これにより、一次的なセットアップや評価のコストが除かれ、キャッシュが完全に満たされます。以下に示すすべてのシステムは、76 % という同じ品質スコアの Top-1 精度で ResNet-50 をトレーニングします。詳細はパフォーマンス比較方法のページをご覧ください。
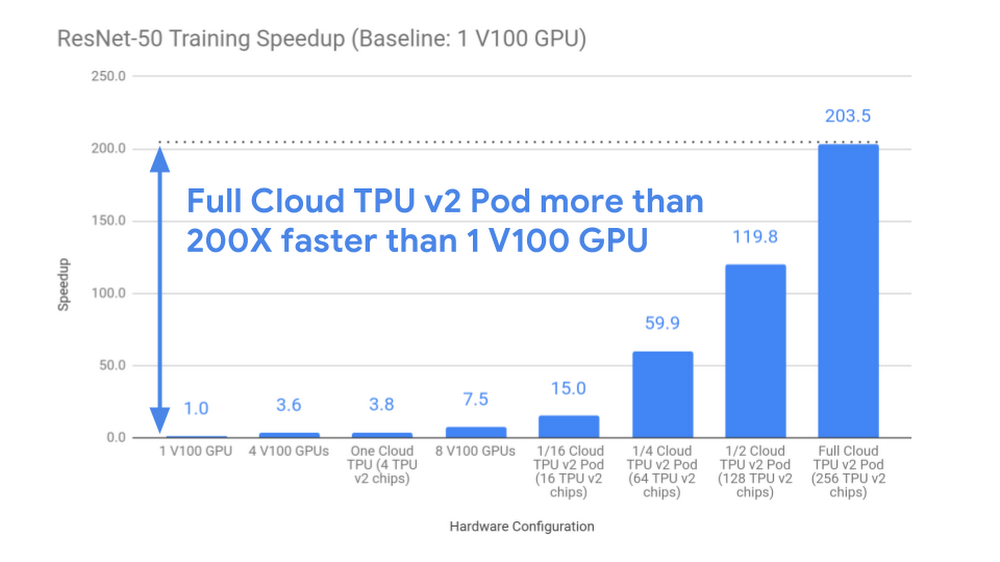
私たちのテスト結果は、Cloud TPU Pod がこの大規模トレーニング タスクにおいて、ほぼ線形の高速化を実現することを示しています。最大の Cloud TPU Pod 構成(このテストでは 256 チップ)の場合は、1 個の V100 GPU と比べて 200 倍のスピードアップを記録しました(下図)。1 個の最新 GPU を使って 26 時間以上待つ代わりに、フル構成の Cloud TPU v2 Pod を使用すれば、7.9 分のトレーニング時間で同じ結果が得られるのです。
コスト比較
ML トレーニング コストを減らすことで、より広範な ML 実務家のグループが、より幅広いモデル アーキテクチャやハイパーパラメータを探索し、最新の ML モデルを大規模かつ高品質のデータセットでトレーニングすることが可能になります。以下に示すように、ResNet-50 をフル構成の Cloud TPU v2 Pod でトレーニングすると、8 個の V100 GPU を接続した n1-standard-64 Google Cloud VM で同じモデルを同じ精度でトレーニングする場合に比べて、コストが 40 % 近く下がります。しかも、フル構成の Cloud TPU v2 Pod のほうが、トレーニング タスクを 27 倍高速に完了します。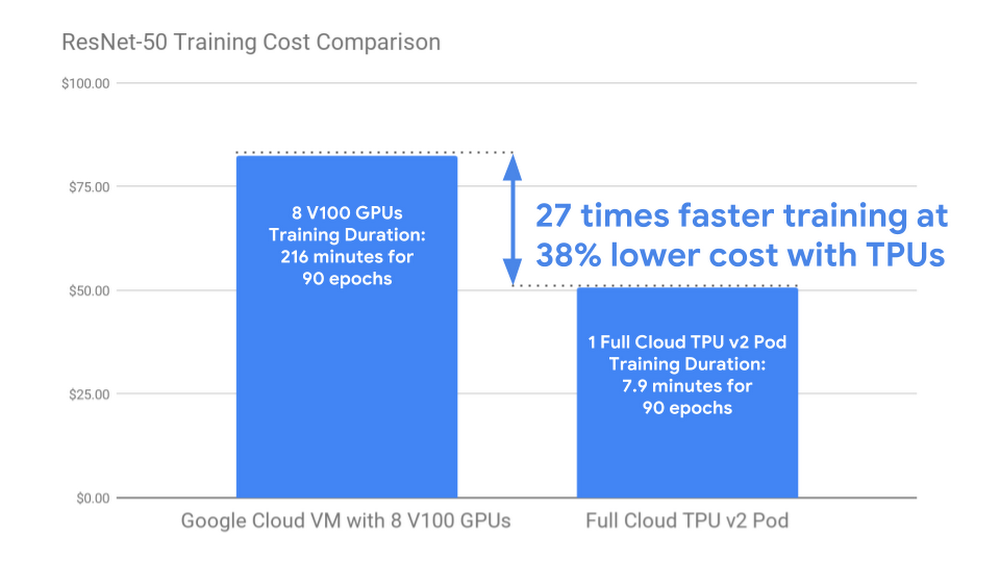
定性的な特徴
Cloud TPU は機械学習向けに一から設計されました。同期トレーニングに優れており、モデルの作成時に結果を簡単に再現できます。また、Cloud TPU のソフトウェア スタックは、Cloud TPU Pod 内の複数デバイスに ML モデルを透過的に分散し、スケーリングを容易にします。さらに、Cloud TPU はすべて Google Cloud の高速ストレージ システムに統合されているので、データ入力パイプラインは TPU のさまざまな使い方に対応できます。パラメータ サーバーを管理したり、複雑なカスタム ネットワーキング構成に対応したり、クラウドで比類ないトレーニング パフォーマンスを実現するために特殊なストレージ システムをセットアップしたりする必要はありません。1 つの Cloud TPU で動作するコードは、フル構成の Pod や、中規模の “スライス” でも動作します。
私たちは「高パフォーマンスの機械学習を、すべての人にとって、よりインタラクティブで使いやすいものにする」という目標を掲げており、Cloud TPU Pod によってこの目標に一歩近づきました。Cloud TPU Pod を使用すれば、数分で反復トレーニングを行ったり、超大規模な本番モデルを数週間ではなく数時間や数日でトレーニングしたりできます。Cloud TPU のおかげで、最先端の機械学習モデルの作成とデプロイを、より簡単に、迅速に、経済的に行えるのです。
今すぐお試しください
クイックスタート ガイドに従えば、Cloud TPU を使い始めることができます。現在アルファ版が提供されている Cloud TPU Pod を試したい方は、こちらからお申し込みください。1 つの Cloud TPU と Cloud TPU Pod 全体のどちらを試すかを判断するにあたっては、こちらのドキュメントをご覧ください。- By Zak Stone, Product Manager for Cloud TPUs, Google Brain Team



