Google Cloud Platform Japan Blog
最新情報や使い方、チュートリアル、国内外の事例やイベントについてお伝えします。
SRE チームの評価に役立つレベル別チェック リスト
2019年2月21日木曜日
※この投稿は米国時間 2019 年 1 月 26 日に Google Cloud blog に
投稿
されたものの抄訳です。
このたび、
『The Site Reliability Workbook』がウェブサイトで閲覧できる
ようになりました。Google で生まれ、他の企業にも広まりつつある Site Reliability Engineering(SRE)は、運用上の問題をソフトウェア的に解決するためのエンジニアリングであり、Google におけるエンジニアリングの
本質的な部分
を占めています。
SRE は考え方であり、一連のプラクティスやメトリクスであり、システムの信頼性を保証するための処方箋でもあります。SRE モデルを構築すれば、サービスの信頼性が向上し、運用コストが下がり、人間が行う作業の価値が高くなって、サービスとチームの双方で大きなメリットが得られます。上述の新しいワークブックは、SRE の構築に向けてスタートを切り、SRE プラクティスを実行に移すための具体的なヒントを提供します(本稿では、ワークブック内の章に対応する本稿での記述箇所にリンクを付加しています)。
私たちはよく、SRE の実施とは実際にどういうことなのかと尋ねられます。これは、お客様がそれぞれの SRE プラクティス を築き上げていくうえで、達成度の定量化に苦労されているからでしょう。この問題に対する単純で標準的な答えはありませんが、本稿では、初歩的なものから順に達成度を測るためのチェック リストを示していきます(決して網羅的なものではありませんが)。このチェック リストは、高信頼性サービスの担当部門が SRE モデルに向かってチームを変えていこうとするときに役立ちます。どのチェック リストも項目は時系列順に並べてありますが、実際のニーズや優先順位がチームによって異なることは私たちも認識しています。
経験豊富な SRE チームに属する方にとっては、このチェック リストは業界ベンチマークの 1 つとして役に立つかもしれません。他の人たちも自身の
チェック リストをぜひ公開
してください。もちろん、SRE は厳密な科学ではなく、実現過程でさまざまな難問にぶつかるでしょう。各項目の 100 % 達成には至らないかもしれません。それでも、継続していくことが SRE にとって大切だということを、私たちは Google での経験から知っています。
SRE の基本
次の 3 つは SRE の基本原則ですが、本番システムに対して責任を負うチームであれば、名前がどうであれ、SRE チームを作る前から、あるいは SRE チームへの転換と並行して、広く採用しているプラクティスでもあります。
何らかの
サービス レベル目標(SLO)を決め
(開発、事業部門の一部でない場合は、これらの部門のメンバーと共同で)、ほぼ毎月目標を達成していること
非難を伴わない障害報告書
を記録するカルチャーがあること
本番環境におけるインシデントの管理プロセス
が作られていること(これは全社的であることが望ましい)
初級者チーム
Google の SRE チームは、全部ではなくてもそのほとんどが、次のプラクティスと特長を確立しています。チームが置かれた環境にこれらの実現を阻むもっともな理由がないかぎり、私たちはこれらを、優れた SRE チームの基礎だと考えています。
人員の配置転換と採用のプランがあり
、予算が承認されていること
スタッフを配置したチームが
何らかのサービスのオンコール サポート
を担当するとともに、少なくとも
システム運用の負荷
の一部を担っていること
リリース プロセス、サービスのセットアップとティアダウン
(そして可能ならフェイルオーバー)のためのマニュアルを整備していること
SLO の一部として
カナリア リリース
を評価していること
必要なときのためにロールバック メカニズムを用意していること
(ただし、たとえばモバイル アプリケーションが関係するときは簡単ではないことが考慮されます)
完全でなくても、
運用手順書(プレイブック / ランブック)があること
少なくとも年 1 回は理論的な(ロールプレイングによる)
ディザスタ リカバリ テスト
を実施していること
SRE が
プロジェクトの仕事を立案、実施していること
(開発者の支持を必要としない運用負担軽減の取り組みなど、開発者から直接見えない部分でもかまいません)
次の項目も、発足したばかりの SRE チームで一般的になっているものです。こういうものがなければ、チームが不健全で持続可能性に問題がある兆候かもしれません。
定期的に(つまり毎週)
インシデント対応手続き
の訓練をする程度のオンコール
SRE の統括責任者(つまり CTO)が審査、承認した
SRE チーム憲章
問題点や目標について議論し、情報を共有するための
SRE と開発リーダーの定例会議
開発と SRE の共同作業
によるプロジェクトの立案、実施。SRE の貢献とプラスの効果が開発のリーダーにも見えていなければなりません
中級者チーム
以下の項目は経験豊富なチームで一般的に見られるもので、チームがサービスの効率的な管理に積極的に取り組んでいることを示しています。
ビジネス リーダーとともに、
SRE プロジェクトの実績と効果を定期的に評価
していること
ビジネス リーダーとともに、
SLI と SLO を定期的に見直している
こと
全体として少量の苦役があること(負担の軽いオンコール以上のものが 50 % 未満)。信頼性を考慮に入れた構成変更アプローチをチームが確立していること。SRE が単に
オンコールの範囲を広げたりサービスを増やしたりするだけでなく、自らの影響力を大きくする
ためのプランを確立していること
カナリア リリース失敗時のロールバック メカニズム
を用意していること(自動化も可)
ロールプレイングと何らかの自動システムを組み合わせた、
インシデント管理の定期的なテスト
を用意していること
SLO 違反発生時のエスカレーション ポリシーを規定していること。たとえばリリース プロセスの凍結 / 凍結解除など(SLO 違反の可能性については、
こちら
の記事をご覧ください)
開発と SRE が共有する
障害報告書とアクション アイテムを定期的に見直している
こと
本番以外の環境を使用した
ディザスタ リカバリ テストを定期的に行っている
こと
チームが需要と能力の関係を計測し、
能力が需要に追いつかなくなりそうなときに積極的に予告している
こと
開発チームと共同で
SRE チームが長期計画(年次ロードマップ)を作っている
こと
上級者チーム
次の項目は特にスキルの高いチームに見られるものですが、複数または全社の SRE チームがより広範な憲章を共有することで実現できる場合もあります。
少なくとも SRE チーム内の数名が、単なる運用や障害対策の枠組みを越えて、
ビジネスの何らかの側面に大きなプラスの影響を与えている
こと
プロジェクトの仕事を水平的に実施でき、実際によく水平的に実施されること。
サービスの改善に時間がかかったり、かえって悪化させたり
せずに、
多くのサービスをまとめて改善できる
こと
ほとんどのサービス アラートが
SLO バーン レートに基づいている
こと
自動化されたディザスタ リカバリ テストが用意されており
、プラスの効果が計測されていること
以下は、望ましい SRE の特長でありながら、実際にはほとんどの企業が実現できていないものです。
SRE のオンコールが年中無休の 24 時間体制ではないこと。米国と欧州というように SRE チームが 2 つの地域に分散されており、どちらも副次的な扱いになっていないこと
SRE と開発チームが目標を共有し、SVP 以上の幹部からの指揮命令系統が別々になっていること(利害衝突を防ぐことに役立ちます)
次に何をすべきか
以上のチェック リストに目を通したら、次のステップは、その内容が自社のニーズに合うかどうかを考えることです。
まだ SRE チームが存在せず、初級者チーム向けチェック リストの多くが未達なら、冒頭で紹介した
SRE ワークブック
を最初の章から順に読むことを強くお勧めします。自社が Google Cloud Platform(GCP)のユーザーで、
CRE の関与
を希望される場合は、アカウント マネージャーに連絡してこのプログラムに応募してください。ただし、SRE はさまざまなインフラストラクチャに適用できるメソドロジーであり、この一連のエンジニアリング手法を用いるうえで Google Cloud の使用は前提条件でないということを、はっきりさせておきたいと思います。
また、人材採用の停滞などを解決するベスト プラクティスを共有するため、既存のカンファレンスに出席したり、他社とのサミットを組織したりすることもお勧めします。
変化の激しさゆえに、上級者チーム向けチェック リストの達成に苦労しているチームもよく見かけます。システム変更や人事異動が上達の遅延要因になるかもしれません。チームが初級者レベルの段階に逆戻りするなどの問題を避けるため、Google の SRE リーダーたちは、6 か月ごとにそれぞれのチームの主要指標をチェックしています。この場合、一部の項目はすでに標準になっているので、チェック範囲は上記のチェック リストよりも狭くなっています。
すでにお気づきかもしれませんが、本稿の中心的な問いに答えるということは、チームの影響力と健全性、そして何よりも大切なことですが、実際の仕事のしかたを評価するということです。結局のところ、
最初の SRE 本で書いた
ように、自動化できないプロセスやソリューションを作っているなら、システムを維持するために人員を確保し続けなければなりません。人間がいなければ仕事がまわらないのであれば、人間の血と汗と涙をマシンに注ぎ込んでください。
だからこそ、あなたはもう SRE チームを設けているのでしょう。そのチームは効果的ですか? スケーラブルですか? 人々は満足していますか? SRE チームのスキルがどの程度であっても、チームの仕事と会社のサービスにはまだまだ発展、成長、強化の余地があるはずです。SRE チームの立ち上げ方をもっと詳しく学びたい方は
こちら
を参照してください。
本稿に力を貸してくれた多くの人々、特に Adrian Hilton、Alec Warner、David Ferguson、Eric Harvieux、Matt Brown、Myk Taylor、Stephen Thorne、Todd Underwood、Vivek Rau の各氏に感謝いたします。
- By Gustavo Franco, Customer Reliability Engineer
Stackdriver IRM のリリースと新たなパートナーシップ ―― インフラストラクチャのさらなる信頼性向上を目指して
2018年10月18日木曜日
※この投稿は米国時間 2018 年 10 月 11 日に Google Cloud blog に
投稿
されたものの抄訳です。
アプリケーションをいつも安心して使えるようにすることは、ソフトウェアを提供するすべての組織が解決しなければならない課題です。私たち Google が、
SRE(Site Reliability Engineering)
と呼ばれる方法論を生み出して実践しているのも、それが理由です。数十億のユーザーが安心して使えるサービスを私たちが構築し運用できるのは、SRE のプラクティスに従っているからです。
Google には社内外のサービスをサポートする 2,500 人ほどの SRE 担当者がいます。
SRE の原則
は、組織のユーザーにとって適切なサービス レベルの指標を確立するための拠りどころとなり、発生した問題を検出し修復するにあたって規範的な手順を提供します。また SRE の原則は、非難を伴わない事後分析などを通じて、継続的な改善の文化も生み出します。こうした SRE については、担当者の雇用方法を知りたい、SRE の原則を実践に移すツールを使いたい、より良い結果を達成したいといった問い合わせが多くの企業から寄せられています。
モニタリング、APM(Application Performance Management)、ロギングの各サービスからなる
Google Stackdriver
で私たちが目指しているのは、長年築き上げてきた、システムの信頼性に関するベスト プラクティスに基づいて、完成された管理ツールセットを提供することです。これらの Stackdriver ツールは、SRE の原則と、信頼性および可用性のさらなる向上という目標をベースに生み出されたものです。
私たちはこのたび、Google Cloud Platform(GCP)のもとで Stackdriver IRM(Incident Response and Management)のアルファ提供を開始し、システムのオブザーバビリティ(observabiliity; 可観測性)を大きく引き上げました。Stackdriver IRM は、インシデントの精査、理解、緩和、および修復に必要なツールを提供します。Stackdriver IRM のアルファ プログラムに参加をご希望の方は、
こちら
からサインアップしてください。
また、モニタリングおよび信頼性ツールセットの構築に有用な新しい統合サービスを提供するべく、Blue Medora や Grafana Labs と協力して作業を進めています。
システムの信頼性に光を当てる Stackdriver IRM
私たちがモニタリング ツールを進化させながら考えていることは、ユーザーができる限り簡単に SRE を導入して前に進めるようにしたいということです。組織に SRE を根づかせることは容易ではありませんが、Stackdriver IRM のようなツールは、SRE や、IT サービスを通じてユーザー エクスペリエンスを高める手法からインスピレーションを得ています。
Stackdriver IRM は、基準に違反している指標や、アラートの状態を可視化します。Stackdriver IRM には、アラート ポリシー ドキュメントと、典型的なケースを処理する方法を示したガイダンスが組み込まれています。またインシデントと環境の状況に基づき、精査プロセスを加速させる重要情報にスポットライトを当てます。
Stackdriver IRM で得られるのは次のとおりです。
包括的なデータ収集とアナリティクスによるインシデントの徹底的なライフサイクル管理
SRE の経験から生まれた緊急応答プロトコルに基づく効率的な多応答者インシデント管理のための体系化されたプロセス
知見を引き出し、重要情報にスポットライトを当てるとともに、精査プロセスを迅速化し、障害から復旧にかかる時間を短縮する最新 Stackdriver データの自動相関化
状況を重視し、事後分析生成プロセスを向上させるために頻繁に使われる非公式な慣習的手順(問題点の追跡手順など)の構造化
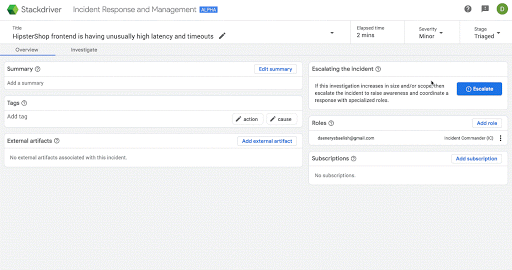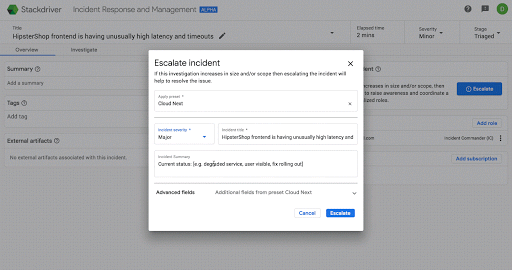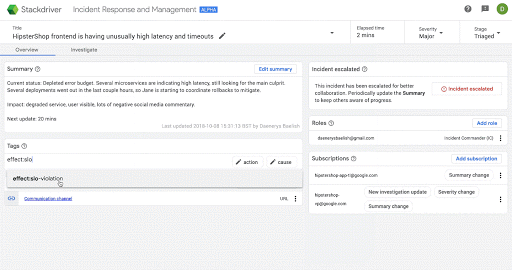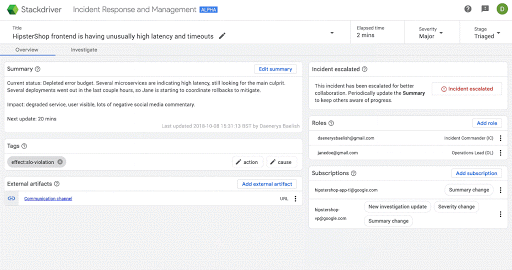
次の画面は、Stackdriver IRM においてインシデントに関する認識を段階的に深めていく場合の具体的な例です。
可視性や柔軟性の向上を支援する新しいパートナー
オープン クラウドの一部になるということは、ベンダーを選ばないということです。Stackdriver は柔軟で拡張性の高いプラットフォームであり、私たちはパートナーと協力しながらモニタリング データの可視化を支援することに取り組んでいます。
分散インフラストラクチャにおいてサイトの信頼性と可用性を担当する IT チームは、問題の検出やトリアージの際の徹底した分析のために、広範なシグナルを収集する必要があります。しかし、インフラストラクチャにおけるパフォーマンス障害の原因はいつも自明だとは限らず、問題の徴候を知らせるシグナルはインフラストラクチャ、OS、ネットワーキング、サービス、アプリケーション レイヤなどさまざまな場所に散らばっています。
この難題を解決するべく、私たちは、クラウド環境やインフラストラクチャ、ネットワーク機器、データベース、ストレージ環境、基幹アプリケーションなどを含む
広範なリソース
の包括的な可観測機能を提供する
Blue Medora
と共同で作業を行っています。つまり、Stackdriver のモニタリング機能をより多くのリソースやワークロードに拡張し、状況を包括的に把握できるようにするわけです。Blue Medora のプラットフォームは、実行中のワークロードの下に隠れたスタックの幅広いオブザーバビリティを提供します。なお、この統合機能は現時点ではアルファ リリースです。関心のある方は、
こちらのフォーム
に必要事項を入力してお送りください。
また、より強力な可視化オプションを Stackdriver ユーザーに提供するため、私たちは
Grafana Labs
ともパートナーシップを結びました。Grafana の時系列データ可視化ソリューションは市場で人気が高く、オブザーバビリティダッシュボードとモニタリング データ アナリティクス(潜在的な問題、根本原因、顕著な傾向について、その可視化、分析、特定を行う)のためのオープンフレームワークを基盤としています。このパートナーシップにより、Stackdriver Monitoring 用の可視化ツールとして Grafana を使用できるようになります。Stackdriver プラットフォームによって収集、ホスティングされているサービスのモニタリング データを可視化するための選択肢が広がるわけです。Grafana は
こちら
からダウンロードでき、そのユーザー インターフェースは次のとおりです。
今後に向けて
スピード、セキュリティ、安全性を確保するためには、このレベルの自動化がすべてのデベロッパーとオペレーターに対して与えられるべきです。私たちは、SRE / 運用チームによるアプリケーションの確実な運用をより効率化するエコシステムの拡張を計画しています。手間のかかる作業を自動化したいとお考えなら、今すぐ Stackdriver IRM のアルファ プログラムに
サインアップ
しましょう。
こちら
では Stackdriver について詳しく学ぶこともできます。今後の展開にご期待ください。
- Post by Melody Meckfessel, VP of Engineering
クラウド時代のトラブルシューティング : 解決に役立つプロバイダーとのコミュニケーション(前編)
2018年7月6日金曜日
編集部注 :
今回の記事は、数年前に
SRE(サイト信頼性エンジニアリング)の本
を出した(本当に!)Google エキスパート チームが執筆してくれました。実際に手を動かして学ぶ同書の姉妹書『
The Site Reliability Workbook
』も発売に向けて準備が進んでいるようです。ここでは、多くの IT チームにとって重要な SRE の一分野である、クラウド コンピューティング時代のトラブルシューティングについて取り上げます。今回は 2 回連載の前編です。本稿を読み終えたら、クラウド プロバイダーとのコミュニケーション方法をテーマにした
後編
もぜひご覧ください。
技術的な問題を効果的に解決するためには、運や経験に頼るのではなく、系統的なアプローチが必要です。
書籍『Site Reliability Engineering』の中
でも述べたように、トラブルシューティングは学習できるスキルです。
しかしながら、クラウド インフラストラクチャ上でシステムやサービスを実行するようになって、あなたや運用チームはどう変わりましたか? ウェブサイトやアプリがどこで実行されているかにかかわらず、サイトが落ちたときに呼び出しがかかり、問題を解決し、疑問を解明しなければならないというプレッシャーにさらされるのは、依然としてあなたではないですか?
クラウドは、IT チームが旧来のシステムから移行しつつある新しい仕事の形です。システムがオンプレミスに存在したときは、システムのあらゆる側面を見てコントロールすることができました。しかし、オフサイトにあるクラウド ベースのインフラストラクチャに依拠するようになると、見ることで理解できる部分は限られてきます。それは、システムやプロセスがいかに一流で、あなたがいかに優秀なトラブルシューターであっても同じです。通常、クラウド プロバイダー システムの中身は見られる部分が限られています。
難しいのは純粋なデバッグだけではありません。クラウド プロバイダーとうまくコミュニケーションを取る必要があるのです。プロバイダーのサポート プロセスやエンジニアと関わりを持ち、問題がどこにあるかを協力して突き止め、できる限り早く問題を解決しなければなりません。これは、IT チームが新しいスキルを獲得し、クラウド ベースの技術モデルに適応するための格好のチャンスでもあります。
正しいクラウド トラブルシューティングは間違いなく可能です。重要なのは、クラウド プロバイダーを選ぶときに、彼らが問題発生時にどのように協力してくれるかをきちんと見極めることです。実際にプロバイダーと付き合い始めると、問題の伝え方や解決までのスピードに関して、あなたが思う以上にあなたは大きな役割を果たします。
私たちは、SRE モデルのアクショナブルな改善をヒントに、クラウド プロバイダーとの協力のもとで行う、より効果的で効率的なトラブルシューティングを提案したいと思います(トラブルシューティング プロセスを通じたクラウド プロバイダーとのコミュニケーションの方法については
後編
をご覧ください)。
クラウド プロバイダーのサポート ワークフローを把握する
問題は避けがたく発生します。したがって、ここでの目標は、問題が実際に発生したときに、プロバイダーに対して情報を適切に提供する最善の方法を見つけ出すことです。インフラストラクチャ向けにおそらく複数のクラウド プロバイダーを利用していることを考慮すると、まずはここから着手するのがうまいやり方です。通常、クラウド プロバイダーのサポート担当とのやり取りは、マイグレーションに関連した質疑応答から始まり、本番環境のインテグレーション、本番環境で生じた問題のトラブルシューティングへと進んでいきます。
頭に入れておきたいのは、顧客とのやり取りについての考え方がプロバイダーごとに異なるということです。たとえば、顧客に大きな自由度を与える代わりに直接的なサポートをあまり提供しないプロバイダーもあります。そのようなプロバイダーは、顧客自身が Stack Overflow などのオンラインフォーラムから答えを見つけるべきだと考えています。逆に、顧客と密接な関係を持ち、協力してトラブルシューティングにあたることを強調するプロバイダーもあります。
トラフィックをクラウドで本格的に処理するつもりなら、必ず済ませておかなければならない宿題があります。クラウド プロバイダーの営業担当者、プロジェクト マネージャー、サポート エンジニアと話をすることです。そして、プロバイダーがサポートにどのように取り組んでいるか、感触をつかんでおきましょう。次のような質問をしてみてください。
サポートに対する典型的なイシュー レポートのライフサイクルはどうなっているか?
問題が複雑もしくは重大な場合の社内のエスカレーション プロセスはどうなっているか?
<サービス名>の社内サービス レベル目標(SLO)はあるか? ある場合、その内容はどうなっているか?
プレミアム サポートとしてどのようなタイプのものを利用できるのか?
このステップは、クラウド プロバイダーの巨大なブラックボックスが関係している問題のトラブルシューティングにまつわる不満を軽減するうえで不可欠です。
クラウド プロバイダーのサポート担当との効率的なコミュニケーション
プロバイダーのサポート ワークフローがどのようなものなのか、その感じがつかめれば最良の情報伝達方法がわかります。その問題についてなぜ言及するのかを含め、プロバイダーのサポート チームに完璧なイシュー レポートを送るときに役立つベスト プラクティスがあります。報告の 80 % で役に立つ詳細情報の 20 % を知らせるという 80/20 ルールに従うのです。イシュー トラッカー、ユーザー グループ、フォーラムなどにバグ レポートを送る際にも同じ原則が当てはまります。
クラウド プロバイダーとのコミュニケーションを図るにあたっては、その方針に明確性が含まれていなければなりません。適切なレベルの技術的詳細を示し、望むことを明確に伝えることが大切です。
基本情報の提供
常識だと思われるかもしれませんが、イシュー レポートに基本情報を含めることはきわめて重要です。これらの詳細を書き漏らすと、解決の遅れや不満の残る対応の原因になります。
4 つの必須情報
効果的なトラブルシューティングは、
時刻
、
製品
、
位置
、
具体的な識別子
から始まります。
1. 時刻
イシュー レポートへの時刻の記載例を見てみましょう。
太平洋夏時間 2017 年 9 月 8 日 15 時 13 分から 5 分後まで~が観察されました
2017 年 9 月 10 日以降、間欠的に 2~5 回観察されたことですが、~
太平洋夏時間 2017 年 9 月 8 日 15 時 13 分以降ずっと~
太平洋夏時間 2017 年 9 月 8 日 15 時 13 分から同 22 時 22 分まで~
発生時刻と期間を具体的に示せば、クラウド プロバイダーのサポート チームはその期間の時系列モニタリングに注力できます。問題がまだ続いているのか、過去に発生しただけなのかを明確にしましょう。問題が収まっているのなら、それを明確にし、可能なら終期をサポート チームに伝えてください。
また、タイム ゾーンを忘れないようにしましょう。曖昧さがなく、ソートしやすい
ISO 8601 形式
を使うことをお勧めします。相対的な方式で時刻を記載してしまうと、相手は時系列モニタリング ツールに時刻を入力するために、ローカル タイムを絶対形式に変換する必要が出てきます。この変換作業はミスの元であり、コストもかかります。たとえば、「昨日のもっと早い時間」に何かが起きたというようなメールを送ると、相手はメール ヘッダを探し、頭の中で発生日時を計算しなければなりません。すると、
認知的負荷
が発生し、技術的な問題の解決に向けられる精神的エネルギーが減ってしまいます。
ある期間に問題が間欠的に起きた場合は、最初に観察されたときか、問題が確実に発生していなかった過去の時点を記載し、観察された頻度を入れ、具体例を 1~2 件示すとよいでしょう。
避けるべきアンチパターンを挙げておきます。
今日早く : 十分に特定できていません。
昨日 : 連絡を受け取った側が暗黙の日付を明らかにしなければなりません。特に日付変更線をまたがる場合は曖昧になります。
9/8 : 曖昧です。米国では 9 月、他の地域では 8 月だと解釈される恐れがあります。明確にするために
ISO 8601 形式
を使いましょう。
2. 製品
イシュー レポートでは使用している製品をできる限り具体的に示し、必要に応じてバージョン情報も追加してください。たとえば、次のような表現では具体性が足りず、診断に役立つコンポーネントやログを特定できません。
REST API がエラーを返しました。
データ マイニングのクエリ インターフェースがハングアップしています。
理想を言えば、特定の API や URL を指定するか、スクリーンショットを添付したいところです。問題が起きたのが特定のコンポーネントやツールであれば(たとえば CLI や Terraform)、それを明確にしましょう。複数の製品が関与している場合は、一つひとつを明確にします。そして、観察した動作と、こうなるはずだと思っていた動作を記述します。
以下はアンチパターンです。
仮想マシンを作成できません。仮想マシンをどのようにして作ろうとしたのかがはっきりしません。エラー モードがどうなっているのかもわかりません。
CLI コマンドがエラーを返します。
エラーの内容を具体的に書き、コマンドの構文を明示して、他の人も実行できるようにしましょう。
より良い書き方 : “mktool create my-instance --zone us-central1” を実行したところ、次のようなエラー メッセージが返ってきました。
3. 位置
クラウド プロバイダーはリージョンやゾーン全体に変更をロールアウトすることが多いので、リージョンとゾーンを明確にすることは重要です。リージョンやゾーンの情報は、クラウドで稼働するソフトウェアのバージョン番号の代わりになります。
イシュー レポートへの位置情報の記載例を見てみましょう。
us-east1 において~
リージョン eu-west-1 と eu-west-3 で試したところ~
位置情報があれば、クラウド プロバイダーのサポート チームはその場所でロールアウトが行われているかどうかを確かめたり、位置情報から社内リリース ID を割り出して社内用のバグ レポートで報告したりすることができます。
4. 具体的な識別子
多くのトラブルシューティング ツールにはプロジェクトの識別子が含まれています。エラーが発生したのは複数のプロジェクトなのか、それとも特定のプロジェクトだけなのかをはっきりさせましょう。
具体的な識別子とは、たとえば次のようなものです。
プロジェクト 123412341234 または my-project-id で~
複数のプロジェクト(123412341234 が含まれます)にわたって~
社内のゲートウェイ 56.56.56.56 からクラウドの対外 IP 218.239.8.9 に接続するとき~
IP アドレスは曖昧さのない識別子の 1 つですが、イシュー レポートで使用する場合は追加の詳細情報が必要です。IP アドレスを指定するときは、どのように使われているかも書くようにしましょう。たとえば、その IP が VM インスタンスに接続されているのか、ロード バランサやカスタム ルートに接続されているのか、あるいは API エンドポイントなのかといったことを明確にしてください。IP アドレスがクラウド プラットフォームの一部でなければ(たとえば、ホーム インターネット、VPN エンドポイント、外部モニタリング システムなど)、その情報も追加します。192.168.0.1 は世界中で無数に使われていることを忘れないようにしましょう。
以下はアンチパターンです。
弊社インスタンスの 1 つにつながりません : 曖昧すぎます。
インターネットから接続できません : 曖昧すぎます。
5W1H
(ジャーナリズムなどでよく使われています)などのモデルも、イシュー レポートを構造化するうえで役に立ちます。
問題発生の影響と回答に対する要望の明確化
クラウド プロバイダーに対するイシュー レポートには、問題の発生がビジネスに及ぼす影響や、希望する回答期限なども含めるようにします。
期待する優先順位
クラウド プロバイダーは、イシュー レポートの回覧や緊急度の判定の際に、顧客が指定した優先順位を使います。優先順位は対処のスピードを左右し、緊急だと判断されればオンコール担当者が呼び出されることもあります。
適切な優先順位以外に効果的なのが、どのような影響があるかの説明です。P1 を選んだ理由を明確にして、間違った思い込みをされないようにしてください。
優先順位はビジネスへの影響度を考慮して決めましょう。優先順位の厳密な定義を有しているクラウド プロバイダーもありますが(たとえば P1 は全面的なダウン)、そうした定義のせいでビジネス クリティカルな問題の解決が遅れることは避けなければなりません。問題が解決されない場合に予想される影響や最悪のシナリオをレポートに含めるようにしましょう。たとえば、次の 2 つの例は実質的に P1 に相当します。
バックログが増えてきています。現時点での影響はまだ小さいですが、12 時間以内に解決されなければ、システムは実質的にダウンした状態になります。
重要なモニタリング コンポーネントがエラーを起こしています。現時点では影響はありませんが、監視できない個所が生じており、それによってユーザーにもわかる機能停止が起きる恐れがあります。
希望する回答期限
回答期限に関して具体的なニーズがある場合は、それを明確に示しましょう。たとえば、「シフトが終了する午後 5 時までに回答をお願いします」とレポートに記します。緊急時の連絡に関する SLO が社内で規定されている場合は、その SLO を満たす形で回答期限を指定します。多くのクラウド プロバイダーは 24 時間 365 日体制のサポートを提供していますが、そうでない場合や担当者のタイム ゾーンがずれている場合は、タイム ゾーン固有のニーズをプロバイダーに伝えましょう。
これらの詳細情報をイシュー レポートに含めれば、あなたの時間を無駄にせず、プロバイダーの修復作業全体をスピードアップさせる効果があるはずです。実際のトラブルシューティング プロセスにおいてクラウド プロバイダーとどのようなコミュニケーションを取るべきかについては、
後編
をご覧ください。
関連コンテンツ
SRE vs. DevOps
SRE の教訓 : Google におけるインシデント管理とは
エスカレーション ポリシーの適用 : CRE が現場で学んだこと
Special thanks to Ralph Pearson, J.C. van Winkel, John Lowry, Dermot Duffy and Dave Rensin
* この投稿は米国時間 5 月 31 日、Luke Stone と Jian Ma によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Luke Stone and Jian Ma
エスカレーション ポリシーの適用 : CRE が現場で学んだこと
2018年2月26日月曜日
過去の投稿では、
サービス レベル目標(SLO)違反のエスカレーション方法
を示した明確なポリシー文書を作成することの重要性と、Google の SRE チームによる
実際の文書例
について説明しました。このテーマの最終回となる今回は、エスカレーション ポリシーを適用する仮定のシナリオをいくつか用意し、エッジ ケースとして紹介します。
以下に示すシナリオは、すべてスリー ナイン(99.9 %)の可用性の SLO が設定されたサービスのもので、エラー バジェットの半分はバックグラウンドのエラーで消費されることを想定しています。つまり、エラー バジェットは 0.1 % で、0.05 % のエラーで稼働している状態は「正常」となります。
最初に、ポリシーの基準値をおさらいしておきます。
基準値 1 : SLO が影響を受ける可能性があると SRE に通知される。
基準値 2 : SLO を保つには支援が必要だと SRE が判断し、開発者にエスカレーションする。
基準値 3 : 30 日間のエラー バジェットが消費されたものの根本的原因が判明していない。SRE はリリースを停止し、さらなるサポートを開発チームに要請する。
基準値 4 : 90 日間のエラー バジェットが消費されたものの根本的原因が判明していない。SRE は、より多くの開発時間を信頼性向上に充ててもらうよう、幹部にエスカレーションする。
上記を念頭に、SLO 違反を詳しく掘り下げてみましょう。
シナリオ 1 : 短時間だが重大な障害が根本的原因となり、すぐに依存関係の問題が発生した
状況 : 重要な依存関係を誤ってプッシュしてしまい、その依存関係を担当するチームが当該リリースをロールバックする間、サービスの 50 % が 1 時間停止しました。ロールバックが完了するとエラー率は以前のレベルに戻り、チームは根本的原因となる要因を特定して元に戻します。依存関係を担当するチームが事後分析を作成しますが、再発防止に向けてやるべきことについては、一部サービスを担当する SRE が作成に協力します。
エラー バジェット : 可用性がスリー ナインのサービスの場合、今回の障害だけで 30 日間のエラー バジェットのうち 70 % を消費したことになります。7 日間のエラー バジェットは上回っており、バックグラウンドのエラーも考慮すると 30 日間のエラー バジェットも超えたことになります。
エスカレーション : 本番への影響に対処するよう SRE に通知されます(基準値 1)。この一連の問題(設定ミスまたはバイナリ プッシュ)が発生することはまれであるか、問題は適切に収拾したと SRE が判断した場合、サービスは SLO の規定内に戻され、ポリシーとしては他にエスカレーションする必要はないと判断されます。これは意図的なものです。ポリシーでは開発速度をこれ以上ないほど重視しており、単に 30 日間のエラー バジェットを消費したからといってリリースを止めてしまうのはポリシーに反するのです。
問題が何度も再発する場合(たとえば 2 週間連続で発生し、四半期分のエラー バジェットの大半を消費するような場合)や、再発の可能性があるとの判断が下った場合は、基準値 2 または 3 へとエスカレーションします。
シナリオ 2 : 短時間だが重大な障害が発生し、根本的原因がはっきりしない
状況 : 1 時間にわたってサービスが 50 % 停止し、その原因はわかっていません。
エラー バジェット : シナリオ 1 と同様、7 日間および 30 日間のエラー バジェットを超えました。
エスカレーション : 本番環境への影響に対処するよう SRE に通知がなされ(基準値 1)、それを受け取った SRE は迅速に開発チームにエスカレーションします。SRE は、問題をより明確に可視化するために新たな測定基準を要求し、フォールバック アラートをインストールすることもあります。また、SRE とオンコールの開発担当者は翌週に向け、問題の調査を優先します(基準値 2)。
引き続き根本的原因がはっきりしない場合、SRE は障害の 1 週目以降、30 日間の SLO 測定枠が過ぎ去るまで機能リリースを停止します。他のプロジェクトを進めている SRE と開発チーム担当者がさらに招集され、デバッグや障害の再現を試みます。サービスが SLO 規定内に収まるか根本的原因が見つかるまでは、それが彼らの最優先事項となります。
調査が進むと、SRE と開発チームは事態収拾や回避策、多重防御に向けた取り組みを始めす。理想としては、今後同様の障害が発生したとしても、根本的原因を見つけるのが今回ほど難しくなく、今回ほどの影響も出ることはないと SRE が自信を持って言えるようにしておきましょう。そうなれば、根本的原因がまだわかっていなくても、リリースのプッシュ配信を再開できることになります。
シナリオ 3 : 誤った根本的原因により、エラー バジェットが徐々に消費される
状況 : ある特定の時刻 T に、以前のバージョンにはなかったバグが本番環境に入り込み、サービスが 0.15 % のエラーを出すようになりました。数週間経っても、SRE も開発者もその根本的原因がわかりません。さまざまな修正を試みるものの、影響は収まりません。
エラー バジェット : このまま解決しなければ、1 か月の間に 1.5 か月分のエラー バジェットを消費することになります。
エスカレーション : 発生時刻 T から約 5 日後、7 日間のエラー バジェットが消費されたため、オンコールの SRE 担当者にチケットが送信されます。SRE は基準値 2 を発動し、時刻 T から約 7 日後に開発チームへとエスカレーションします。CPU 使用率の増加と関連があることから、SRE とオンコール担当の開発者はエラーの根本的原因がパフォーマンスのデグレードにあると推測します。オンコールの開発者がシンプルな最適化を見つけ出して送信し、時刻 T から 16 日後に通常のリリース手順の一部として本番環境に提供します。その修正で問題が解決されるわけではないのですが、今となっては、影響を受けたサービスに対して日々のコード リリースを 2 週間分ロールバックするのも現実的ではありません。
時刻 T から 20 日後、サービスが 30 日間のエラー バジェットを超えたため、基準値 3 が発動されます。SRE はリリースを停止し、開発者にさらに真摯に対応してもらうべくエスカレーションします。開発チーム側も、開発者 2 人と SRE 1 人による担当グループを設けることに同意します。担当グループは問題の根本的原因を見つけ出して修復することを最優先とします。
コードの変更と不具合との間に適切な関連性を見いだせないため、担当グループは詳細にパフォーマンスを分析し、ボトルネックを順に排除します。修正はすべて現在の本番リリース上で週 1 回のパッチとして集約されます。サービスは顕著に効率化されますが、それでもエラー率は上昇します。
時刻 T から 60 日後、サービスが 90 日間のエラー バジェットを消費し、基準値 4 が発動されます。SRE は幹部にエスカレーションし、信頼性が欠如している状況が継続していることに対して相当な開発作業が必要だと訴えます。開発チームは問題を深く掘り下げ、アーキテクチャに不具合を発見し、最終的にサーバーとクライアント間におけるエッジケース インタラクションの停止機能を再実装します。エラー率は以前の状態に戻り、リリースを再度開始した段階で停止機能をバッチでロールアウトします。
シナリオ 4 : 繰り返し発生する、一時的なサービス レベル指標(SLI)の逸脱
状況 : 日々または週ごとのバイナリ リリースにより、そのつど一時的なエラーが急増しています。
エラー バジェット : エラーが長期的に SLO を脅かすことがない場合、SRE は責任を持ってアラートを適切に調整しておく必要があります。そこで、このシナリオではエラーが急増しても、SLO が数時間にわたって脅かされることはないと仮定します。
エスカレーション : SLO を基にしたアラートによってまず SRE に通知され、ゆっくりとエラー バジェットが消費される場合と同様のエスカレーション手法が採られます。ここでは、リリースとリリースとの間に SLI が正常に戻ったからといって、それで問題が「解決された」と捉えないようにしてください。というのも、サービスを SLO の規定内に収めるための基準はそれより高く設定されているためです。SRE は、エラー バジェットの消費が長くなったり速くなったりしたときにページャーを鳴らすようアラートを調整してもいいですし、継続的に実施しているサービスの信頼性向上に向けた作業の一環として問題を調査してもいいかもしれません。
まとめ
どんなエスカレーション ポリシーにおいても、仮定のシナリオで「軍事演習」を行い、予期しないエッジ ケースがないか、またポリシーの言葉が明確になっているかを確認しておきましょう。ポリシーの下書きをいろんな人に回覧し、そこで上がってきた懸念事項を付録に記載してください。ただし、あるインフレクション ポイント(変曲点)を正当化するためにポリシーそのものを乱さないようにしましょう。提案したポリシーに対して同僚から異論があった場合は、さらに議論を進める心構えでいてください。
ここで紹介したポリシーは単なる一例にすぎません。高い可用性を実現しようとする実際の SRE チームは、大きく異なるエスカレーション ポリシーを作成している可能性が高いことを忘れないでください。
* この投稿は米国時間 2 月 8 日、Site Reliability Engineer の Will Tipton と、Customer Reliability Engineer の Alex Bramley によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Will Tipton, Site Reliability Engineer and Alex Bramley, Customer Reliability Engineer
SLO のエスカレーション ポリシー : CRE が現場で学んだこと
2018年2月6日火曜日
前回のブログ記事
では、信頼性と機能開発の間で生じる技術的な苦労や、サービス レベル目標(SLO)が満たされていないサービスに対して、企業はいつどうやってエンジニアの時間を信頼性向上に費やすよう決断すべきかについてお話ししました。今回は、SLO のエスカレーション ポリシー(一部編集済み)と、それに関連する Google の SRE チームによる論理的根拠を解説し、開発速度の迅速さを保つために SRE と開発の各チームがどこに妥協点を置いているのかを紹介します。
この SRE チームでは、サービス スタックのさまざまな領域に注力する大規模な開発チームと連携しています。そのスタックには、トラフィックの多いサービスが約 10 件、比較的小規模なサービスが 10 数件含まれており、すべて SRE チームがサポートしています。チームは欧州と米国に分かれており、それぞれの地域で日中オンコール担当となるように 12 時間ごとのローテーションを組んでいます。
サポート対象のサービスには、求められるユーザー エクスペリエンスを示すざっくりとしたトップ レベルの SLO と、スタックのコンポーネントにおける可用性の要件を示す詳細な SLO が設定されています。重要なこととして、SRE チームは呼び出しがかかった際に、それぞれの SLO の粒度に応じて開発チームに担当を引き継ぐことが可能であり、SLO に対する「サポートの取り消し」を安価かつ迅速にできるようになっています。
アラートの設定については、サービスが 1 時間の間に 9 時間分のエラー バジェットを消費するとページャーが鳴るようになっています。また、前週に 1 週間分のエラー バジェットを消費した場合はチケットが発行されます。
なお、ここでのエスカレーション ポリシーは単なる一例だという点に留意してください。しかも、もし 99.99 % 以上の可用性を目標としたサービスを SRE チームがサポートしている場合は、あまり良い例ではないと考えられます。この Google チームが担当している業界は非常に競争が激しく動きも速いため、高可用性の維持よりも、機能のイテレーション スピードや市場投入までの時間を重要視しているのです。
エスカレーション ポリシーの目的
エスカレーション ポリシーの詳細に入る前に、以下の点を検討する必要があります。
まず、エスカレーション ポリシーは何かを完全に禁止するためのものではありません。直面した状況に適切に対応するための判断が SRE には求められるため、特定の行動を取るにあたっての妥当な基準値を設定し、想定される対応の幅を縮小して一貫した基準内で対応できるようにすることが、エスカレーション ポリシーの目的となります。ポリシーにはさまざまな基準値が設定されており、その基準値を超えたときは、SLO 違反に対処するべくエンジニアの労力を注ぎ込みます。
また SRE は、インシデントが解決したと宣言する前に、一連の問題を修復するよう注力しなくてはなりません。これは、問題そのものを修復するよりも大変なことです。
たとえば、悪いフラグ フリップによって深刻な障害が発生した場合、フラグ フリップを取り消すだけではサービスを SLO の規定内に戻せません。そこで SRE は、段階的なロールアウトや、プッシュ失敗時の自動ロールバック、フラグとバイナリのバージョンを結びつける設定へのバージョニングなどにより、今後フラグ フリップによって SLO が脅かされることがないようにする必要があります。
後述するエスカレーション ポリシーの 4 つの基準値において、「サービスを SLO の規定内に戻す」ということは、以下のいずれかの状態を指します。
根本的原因を突き止め、関連する一連の問題を修復する
自動修復によって手作業による介入が必要なくなった
一連の問題が、今後その発生頻度や深刻度によって将来的に SLO を脅かす可能性が極めて低い場合は、とりあえず 1 週間待つ
つまり、手作業で修復する計画を立てたとしても、それだけではサービスを SLO の規定内に戻すには不十分なのです。SLO 違反の根本的原因については、今後違反が発生する可能性や自動修復の有無といった面から理解しておかなくてはなりません。
エスカレーション ポリシーの基準値
基準値 1 : SLO が影響を受ける可能性があると SRE に通知される
SRE は、サポート対象の SLO に危機が迫ると通知されるように警戒態勢を維持します。そして通知が来ると、SRE は調査を行って根本的原因を見つけ出し、それに対処するようにします。また、ロード バランサでトラフィックをリダイレクトしたり、バイナリをロールバックしたり、設定をプッシュしたりと、状況緩和に向けた対応を検討します。
SRE のオンコール担当エンジニアは、SLO への影響を開発チームに通知し、必要に応じて開発チームに最新情報を提供するようにしますが、この段階で開発チームが何らかの対策を講じる必要はありません。
基準値 2 : SRE が開発者にエスカレーションする
次の状況に当てはまるかどうかを判断します。
支援がなければサービスの SLO を保つことは困難だと SRE が判断した
求められるユーザー エクスペリエンスを SLO が表していることを、SRE と開発の両チームとも認めている
すべてに当てはまる場合は、次のような対応が考えられます。
SRE と開発チームのオンコール担当者は根本的原因の修復を優先し、バグを日々更新する
SRE が開発チームのリーダーにエスカレーションし、必要に応じて可視化や追加の支援を要請する
既知の問題に対して継続的に呼び出しがかかるのを避けるため、アラートの基準値を緩める一方で、さらなる不具合に対しては引き続き対策を講じる
サービスが SLO の規定内に戻った場合は、次のことが想定されます。
SRE がアラートの変更を元に戻す
SRE が事後報告を作成することもある
求められるユーザー エクスペリエンスを SLO が正確に表していない場合、SRE、開発チーム、プロダクト チームは SLO を変更もしくは撤回することに同意する
基準値 3 : SRE が機能リリースを一時的に停止させ、信頼性向上に努める
次の状況に当てはまるかどうかを判断します。
最低でも 1 週間は以前の基準値を満たしている
サービスはまだ SLO の規定内に戻っていない
30 日分のエラー バジェットを使い切った
すべてに当てはまる場合は、翌週は次のような対応が考えられます。
根本的原因が判明した不具合を対象に、入念にチェックした修正パッチのみを本番環境にプッシュしてみる
SRE が自分の上司や開発チームのマネージャーにエスカレーションし、緊急でない仕事はすべて後回しにして根本的原因を探し出し修復するように開発メンバーに依頼する
日々の更新を “エスカレーション” のメーリング リストとして発信してみる(幹部を含め、さまざまな人員に障害の情報を知らせるため)
サービスが SLO の規定内に戻った場合は、次のことが想定されます。
通常のバイナリ リリースを再開する
SRE が事後報告を作成する
チーム メンバーが再び通常のプロジェクトを優先することも可能になる
基準値 4 : SRE が幹部にエスカレーションする、またはサポートをやめる
次の状況に当てはまるかどうかを判断します。
最低でも 1 週間は以前の基準値を満たしている
サービスはまだ SLO の規定内に戻っていない
90 日分のエラー バジェットを使い切ったか、機能開発を中止して信頼性の回復に努めることを開発チームが拒否している
すべてに当てはまる場合は、次のような対応が考えられます。
問題解決に専念する人員を増やすため、SRE が幹部にエスカレーションする可能性がある
SRE が SLO やサービスのサポートを取りやめ、関連するアラートをリダイレクトしたり停止したりすることもある
エスカレーションとインシデント レスポンス
SRE は最初のレスポンダーです。開発者にエスカレーションする前に、サービスが SLO の規定内に戻るよう手を尽くすことが SRE には求められます。そのため、7 日分のエラー バジェットが消費されたことを示す 1 週間のチケット アラートにかかわらず、SRE チームに SLO 違反が通知されると基準値 1 を適用します。SRE は開発者へのエスカレーションを、通知を受けてから 1 週間以上先に延ばすべきではありませんが、この段階でのエスカレーションが適切かどうかは、SRE が独自に判断してもかまいません。
SRE によるエスカレーションの際は、可用性の目標値が信頼性と開発速度との望ましいバランスを保っていることを開発者に必ず確認するようにしてください。こうすることで開発者は、新機能をロールバックして可用性の目標値を維持するほうがよいのか、それとも一時的に目標値を緩和して新機能をリリースするほうが望ましいのかを検討できます。
短期間に同様の SLO 違反が繰り返し発生した場合は、何度も考える必要はありません。ただ、こうした状況はさらにエスカレーションが必要だという強力なサインでもあります。開発者が以前合意した可用性の目標値を復帰させることに意欲を見せるまで、開発者に再度そのサービスのページャー担当になってもらうよう主張してもかまいません。開発者が一時的にサービスの信頼性を下げ、ビジネスに重要な機能を提供しつつ信頼性回復に取り組みたい場合も、障害の負担を肩代わりすることができます。
リリースの停止
機能リリースの停止が適切な処置である理由は、主に以下の 3 点です。
一般に、安定した状態で最もエラー バジェットが消費されるのはリリースのプッシュ配信時です。すでにエラー バジェットを使い切っている場合、新たなリリース配信をやめてしまえば、安定した状態でのバジェット消費率が下がり、サービスをより迅速に SLO 規定内に戻すことができます。
リリースの停止により、新たなコード内のバグが原因で今後予期しない SLO 違反が発生するリスクを抑えることができます。根本的原因の修復パッチを新リリースに対してロールアウトするのではなく、現在のリリースに適用すべきなのは、これが理由です。
リリースの停止は制裁処置ではないものの、開発チームにとって非常に気になるリリース速度に直接影響を及ぼします。つまり、SLO 違反と開発速度の低下を結びつけることで、SRE と開発チーム双方のインセンティブにつながるのです。SRE はサービスを SLO の規定内に収めることを望みますが、それに対して開発チームは新機能を迅速に構築したいと考えます。この 2 つは同時に実現するか、双方とも実現しないかのどちらかです。
SLO 違反の根本的原因が特定され修復されたら、SRE は機能リリースの停止を早めに解除することを検討すべきです。SLO が 30 日間の枠内における規定を満たし、今後はサービス低下は起こらないとする開発チームを大目に見ることで、より妥当な信頼性と開発速度のバランスが保てるようになります。
これは、サービスが基準を満たす前に、妥当な時間枠内に収まるだろうと想定して今後のエラー バジェットを効果的に「借り」つつ、リリースを解禁するということです。プッシュ関連の障害がなければ、新機能によってユーザーのサービスに対する評価は向上し、SLO 違反で低下した満足度を回復できるはずです。
SLO 違反の発生前にエラー バジェットの消費率が SLO の基準値に近づいている場合、SRE はリリースの再開をやめることも可能です。こうしたケースでは前借りできるバジェットが少なく、今後 SLO 違反が起こる危険性も高くなり、リリースが許可され続けたときはサービスが SLO の規定内に戻るまでの時間も長くなります。
まとめ
本稿で紹介したエスカレーション ポリシーの例が、サービスの信頼性とビジネス優先度の高い開発速度との妥協点を決めるうえでお役に立てば幸いです。開発速度に対する主な譲歩点としては、SLO に違反したからといって SRE はすぐにリリースを停止せず、SRE との合意に従い SLO が規定内に戻る前に再開のメカニズムを提供することです。
このシリーズの最終回では、今回紹介したポリシーの基準値を仮定シナリオに当てはめてみたいと思います。
* この投稿は米国時間 1 月 19 日、Customer Reliability Engineer である Alex Bramley と、Site Reliability Engineer である Will Tipton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Alex Bramley, Customer Reliability Engineer; Will Tipton, Site Reliability Engineer
SLO 違反への対処 : CRE が現場で学んだこと
2018年1月24日水曜日
サービスの可用性を数値化することの重要性
については、この『
CRE が現場で学んだこと
』シリーズの過去記事で詳しく解説しました。機能開発に注力している開発チームと信頼性に注力している SRE チームとの間で勃発する優先順位に関する戦いを、
サービス レベル目標(SLO)を使って管理する方法
についても、すでに紹介済みです。
SLO がしっかりしていれば
、組織内での摩擦を軽減でき、信頼性を損なうことなく開発スピードを保つことも可能です。しかし、SLO を満たすことができなかった場合はどうすればよいのでしょうか。
今回のブログ記事では、SLO 違反への SRE チームおよび開発チームの対処を示すポリシーの重要性を解説するとともに、ポリシーの構成と内容について提案します。また、Google の SRE チームでの事例とポリシーの施行に至ったシナリオについても、次回以降の記事で検証します。
機能 vs. 信頼性
真空状態の中に
丸い形をした SRE
がいるような理想の世界では、2 つのバイナリ状態の線引きをする役割を SLO が果たします。つまり、エラー バジェットが残っているときに新機能を開発するのか、それともエラー バジェットが残っていないときにサービスの信頼性を改善するのか、という 2 つの線引きです。
真の開発組織であれば、たいていはビジネスの優先順位に従って、この 2 つの領域に対する労力の割き方を変えるものです。SLO の規定内でサービスが稼働していたとしても、積極的に信頼性を向上させることは、障害の将来的なリスクを抑え、効率性を改善し、そしてコスト削減につながります。一方、SLO を満たしていないからといって、すぐに内部での機能開発を完全にやめてしまう組織はほとんどありません。
この領域の主なインフレクション ポイント(変曲点)をポリシーの形で文書化しておくことは、SRE チームと開発チームのパートナーシップにおいて重要なことです。これにより、(すぐにでも起こりうる)SLO 違反の際に自分が何を求められているのかについて、組織全体でだいたい同じ認識を得ることができるはずです。
また、何よりも重要な点として、対応しなかった場合はどんな結果が待ち受けているのかを全員が明確に把握できます。インフレクション ポイントと帰結をどこに持っていくかは、組織や事業の優先度によって異なります。
インフレクション ポイント
誰も責めることのない事後分析
や根本原因の修復を行う文化が組織に根づいている場合、SLO 違反の状態はたいていその事象ごとに異なります。つまり、非公式に言えば「私たちは新たな障害が発生する事業を営んでいる」ということです。
また、違反への対応もそれぞれ異なり、その際に判定を行うのは SRE の仕事となります。ただし、考えられる対応が異なりすぎると結果もばらばらになり、システムを試してみようとする人が出てきたり、開発組織としての疑念が生まれたりします。
エスカレーションのポリシーに関しては、SLO 違反を重要度に応じていくつかのグループに分けておくことをお勧めします。重要度は、時間とともに積み重なっていく影響度によって決まります(つまり、どのくらいの期間にどの程度エラー バジェットを消費したのかということです)。
分類後のグループの境界線は、はっきりと定義しておかなくてはなりません。正当な理由がグループ分けの背景にあると便利ですが、それはメインのポリシーとは別に付録などに記載しておきましょう。ポリシーそのものを明確にするためです。
このグループ分けの境界線と SLO ベースのアラートを、少なくとも一部は結びつけておくとよいでしょう。たとえば、過去 1 時間にエラー バジェット 1 週間分の 10 % を消費するようだったら SRE を呼び出して調査する、といった具合です。
これは、インフレクション ポイントと結果が結びついている 1 つの例です。これにより、非公式に名づけた「誰かを呼び出さなければならないほどエラー バジェットは消費されていない」グループと、「長期的な SLO から外れてしまう前にサービスを今すぐ調査すべき」グループとの線引きができるようになります。次回の記事では、Google の SRE チームのポリシーを紹介しつつ、より具体的な事例を検証します。
SLO 違反がもたらすもの
SLO 違反の行き着く先はポリシーの元となります。これこそが、サービスを SLO の規定内に戻すのに必要な処置を教えてくれるのです。それには根本的原因の解明や、関連する問題の修復、応急軽減処置の自動化、短期的な悪化のリスクを減らすことなどが含まれることになるでしょう。ここでも、あるしきい値に対する結果をどうするかは、ポリシーを定義する組織によって異なります。とはいえ、広範囲ですが当てはまる分野があります。なお、以下のリストはすべてのポリシーで網羅されているわけではありません。
SLO 違反の可能性や実際の違反を通知する
SLO 違反の可能性があったり実際に違反したりしたときに、最も一般的な結果として考えられるのは、監視システムが人間に対して調査や処置が必要だと通知することでしょう。
SRE がサポートしている成熟したサービスの場合、短期間にエラー バジェットが大量に消費されたときにはオンコール担当者のページャーに通知されますし、長い期間にわたってエラー バジェットが上昇しているときはチケットが発行されます。ページャーへの通知と同時にチケットを発行してデバッグの詳細を記録し、深刻な違反をエスカレーションする際は、チケットを情報伝達の場や参照として使うのがよいかもしれません。
また、関連する開発チームにも知らせましょう。このプロセスは手動でもかまいません。SRE チームは違反をフィルターにかけて集約し、意味のあるコンテキストを提供するなど価値を付け加えることも可能です。
ただ理想としては、実際に違反が発生したときには開発チームの上層部の一部にも自動的に通知されるようにしておくべきです(たとえば、どんなチケットでも上層部に CC を入れるなど)。そうすれば上層部はエスカレーションが発生しても驚きませんし、送られてきたチケットに適切な情報が含まれていれば議論に加わることもできます。
開発チームに SLO 違反をエスカレーションする
通知とエスカレーションの主な違いは開発チームに求められる対応です。SLO 違反が深刻な場合、たいていは SRE と開発者が密に協力して根本的原因を突き止め、再発防止策を講じるよう求められます。
エスカレーションは敗北を認めることではありません。SRE としては、開発チームの情報を検討し、解決までの時間が大幅に削減できるとある程度確信した段階で、すぐにエスカレーションするべきです。ただしポリシーには、SLO 違反(またはほぼ違反)が生じたときの猶予時間(エスカレーションせずに粘る時間)の上限を設けておきましょう。
もっとも、エスカレーションしたからといって、違反に対する SRE の仕事が終わったわけではありません。ポリシーにはそれぞれのチームの責任と、原因の調査や修復に費やす開発時間の量の下限を記載しておくべきです。またエスカレーションのレベルとしては、上層部のサポートが必要なレベルから、サービスの信頼性が戻るまで全開発チームの開発時間を使うといったレベルまでを含め、複数記載しておくと便利です。
サービス変更のリスク軽減で、SLO にさらなる影響を与える
エンドユーザーは定義上、SLO を満たしていないサービスには満足しません。そのため、エラー バジェットの消費率を増やすような日々の運用については、減速させるか完全にやめてしまいましょう。これは一般的に、バイナリのリリースや実験の頻度を制限するか、もしくは SLO が再度満たされるまでリリースを完全にやめるという意味です。
これについては、(SRE、開発部門、QA / テスト部門、プロダクト部門、幹部など)関係者全員がポリシーに合意しておくべき部分です。一部の開発チームは、SLO 違反によって開発やリリースのスピードに影響が及ぶことを受け入れがたいと感じるかもしれませんが、リリースをいつどのようにやめるのか、またこのようなことが起こった際にどの程度の人数のエンジニアが信頼回復に向けた仕事に取り組むのかを文書で合意しておくことが主な目的です。
サービスのサポートを取り消す
決められた SLO をどうしても満たすことができず、そのサービスの責任者である開発チームが、信頼性の改善に向けた開発への取り組みに後ろ向きだとしましょう。Google の SRE チームの場合、そうしたケースでは、稼働中のサービスの運用担当から手を引くことができるようになっています。これは、1 回の SLO 違反の結果というよりも、長きにわたって深刻な障害が何度も発生した結果として手を引くということです。
Google ではこれがうまく機能しています。開発の周辺においては、信頼性に対するインセンティブが変わってくるためです。サービスの信頼性を無視する開発チームはその結果を背負うことになる、ということがわかっているのです。
定義上、サービスから SRE のサポートを外すのは最後の手段ですが、そうなる条件を記載しておくことは、口先だけの脅しではなくポリシーとして当然のことです。開発チームがサービスの信頼性なんかどうでもいいと思っているのであれば、SRE が信頼性を気にしなければならない理由はどこにもありません。
まとめ
開発における信頼性と機能の妥協点を考慮し、SLO 違反への対応が信頼性を大きく変えるという事実を検討するにあたって、今回の投稿記事がお役に立てば幸いです。次回の記事では、Google の SRE チームで施行されているエスカレーション ポリシーを示し、同チームのパートナーである開発チームの開発スピードを保てるような選択について紹介します。
* この投稿は米国時間 1 月 3 日、Customer Reliability Engineer である Alex Bramley によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Alex Bramley, Customer Reliability Engineer
事後分析を外部と共有することの意義 : CRE が現場で学んだこと
2017年12月15日金曜日
「サービス停止の要点と分析結果をまとめた
事後分析
を作成することで、システムの信頼性が向上し、サービス担当者も教訓を得られる」ということを、私たち Google の SRE(Site Reliability Engineering)チームはかねてから学んできました。
それでは、作成した事後分析を社内だけでなく外部と共有することについては、どうお考えでしょうか。そもそも、なぜそんなことをするのでしょう? それは、サービス プロバイダーやプラットフォーム プロバイダーの場合、事後分析をお客様と共有することは、自社にとってもお客様にとっても良い結果をもたらす可能性があるからです。
今回の『
CRE が現場で学んだこと
』シリーズでは、外部向け事後分析の利点と弊害、またその作成方法に関する実践的な知識について解説します。
外部向け事後分析の事例
過去の事例を調べ、分析内容を読み解く
Google は長年にわたってサービス停止の情報を共有してきましたが、最近ではその詳細をこれまで以上に公表するようにしています。たとえば、2016 年 4 月 11 日に発生した Google Compute Engine による着信トラフィックのドロップを、
このようなインシデント レポート
として公開しました。
同様に、他社でもサービス停止の詳細な事後分析を公表しています。以下はその一例で、記憶にある方も少なくないでしょう。
GitLab.com が誤って PostgreSQL データベースを削除
、しかもバックアップがないことが判明した
CloudFlare のエッジ サーバーでメモリ リークが発生した
Honeycomb.io で Kafka のバグが利用された
Google の SRE チームはこうしたインシデントの事後分析を読むことを好みますが、別に他人の不幸を喜んでいるわけではありません。実際、SRE チームはこれを読んで “there but for the grace of (Deity) go we”(「明日は我が身」の意)と考え、同じような失敗に自分たちは耐えられるだろうかと思いを巡らせます。もし同じように感じている方がおられたら、
災害復旧テスト
(DiRT : Disaster Recovery Testing)の実施をお勧めします。
さまざまなユーザーに広くサービスを提供しているプラットフォーム プロバイダーにとって、こうした事後分析を外部に公開することには意味があります(その準備はとても大変ですし、競合他社や報道機関からの批判にさらされるかもしれませんが)。たとえサービス停止の影響がさほど大きくないとしても、SRE を実践しているのであれば、直接影響を受けたお客様に事後分析を提供することは理にかなっています。お客様の信頼を気にかけるということは、サービス停止の詳細をお客様と共有することでもあります。
Google Cloud Platform
(GCP)の
CRE
(Customer Reliability Engineering)チームも、これと同じ立場を取っています。GCP のことをお客様に信頼していただくため、SRE のベスト プラクティスを共に実践し、サービスの信頼性向上につながる方法をお客様に伝えます。それぞれのお客様のサービスにおいて構造上のリスクや運用上のリスクを特定して数値化し、そのリスクを低減させるべく共同で取り組み、お客様の
SLO
(サービス レベル目標)に合ったシステムの信頼性を維持できるように努めます。
具体的には、CRE チームがお客様の SLO に見合う可用性を保てるよう、それぞれのお客様と共同で取り組みます。そのための主な手順は次のとおりです。
ビジネスに関連する SLO を包括的に定義する
お客様が自社の監視プラットフォームで SLO に準拠しているかを測定できるようにする(サービスのエラー バジェットがどれだけ使われているかを把握できるようにする)
Google のサポートおよびプロダクト担当 SRE チームとの間で生の SLO 情報を共有する(これは共有監視と呼ばれる)
SLO 違反をお客様と共同で監視し対応する(運用上の宿命を共有する)
プラットフォームやそれに似たものを運用しているのであれば、
お客様と共同で SRE を実施してください
。そうすれば信頼性が向上し、変更を施したときにお客様が戸惑うこともなくなり、障害が発生した際の影響やその範囲に関する知識も高まります。
また、サービスのエラー バジェットを超えるようなインシデントや、許容範囲以上の割合でエラー バジェットを使ってしまうようなインシデントが発生した場合、サービス プロバイダーは次のことを把握する必要があります。
エラー バジェットは合計でどれだけ使われたのか
なぜインシデントが起こったのか
同じインシデントが再発しないように、できること、やるべきことは何か
1 の質問には簡単に答えられますが、2 と 3 の質問を判断する仕組みに相当するのは事後分析となります。インシデントの根本的原因が純粋にお客様側にあるのであれば簡単ですが、自社のプラットフォーム側で発生した何かがきっかけだったとしたらどうでしょう。そういう場合は外部向け事後分析を検討すべきです。
外部向け事後分析の基礎となるもの
サービス停止の分析と、その内容を事後分析として書き起こすことで、プラットフォーム運用者とサービス プロバイダー双方から 2 種類の監視データを入手できることになります。これにより、インシデントはいつ発生したのか、どれくらい継続したのか、どれほどひどかったのか、お客様のエラー バジェットに対して合計でどれほどの影響があったのかなど、インシデントの外的影響を客観的に測定できます。
これが非常に役に立つと、GCP の CRE チームは考えています。エンドユーザー側の下層レベルのクラウド サービスで発生した問題は、その影響の測定が難しいためです。内部で 1 % のエラー率を観測してレイテンシが増加したとしても、スタックの多くのレイヤを移動すると、外部ではなかなか気づかないものです。
サービス プロバイダーの監視データと独自の監視情報を基に、プラットフォーム チームは
標準的な方法
と Google の
事後分析テンプレート
に沿って事後分析を作成します。これにより、内部でレビューしたドキュメントが出来上がり、そこにはインシデントの時系列や、影響の範囲と大きさ、優先順位の高い行動などが書かれています。
優先順位の高い行動とは、こうした状況が発生する可能性を低くし(平均故障間隔の増加)、予想される影響を抑え、検知精度を向上させ(平均検知時間の短縮)、インシデントから迅速に回復すること(平均回復時間の短縮)を可能にするための行動です。
ただし、事後分析を外部と共有する場合はこれで終わりではありません。影響を受けたお客様に対して、すべてではないにしろ、一部の事後分析情報を公開するのです。
外部向け事後分析を誰に公開するべきか
SLO を定義したのがお客様である場合は、インシデントによってどれほど影響があったのかを、お客様は(あなた自身も)把握していることでしょう。一般に、インシデントによって使われたエラー バジェットが大きければ大きいほど、お客様はその詳細を詳しく知りたいと考えるため、情報共有の重要度も高まります。また、インシデントの直後には判明していなかった事故の範囲やタイミング、影響など、事後分析にまつわるフィードバックをお客様が提供してくれる可能性も高くなります。
お客様の SLO 規約には触れなかったものの、その問題がお客様のエンドユーザーにも影響を与えてしまったときは、お客様の側でも事後分析を行う必要があります。SLO やその測定方法に関して、どのような変更が必要なのかを見極めるのです。たとえば、可用性を測定していた場所が、実際に問題が発生した場所よりもずっと下のレイヤにあったのではないか、といったことなどです。
もしエンドユーザー エクスペリエンスを示す SLO をお客様が設定していなかった場合、客観的に事故を判断することは難しくなります。インシデントが特定のお客様に偏って影響を与えたことを示す明確な理由でもない限り、より包括的なインシデント レポートにするしかないでしょう。
もう 1 つ考慮すべき点としては、情報共有したいお客様と NDA(秘密保持契約)を結んでいるかどうかです。結んでいない場合、共有できる内容は必然的に厳しく制限されます。
障害によって多数のお客様に影響が及んだときは、上述した例のように、外部向け事後分析を一般向け事後分析やインシデント レポートのベースとすべきかどうかも検討しましょう。もちろん、これは(内部向け事後分析を編集して内部の承認を得るといった)一部のお客様とだけ共有する外部向け事後分析よりも大変な作業ですが、それなりの利点があります。
事後分析を完全に一般公開することの最大のメリットは、ユーザーからの信頼を取り戻せることではないでしょうか。プラットフォームを利用している 1 ユーザーの視点からすると、特定ユーザーの問題なんてプラットフォーム プロバイダーは気にしていないと感じていることでしょう。そうしたユーザーに向けて事後分析を一般公開すれば、サービスに何が起こったのか、その理由は何だったのか、今後どうやって再発を防ごうとしているのかを多くのユーザーが把握できるようになります。
公開された情報を基にユーザーがミニ事後分析を行い、「もし同じことがまた起こったら、それをどう検知すればいいか、また自分たちのサービスへの影響を抑えるにはどうすればいいか」といったことをユーザー自身で考えるきっかけになるのです。
どこまで共有するか、なぜ共有するかを決める
外部向け事後分析を作成するにあたっては、サービス停止の原因をどこまで深く掘り下げるかについても考えなくてはなりません。内部向け事後分析をほとんど編集することなく提供するべきなのか、それとも短いインシデント サマリーを作成するべきなのか。これはややこしい問題で、Google 社内でもたびたび議論してきました。
Google では、簡単なサマリーではなく事後分析の詳細すべてをお客様に提供するかどうかを、以下の 2 点を基に決めています。
障害の再発防止を検討するにあたり、事後分析の詳細がどれだけ重要か
障害によってお客様のサービスはどれほどの損害を被ったか。つまり、どれだけエラー バジェットを使ったのか
もしお客様が内部向け事後分析から事故の詳細な時系列を把握できたとしたら、お客様側の監視による警告と関連づけることができ、今後は事故検知までの時間を短縮できるかもしれません。逆に、サービス停止で使った 30 日間のエラー バジェットがわずか 8 % だった場合、お客様はこうした事故が 1 か月に一度以上発生する可能性があるかどうかを知りたいだけということもあります。
Google は、自動化と実践を組み合わせることで、内部向け事後分析の共有可能なバージョンを、10 % の追加作業と内部レビューによって作成できるようにしました。欠点としては、作業開始前に事後分析が完了またはほぼ完了するのを待たなくてはならないことです。一方、インシデント レポートについては、事後分析作成担当者が根本的原因をほぼ突き止めた段階で、事後分析と同等の労力で作成できます。
事後分析の内容
事後分析が作成される頃にはインシデントも解決しています。その段階でお客様が本当に知りたいのは以下の 3 点です。
なぜインシデントが発生したのか?
よりひどくなる可能性はあったのか?
どうすればもう発生しないと確信が持てるのか?
「なぜインシデントが発生したのか?」は、Google の事後分析テンプレートの “Root causes and Trigger”(根本的原因ときっかけ)や “What went wrong”(何が間違っていたのか)のセクションに当てはまります。また、「よりひどくなる可能性はあったのか?」は “Where we got lucky”(運が良かった点)です。
この 2 点は、内部向け事後分析にできるだけそのまま記載すべき項目です。とはいえ、わかりやすく言い換える必要はあるかもしれません。
「どうすればもう発生しないと確信が持てるのか?」は、事後分析の中のやるべきことに関する表に当てはまります。
記載してはいけないこと
事後分析には以下の 3 点を記載してはならないことも覚えておきましょう。
人の名前 :
「John Smith さんが誤ってサーバーを蹴飛ばしてしまった」とするのではなく、「ネットワーク エンジニアが誤ってサーバーを蹴飛ばしてしまった」と書きましょう。Google 社内では人の役割を人名ではなく役職で表現するようにしています。こうすることで、
誰も責めることのない事後分析カルチャー
が保たれています。
内部システムの名称 :
内部システムの名称はユーザーに公表しておらず、それがどう組み合わさっているのかを把握することもユーザーにとっては困難です。たとえば、Google では Chubby のことを社外の人に話す機会がありますが、外部向け事後分析には「われわれのグローバル分散ロック システム」と記載しています。
お客様固有の情報 :
内部向け事後分析にはおそらく「x 時 x 分に Acme 社から問題が発生したことを知らせるサポート チケットが発行された」と記載されていると思いますが、こうした詳細は報告した企業(この場合は Acme 社)に過度の負担がかかる可能性があるため、外部と共有するのは控えるべきです。ここでは簡単に、「x 時 x 分にお客様から ……」としておきます。1 社以上のお客様について記載する場合は、お客様 A、お客様 B などとして区別しましょう。
その他、気をつけるべきこと
事後分析を外部と共有するうえで、もう 1 点難しいことがあります。それは、インシデントの状況を設定する “Background”(背景)のセクションです。内部向け事後分析の場合、読者が技術的背景および運用の背景に関する基礎的な知識を有していることを想定して書かれていますが、外部のお客様がそのような知識を持ち合わせているとはかぎりません。
Google では、細かい説明を最小限に抑えつつも、なぜインシデントが発生したのかを読者が把握できるようにしています。ここで詳細を記載しすぎると、役に立つというより不快感を与えてしまうおそれがあるのです。
Google の SRE チームは、よく事後分析に監視グラフを組み込みます。監視データは客観的で、一般的に嘘をつくことはありません(とはいえ、それが当てはまらないこともあります。これについては、Google の Sebastian Kirsch が
便利な指標
を示しています)。
ただし、事後分析を社外と共有するにあたっては、こうしたグラフの情報がトラフィック レベルやサービスのユーザー数などを公にしてしまう点に気をつけましょう。目安としては、X 軸(時間)はそのままにしておき、Y 軸は指標や数量を消すか、割合のみを示すようにしてください。これは、お客様側で生成されたデータを内部向け事後分析に組み入れる場合にも言えることです。
運が果たす役割
Tina Turner の『What's Love Got To Do With It』(「いったい愛と何の関係があるの?」の意。邦題は『愛の魔力』)という歌には申し訳ないですが、ここでは “What's Luck Got To Do With It”(いったい運と何の関係があるの?)」としておきましょう。今後の障害の原因となるもの以外の運とは何なのでしょうか。
Google の内部事後分析テンプレートには、“What went well”(何がうまくいったのか)や “What went badly”(何がうまくいかなかったのか)はもちろんのこと、“Where we got lucky”(運が良かった点)という項目も含まれています。
運に関する項目は、インシデントで発覚した今後の障害のリスクを引き出すのに役立ちます。インシデントはたいてい、タイミングや、ある特定の人がオンコール担当だったこと、別の障害が同時に発生して通常より詳しい精査が本番システムで必要になったことなど、比較的ランダムな要素によって、実際に与えたであろう影響よりも小さな影響しか出ないことが多いのです。
「運が良かった点」は、事後分析において追加でやるべきことを確認するきっかけとなります。たとえば次のようなことです。
「適切な人がオンコール担当だった」ということは、作戦ノートに記載すべき部門知識が存在しているということです。災害復旧テストでもその内容を実施する必要があります。
「(バッチ プロセスやユーザー アクションなど)他のことが同時に起こっていなかった」ということは、ピーク時の負荷を処理するのに十分な容量がシステムに備わっていないということです。リソースの追加を検討すべきでしょう。
「インシデントの発生が業務時間内だった」ということは、自動アラートや 24 時間ページャーで呼び出せるようなオンコール体制が必要だということです。
「すでに監視モニターを見ているところだった」ということは、積極的に監視していなくても似たような最先端のインシデントを見つけられるよう、アラートのルールを調整する必要があるということです。
事後分析に “Where we got unlucky”(不運だった点)について書くこともあります。いくつもの状況が重なってインシデントの影響が大きくなったものの、同様のことが起こる可能性は低いケースがそれに当たります。不運な例としては以下のようなものがあります。
1 年で最も忙しい日にサービス停止が発生した
問題は修復していたものの、他の理由により、まだロールアウトしていなかった
天候が原因で停電が発生した
「不運だった点」というカテゴリーを設けることの主なリスクは、実際には不運が原因ではないにもかかわらず、問題を不運だったと分類してしまうことです。内部向け事後分析で以下のように報告された例を見てみましょう。
不運だった点
過去の障害や実験により、本番環境にさまざまな矛盾が生じていた。それが適切に処理されておらず、本番環境の状態を判断するのが困難だった。
これは、“What went badly”(何がうまくいかなかったのか)に分類すべきでしょう。取り組むべき点が明らかであり、今後に向けた修正も可能だからです。
このような不運に見舞われたときは、必ず「何がうまく行かなかったのか」に記録するようにし、今後発生する可能性を算定するとともに、どう対処すべきかも決めるようにしてください。開発時間は限られているため、すべてのリスクを低減しようとは思わないかもしれませんが、常にすべてのリスクを列挙して数値化し、状況が変わっても「未来の自分」がその決定を見直せるようにしておきましょう。
まとめ
この記事を読まれたプラットフォーム プロバイダーやサービス プロバイダーの皆さんが、適度に詳細が書かれた内部向け事後分析を社外にも公開したいと思える明確なモチベーションを抱いてくれるようになれば幸いです。次回は、こうした事後分析を最大限に生かす方法について解説します。
* この投稿は米国時間 11 月 27 日、Customer Reliability Engineer である Adrian Hilton と Gwendolyn Stockman によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton and Gwendolyn Stockman, Customer Reliability Engineers
優れた SLO を策定するには : CRE が現場で学んだこと
2017年11月8日水曜日
CRE シリーズ
の過去記事『
SLO、SLI、SLA について考える
』では、サービスの信頼性を定義し測定するうえで重要なのはサービス レベル指標(SLI)とサービス レベル目標(SLO)を適切に設定することだと説明しました。SLI と SLO については、
SRE 本
でも 1 つの章を割いて詳しく解説しています。
今回は、SLI のもとで SLO を策定するにあたり、私たち Google が活用しているベスト プラクティスをいくつか紹介します。
SLO の意義
SLO は、企業が達成したいとする目標であり、防御のために起こす行動でもあります。ただし忘れてならないのは、
SLO はサービス レベル契約(SLA)ではない
ということです。ユーザー エクスペリエンスにおいて最も重要な側面を SLO が象徴するようにしなくてはなりません。SLO が満たされるということは、ユーザーにとっても自社にとってもハッピーなことでなくてはならないのです。一方で、システムが SLO を満たさないということは、不満を持つユーザーがいることを意味します。
企業は、システム停止の頻度を減らし、万が一停止したときはその影響を抑えることで、存続が危ぶまれる SLO を保護できるようにしなくてはなりません。その方法には、新バージョンのリリース頻度を減らすことや、機能追加よりも信頼性向上に努めるといったことも含まれます。企業全体にとって SLO は貴重なもので、代償を払っても守るべきものだということを認識する必要があります。
SLO の策定にあたって留意すべき重要な点は以下のとおりです。
SLO は、チームがやるべきことについて意味のある疑念を解決する便利なツールとなります。「この課題には絶対取り組まなくては」ということと、「この課題には取り組まなくていいかもしれない」ということの間に線引きすることこそが目標なのです。したがって、SLO のターゲットを必要以上に高く設定しないようにしましょう。現在たまたまその目標値を満たしているとしても、いったん設定してしまうと今後何か変更する際に柔軟性が損なわれるおそれがあります。たとえば、信頼性を犠牲にしても開発速度を上げるべきかということを考える際に、柔軟性が制限されてしまうのです。
SLO にクエリをグループ分けするときには、特定の製品要素や内部実装の詳細ではなく、ユーザー エクスペリエンスによって分けましょう。たとえば、ユーザーの行動に対する直接的なレスポンスは、バックグラウンドや付随的なレスポンス(サムネイルなど)とは別の SLO にグループ分けすべきです。同様に、(製品を閲覧するというような)「読み込み」の操作は、(精算するという操作のように)頻度は低いものの、より重要な「書き込み」の操作とは別グループに入れるべきです。それぞれの SLO においては、可用性やレイテンシの目標値が異なります。
SLO の範囲と、それがどこまでをカバーするのか(どのクエリ、どのデータ オブジェクトまでをカバーするのか)、さらにはどういった条件で SLO が提供されるのかを明確にしておきましょう。無効なユーザー リクエストをエラーとして数えるのか数えないのか、また、あるクライアントから多数のリクエストを送られるといったスパムに見舞われたらどうするか、ということについても検討してください。
最後に、上記内容とは若干綱引きの状態になってしまいますが、SLO は簡潔かつ明確なものにしておきましょう。SLO では、本当に気になる部分を曖昧にするのではなく、重要でない操作までカバーしないようにするほうがよいのです。規模の小さい SLO で経験を積んでください。まずはリリースして繰り返すのです。
SLO の例
可用性
Google では、「ユーザーはサービスを利用できていますか ?」という質問に答えることができるように、失敗したリクエストと既知のミスのリクエストを数え、その値を割合でレポートする方法を採用しています。(ブラウザの HTTP リクエストからではなく、Load Balancer からのデータのように)制御できる最初のポイントからのエラーを記録します。マイクロサービス間のリクエストに関しては、サーバー サイドではなくクライアント サイドからのデータを記録します。
そうすると、次のような SLO になります。
可用性 :
<サービス>は、<お客様のスコープ>に対して、<SLO が定めた期間>のリクエストのうち、最低でも<この割合>で<正常にレスポンスを返します>。
以下は具体例です。
可用性 :
Node.js は、ブラウザのページビューに対して、1 か月のリクエストのうち、最低でも 99.95 % の割合で 30 秒以内に 503 以外のレスポンスを返します。
可用性 :
Node.js は、モバイル API の呼び出しに対して、1 か月のリクエストのうち、最低でも 99.9 % の割合で 60 秒以内に 503 以外のレスポンスを返します。
レスポンスに 30 秒以上(モバイル API の場合は 60 秒以上)を要したリクエストについては、サービスがダウンしていた可能性があり、可用性の SLO が満たされなかったことになります。
レイテンシ
レイテンシは、サービスがどの程度のパフォーマンスを発揮したかをユーザーに示す数値です。Google では、しきい値よりも遅かったクエリの数を数え、全クエリの割合としてレポートしています。クライアントに近ければ近いほど正確な数値を測定できるため、ウェブ リクエストを受信する Load Balancer でレイテンシを測定します。マイクロサービス間については、サーバーではなくクライアントから測定しましょう。
レイテンシ :
<サービス>は、<SLO が定めた期間>のリクエストのうち、最低でも<この割合>は<制限時間>内にレスポンスを返します。
具体例は次のとおりです。
レイテンシ :
Node.js は、1 か月のリクエストのうち最低でも 50 % は 250 ミリ秒以内にレスポンスを返し、1 か月のリクエストのうち最低でも 99 % は 3000 ミリ秒以内にレスポンスを返します。
パーセンテージの理由
ここでは、レイテンシの SLI をパーセンテージとして示していることに注目してください。「99 番目のパーセンタイル レイテンシ」をミリ秒で表した数値を「3000 ミリ秒未満」とするのではなく、「レイテンシが 3000 ミリ秒未満のリクエストの割合」の目標値を 99 % としているのです。こうすることで SLO の単位と範囲がすべて同じになるため、SLO の一貫性が保たれ、わかりやすくなります。
巨大なデータセットの全体にわたって正確なパーセンタイルを測定するのは大変ですが、しきい値以下のリクエストの数を数えるのは簡単です。しきい値については、(たとえば 50 ミリ秒以下や 250 ミリ秒以下のリクエストの割合など)さまざまな数値を監視したいと思うかもしれませんが、あるしきい値は 99 % を SLO の目標値とし、別のしきい値は 50 % にするといった具合で一般的には十分です。
レイテンシの平均値を目標値とするのはやめましょう。望みどおりの結果はほぼ出ないと思ってください。平均値は異常値を隠してしまうことがありますし、かなり小さい数値はゼロと見分けがつきません。
ユーザーは、全ページのレスポンス時間が 50 ミリ秒と 250 ミリ秒のどちらであっても、おそらくその違いに気づかないので、両方とも良しとするでしょう。ただし、すべてのリクエストが 250 ミリ秒を要しているために平均値が 250 ミリ秒になる場合と、95 % のリクエストは 1 ミリ秒を要し、残り 5 % のリクエストが 5 秒を要しているために平均値が 250 ミリ秒になる場合とでは、大きな違いがあります。
100 % の場合は話が別
目標値 100 % というのは、どの時間幅においても不可能ですし、必要性もないでしょう。SRE は SLO を使って
リスクを容認
します。SLO の目標値の逆はエラー バジェットになるので、SLO の目標値を 100 % とすると、エラー バジェットがまったくないことになってしまいます。
また、SLO はチームの優先順位を決めるツールでもあります。最優先にすべき仕事と、ケース バイ ケースで優先順位を決める仕事とを分けるのです。それぞれの障害をすべて最優先にしてしまうと、SLO としての信頼性がなくなりかねません。
最終的に決める SLO の目標値が何であれ、その議論はとても面白いものになるでしょう。今後のためにも、論理的根拠を基に目標値を設定してください。
SLO のレポート
SLO は四半期ごとにレポートし、四半期の統計に応じてポリシーを決めましょう。特に、担当者をページャーで呼び出す場合のしきい値を決めるようにしてください。短い期間の数値だと、小さな日々の問題ばかりに目が行き、頻度は高くないもののダメージが大きい問題を見落としがちです。ライブでのレポートも、混乱を避けるために四半期レポートと同じ枠組みを使用するようにしてください。発行された四半期レポートはライブ レポートの寸評に過ぎません。
SLO 四半期サマリーの例
以下は、SLO に対するサービスのこれまでの実績を提示する方法です。たとえば、SLO の期間が 1 四半期となっている場合の半期のサービス レポートは次のようになります。
SLO
目標値
第 2 四半期
第 3 四半期
ウェブの可用性
99.95 %
99.92 %
99.96 %
モバイルの可用性
99.9 %
99.91 %
99.97 %
レイテンシ 250 ミリ秒以下
50 %
74 %
70 %
レイテンシ 3000 ミリ秒以下
99 %
99.4 %
98.9 %
エラー バジェットを使用した際のページャーへのアラートやリリースの凍結など、SLO に依存するポリシーについては、時間枠を四半期より短くしてください。たとえば、過去 4 時間に四半期のエラー バジェットを 1 % 以上使った場合はページャーを鳴らすとか、過去 30 日間で四半期のエラー バジェットの 3 分の 1 以上を使った場合はリリースを凍結するといった具合です。
SLI のパフォーマンスの内訳(地域別、区分別、顧客別、特定の RPC 別など)はデバッグやアラートには役に立ちますが、SLO の定義や四半期サマリーにおいては通常はさほど必要はありません。
最後に、特に初期の段階では SLO を共有する相手を意識するようにしてください。SLO は、サービスの期待値を伝えるうえで非常に便利なツールですが、いろんな人に知られてしまうと変更することが難しくなります。
まとめ
SLO は興味深いテーマですが、私たちはしばしば、SLO の論証にあたって使える便利な目安について質問を受けることがあります。
SRE 本
にはそのことについても詳細に書かれていますが、ここで説明した基本的なガイドラインから始めれば、SLO に取り組むにあたって犯しがちな一般的な間違いを避けることができるでしょう。
ここまで読んでいただき、ありがとうございました。この投稿がお役に立てれば幸いです。そして Google 社内でいつも言っているように、クエリがきちんと流れ、SLO が満たされ、ページャーが静かなままでいてくれることを願っています。
* この投稿は米国時間 10 月 23 日、Customer Reliability Engineer である Robert van Gent と Stephen Thorne、および Site Reliability Engineer である Cody Smith によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Robert van Gent and Stephen Thorne, Customer Reliability Engineers and Cody Smith, Site Reliability Engineer
SRE との “壁” を取り除くには : CRE が現場で学んだこと
2017年7月24日月曜日
今回の連載記事の
パート 2
では、サービスのサポートを引き継ぐにあたって SRE チームが知りたいことは何なのか、引き継ぎまでにサービスをどう改善してほしいと考えているのかを説明しました。また、
パート 1
では SRE が新しいアプリケーションを担当する(または担当しない)と判断するときの理由を挙げました。今回は、ページャーを担当することになった SRE とのやり取りについて見ていきましょう。
サポート担当の準備
サービスの事前レビューで SRE によるサポートが適当だと判断された場合、開発者と SRE チームはサポートの開始に向けて準備を行う “onboarding” のフェーズに移行します。
このフェーズでは、開発者はやるべきことに対処し、SRE チームはサービスについて学び始めます。サービスに関する知識を身につけ、既存のモニタリング ツールやアラート、危機対処法などを学ぶのです。その方法は、以下のようにさまざまです。
教育 :
技術トークや討論会、“Wheel of Misfortune”(不運のルーレット)のシナリオなどを通じて、新サービスをチームの他のメンバーに紹介する。
ページャー担当を少し体験 :
1 週間にわたって開発者とページャーを共有し、アラートごとにその重要度(ユーザーに影響を与える問題がサービスで発生していることを示すアラートかどうか)と、対応の可能性(オンコール担当者が問題を根本的に解決するにあたって明確な方法があるかどうか)を評価する。これにより、SRE チームはサービスの運用負荷がどれくらいなのかを定量的に測定できる。
オンコールの同時担当 :
オンコールの第 1 担当者である開発者と SRE を同時に呼び出します。この段階での緊急対応の責任者は開発者だが、開発者と SRE は協力してデバッグや問題解決に努める。
成功かどうかの判断基準
Q : サービスのサポートを SRE に引き継ぐためにさまざまな努力をしてきました。時間を割く価値があったのかどうかをどうやって評価するのですか?
開発者と SRE チームがサービスの担当変更を合意するにあたっては、この変更が成功だったかどうかを評価する基準についても(その時間枠も含め)合意していなくてはなりません。評価基準には以下のようなものがあります(適切な数値も必要です)。
呼び出しの数や停止の数が絶対的に減少した。
(拡張中の)サービスの規模や複雑さに比べて、呼び出しの数や停止の数の割合が減少した。
グローバルにデプロイする新コードのテストに合格した時点から、時間や労力が減少し、ロールバックの比率は変わらない(または減少している)。
(CPU、メモリ、ディスクなどの)予約済みのリソースを活用することが増えた。
こうした基準に合意しておくと、担当の引き継ぎを将来提案する際の地盤を築くことにもなります。以前の引き継ぎ時に基準が満たされていなかった場合は、新サービスの引き継ぎ計画を慎重に考えなくてはなりません。
ページャー担当を引き継ぐ
障壁となっていた項目がすべて解決すれば、いよいよ SRE がサービスのページャー担当を引き継ぎます。
理論上は、SRE チームが事前レビューの段階でほとんどの課題を特定していたはずですが、サービスを実際に引き継いで担当してみないと見えてこない問題もあります。
中期的に見ると(1~2 か月)、SRE は、モニタリングやリソース消費などにおけるシステム上の欠陥や最適化できる部分のリストを作る必要があります。
このリストの一番の目的は、SRE の手間(手作業や何度も発生する作業、限定的な作業といった持続的価値のない作業)を減らすことです。また、2 番目の目的は、システムのパフォーマンスに影響を与えるようなリソース消費や雑な作りの部分などを修復することです。さらに、システム サポートの担当になった SRE の手助けとなるよう、ドキュメントを更新するといったことも 3 番目の目的として入れておくとよいでしょう。
長期的には(3~6 か月)、SRE は上述したような担当変更の成功基準をほとんど、もしくはすべて満たしている必要があります。
Q : すばらしいですね。これで開発者はページャーの電源を切ってもいいんですよね?
そんなに急がないでください。過去数か月にわたり SRE チームはサービスについて多くのことを学びましたが、まだ彼らはエキスパートではありません。サービスが不可解な動きを示し、オンコール担当の SRE ではどこに不具合があるのか把握できなかったり、修復方法がわからなかったりすることが必ず出てきます。
開発者の存在以上に頼れるものはないので、通常は開発者にもオンコール担当のシフトに継続して入ってもらい、必要に応じて SRE のオンコール担当者が開発者を呼び出せるようにします。ただし、呼び出しの頻度は低いと思われます。
ページャー担当を元に戻すという究極の選択
SRE への引き継ぎがすべてうまくいくとは限りません。SRE がサービスのページャー担当になったとしても、信頼性が低下したり運用負荷が高くなったりする可能性もあります。これには、利用率が予期せず急激に上昇しその状態が続く “success disaster”(成功による惨事)といった良い理由のときもあれば、QA テストがひどかったという悪い理由のときもあります。
SRE チームが担当できるサービスの数には限りがあり、1 つのサービスが SRE の時間を大幅に消費してしまうと他のサービスにも影響が出る危険性があります。このようなときは、SRE チームは開発チームに対して問題を抱えていることを積極的に伝え、具体的なデータを示して次のように中立的に説明します。
過去 1 か月の間に S1 サービスには週に 100 回のページャー呼び出しがありましたが、その前の数週間は呼び出しの回数が週に 20~30 回でした。S1 は SLO の基準内に入っていますが、このように頻繁に呼び出されると運用作業にかかりきりになり、サービス向上のための作業が滞ってしまいます。そのため、以下のいずれかを行う必要があります。
S1 の変更率を減らし、S1 の呼び出し率を以前の値にまで下げる。
S1 のアラートを調整し、ほとんどのアラートは呼び出しがかからないようにする。
S2 と S3 のサービスについては SRE を担当から外し、全体の呼び出し率を一定に保つ。
S1 のサポートから SRE を外す。
こうすることで、開発チームは SRE チームに解決策を任せるのではなく、自分たちにとって何が一番重要なのかを決めることができるのです。
運用負荷が正常値の範囲内であったとしても、開発者と SRE の双方が、開発者にページャーを返すほうがよいという意見で一致することがあります。たとえば、SRE がサービスのサポートを担当していて、開発者がそのサービスのすばらしい高パフォーマンス バージョンを思いついた場合などです。
この場合は、まず開発者が新バージョンのサポートを担当して不備を調整し、ユーザーを徐々に移行させます。最終的に新バージョンが最も安定して使用されるようになると、SRE が新バージョンのページャー担当となり、旧サービスのページャーを開発者に返すのです。その後、開発者はユーザーの移行を完了させ、都合のよい時点で旧サービスを停止させます。
SRE チームと開発チームの融合
サービスの担当変更は、単に責任者を開発者から SRE へと変えることにとどまりません。担当を変更することは、お互いのチームをより深く理解することにつながります。
開発チームは、SRE チームが何をしているのか、なぜそんなことをしているのか、また SRE の各個人についてもよく知ることができますし、SRE がなぜそのようになったのかを把握できるかもしれません。
SRE チームのほうも、開発チームの仕事や心配事などについて、より深く理解できます。共感する点が増えることはそれだけでも良いことですし、うまくいけばアプリケーションを改善するきっかけにもなります。
ここまで来れば、開発チームが新しいアプリケーションやサービスを設計するときには SRE チームも議論に参加してもらうよう招待するべきです。SRE チームは設計段階で信頼性に問題があることを簡単に見つけ出すでしょうし、開発者に最初からアドバイスもできます。アドバイスの範囲は、サービス運用の簡素化はもちろん、すぐれたモニタリングのセットアップや適切なロールアウト ポリシーの設定など多岐にわたります。
同様に、SRE が新たなツールの計画や設計に携わる際には開発者を巻き込むべきでしょう。開発者は今後のローンチやプロジェクトに関してアドバイスできますし、ツールの操作性やニーズに関するフィードバックを提供することもできます。
SRE チームと開発チームの間に大きなブロック壁が立っている場面を想像してみてください。サービス引き継ぎの当初のやり方は、サービスを壁の向こう側に投げて祈ることでしたよね。
今回の一連の記事では、壁に穴を開け、そこから双方向のコミュニケーションを通じてサービスを引き渡し、さらに戸口を開いて SRE が開発者の敷地に入り、開発者が SRE の敷地にまでやって来ることを説明しました。最終的に、開発者と SRE は壁を完全に取り壊し、低い垣根ときれいな庭のアーチに置き換えることになります。SRE も開発者も、お互いの庭で何が行われているのかを見えるようにし、必要に応じて相手側の庭に入っていく必要があるのです。
まとめ
開発者がサポートしていたサービスのページャーを SRE が担当するときは、垣根越しに相手側の庭に投げ込むのはやめましょう。そうではなく、SRE チームと一緒になって、サービスの仕組みや故障の原因を理解してもらうようにし、サービスの復元力とサポート性を高める方法を考えるのです。SRE がサービスをサポートすることは、SRE にとって有効な時間であり、SRE の特別なスキルの活用にもつながっていることをきちんと確認してください。
引き継ぎのプロセスをじっくり計画しておけば、クエリも順調に流れ、ページャーも(ほとんど)鳴ることはないでしょう。
* この投稿は米国時間 7 月 7 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer
SRE へのサポート移行で失敗しないために : CRE が現場で学んだこと
2017年7月19日水曜日
このブログ記事の
パート 1
では、SRE チームが新規アプリケーションのサポートを担当するかどうかを判断するときのポイントについて説明しました。今回は、SRE のサポートによってサービスに大きなメリットが生まれると想定したうえで、そのサービスのサポートを SRE が自信を持って担当できるようにするにはどうすればよいのかを見ていきます。
サポート移行前のレビュー
Q : SRE がサポートを担当したほうがよいと思われる新しいアプリケーションがあります。とりあえず SRE チームに渡して、「はいどうぞ。これからこのサービスを担当してください。がんばってね」と言えばよいのでしょうか?
すばらしい方法ですね。目的が失敗することである場合に限りますが。
最初の段階では、開発チームが考えるサポートの重要性や、アプリケーションがサポートできる状態にあるかどうかという判断は SRE チームの考えと異なることが多く、サービスのサポートを勝手に SRE チームに強要してもうまくいきません。
考えてみてください。このサービスに時間を割くことは有益だと SRE チームをまだ説得できていませんよね。人は、自分でこうだと信じていないものに対しては熱意を持って取り組めないものです。したがって、サービスの信頼性を実質的に高めようとしても、SRE チームが積極的に関与してくれない可能性があります。
Google の場合、SRE にうまくサポートを担当してもらうには、SRE チームがサービスを理解して評価し、事前に解決すべき重要な問題を見つけ出すプロセスがあるということを、サービスの所有者と SRE チームの双方が合意していなければならないと考えています(実は、Google Cloud のお客様のアプリケーションを
Customer Reliability Engineering
プログラムに入れるかどうかを決める際にも、同様のプロセスを踏んでいます)。
Googleでは通常、このプロセスを次の 2 段階に分けて行っています。
SRE entrance review
(SRE による事前レビュー): 開発者がサポートしているサービスを SRE チームが担当すべきかどうか、また担当するにあたっての条件は何かを SRE チームが評価する。
SRE onboarding/takeover
(SRE への担当引き継ぎ):
SRE チームがサービス運用の第 1 責任者となることに開発チームと SRE チームの双方が原則として合意し、SRE への移行に備えて詳しい条件の交渉を始める(いつ、どのような形で SRE がサービスのサポートを開始するか、など)。
このプロセスを進めるにあたっては、さまざまな関係者の思いを念頭に置いておく必要があります。
開発者はサービスのサポートを誰かに任せ、できるだけうまく稼働させたいと考えています。サービスが適切に稼働しているとエンドユーザーに感じてもらいたいためです。うまく稼働していなければ、ユーザーは別のサービスに移ってしまいます。
SRE チームは、サポートしにくいサービスを押しつけられたわけではないことを示したいので、稼働中のサービスをより使いやすく強固なものにしたいと考えています。
企業の経営陣は、開発に時間をかけすぎない範囲で、サービスの停止といったみっともない事態の回数を減らしたいと考えています。
SRE による事前レビュー
SER(SRE entrance review : SRE による事前レビュー)は PRR(Production Readiness Review : 稼働準備レビュー)とも呼ばれており、この段階で SRE チームは現在稼働中のサービスを評価します。SER の目的は以下のとおりです。
SRE チームがサポートを担当することでどのような効果が見込まれるかを評価する。
SRE チームが担当する際に障壁となるようなサービスの設計、実装、運用上の欠陥を特定する。
SRE チームがサポートを担当したほうがよいという結論に至った場合、サポートを担当する前に修復しておくべきバグやプロセスの変更、サービス上必要な動作などを特定する。
SRE チームは通常、1 人またはチーム内の数人でサービスを把握し、サポート担当を引き継ぐ場合の適性を評価します。
SRE はサービスをありのままの状態で見定めます。パフォーマンスやモニタリング、関連する運用プロセス、最近発生した障害の履歴などを調べ、「いま自分がこのサービスの担当だとしたら、どの問題を修復したいか」を考えます。それは、1 日に発生するページ数が多すぎるというような目に見える問題の場合もあれば、1 台のマシンに依存しすぎていつか必ず障害を起こすというように潜在的な問題の場合もあります。
SRE の分析においてどの段階でも重要となるのが、
サービス レベル目標
(SLO)と、関連するサービス レベル指標(SLI)です。
SRE は、サービスが SLO を満たしていればアラートは滅多に発生しない、もしくはまったく発生しないと考えます。一方で、サービスが SLO を満たさない危険があるときは、アラートの音が大きくなり対応が必要だと考えるでしょう。こうした考えが現実と異なっている場合、SRE チームは SLO の定義や SLO の測定値を変更しようとします。
事前レビューにおける SRE チームの目的は、以下を把握することです。
どんなサービスなのか。
日々サービスがどのように稼働しているか(トラフィックの変動、リリースの数、実験管理、設定のプッシュ配信など)。
サービスはどういった状況下で停止する傾向にあるのか、それがどのようにアラートで示されるのか。
モニタリングやアラートの粒度は均等に保たれているか。
サービス設定において SRE チームのやり方と異なる点があるか。
サービスにおける重大な運用リスクがあるか。
また、SRE チームは以下の点も考慮します。
サービスが SRE チームのベスト プラクティスに沿っているか、もしそうでない場合はどうやって改良するか。
サービスをどのようにして SRE チームの既存ツールやプロセスと統合するか。
望ましい関与モデルと、SRE チームと SWE チームの責任分担はどうあるべきか。稼働中に重要な問題が発生してデバッグする際に、オンコール担当の SRE はどの段階で開発チームのオンコール担当を呼び出すべきなのか。
SRE への担当引き継ぎ
SRE による事前レビューでは通常、修復が必要とされるサービスの問題が優先順位別にリスト化されます。そのほとんどは開発チームが担当しますが、SRE チームが担当したほうがよい問題もあります。また、問題のすべてが SRE への移行にあたって障壁となるわけではありません(SRE が推奨する、サービス強化を目的とした設計やアーキテクチャ変更の中には、実装までに何か月もかかるようなものが含まれるかもしれません)。
サポート移行のプロセスにおけるサービス改善の主軸は、実在するバグ、信頼性、自動化、モニタリング / アラートの 4 つです。それぞれの軸には、移行前に(障壁となる)解決すべき問題がありますが、一部には重要ではないものもあります。
実在するバグ
SRE への移行にあたって障壁となる主な問題は、以前のサービス検証時に対応すべき項目として挙げられたものであることが多いようです。SRE チームは最近の検証結果を踏まえたうえで、a)障害の根本的原因を解決するために提案された対応策が想定したものであるかどうか、b)その対応策が実際に完了しているかどうかを確認します。さらに、最近検証が行われていない場合は、SRE チームの多くはこれを警告と見なします。
信頼性
信頼性に関する変更のリクエストが SRE への移行の直接の障壁となることはないでしょう。信頼性改善の多くは、設計や大幅なコード変更、バックエンド統合の変更、必要のないインフラ コンポーネントの移行に関するもので、求められる信頼性確保に向けた長期的なシステムの進化を目指しているからです。
信頼性関連の変更事項の中で、移行の障壁になることがあるとすれば、大規模なダウンタイムの原因となることがわかっている問題を軽視したり取り除いたりすることや、将来的に停止の要因となることが予期されるリスクを緩和することです。
自動化
サポートを担当しようとする SRE が特に気にするのが自動化です。日々担当するサービスを運用するうえで、設定のプッシュ配信やバイナリのリリース、その他似たような時間のかかるプロセスにどれだけ手作業が必要かということです。
どれを自動化するのがよいのかを見極める一番の方法は、SRE が開発者の世界を実際に経験してみることです。つまり、開発チームの一般的な 1 週間の作業を真似てみて、オンコールに至るまでに日々の手作業がどれだけあるのかを SRE が体験するのです。
サービスをサポートするための手作業が大量にある場合でも、自動化によって問題はだいたい解決できるでしょう。
モニタリング / アラート
SRE への移行にあたって主な懸念事項となるのがページャーの呼び出し率です。つまり、就寝中のオンコール担当者を何度起こすことになるかということです。
Google では、「トレイナーの最大値(
Treynor
Maximum)」という指標に従い、12 時間のシフトの中でインシデントが(オンコール チーム全体で)平均 2 回となるようにしています。そのため、SRE チームは新サービスに対する過去 1 か月の平均的なインシデントの負荷を調査し、現在のインシデントの負荷にどう入れ込むのかを判断します。
ページャーの呼び出し率が異常に高い場合、その要因は一般に以下の 3 つのうちのいずれかでしょう。
タスクの再スタートやディスク容量が 80 % に達したなど、本質的に重要でないことでもページャーが鳴ること。こうした場合、(重要でないものは)ページャーをバグと見なすか、完全になくしてしまいましょう。症状ベース(ユーザーが実際に問題に直面している、など)でモニタリングすれば、この状況は改善できます。
小規模なインシデントや停止によって多くのアラートが発生し、ページャーの嵐に見舞われること。1 つのインシデントに関連するアラートは単独の障害としてグループ化し、システム停止の指標を明確に把握しましょう。
システムが真の問題を数多く抱えていること。このようなケースでは、すぐに SRE へと担当を変更することはないと考えられます。ただし、問題の根本的原因を診断し、解決することを SRE が支援できるかもしれません。
SRE は一般に、サポート移行前の数週間におけるページャー呼び出し頻度が低いことが、移行にあたって望ましい状態だと考えています。
このほか、サービスを向上させる一般的な方法は以下のとおりです。
ロード シェディング
やリリース プロセス、設定のプッシュ配信など、標準的な SRE ツールやプラティクスをサービスに統合する。
開発チームの知識に依存しすぎないよう、戦略を充実させ改善する。
サービスの設定を SRE チームの一般的な言語やインフラに合わせる。
最終的には、SRE による事前レビューによって指針が生まれるはずです。この指針は、たとえ SRE チームがサービスのサポート担当になることを辞退したとしても、開発者にとって役に立つものです。事前レビューから生まれた指針は、開発者がサービスをより運用しやすく信頼性の高いものへと仕上げるヒントとなるでしょう。
スムーズな移行に向けて
SRE は開発者のサービスを理解する必要がありますが、SRE と開発者がお互いを理解し合うことも重要です。開発チームがまだ SRE チームと仕事をしたことがないのであれば、SRE チームは開発者に対して、モニタリングやカナリア リリース、ロールアウト、データ統合など、SRE に関するネタを簡単に説明するのもありです。そうすることで、なぜ SRE がそんな質問をして、特定の懸念事項についてうるさく言うのかを開発者は理解してくれるでしょう。
ある Google の SRE はこう言っていました。「自分を開発チームの新人だと思って開発者と接するのがコツ。彼らにコードベースを見せてもらい、その履歴を解説してもらって、main() 関数の機能がどこにあるのかを見せてもらえばうまくいく。」
同様に、SRE は開発者の視点や経験も理解する必要があります。SRE による事前レビューの段階では、最低 1 人の SRE が開発者と行動を共にし、週会議や立ったままのミーティングに出席したり、オンコール担当時の作業を非公式に真似したり、日々の作業を手伝ったりすることで、サービスの全体像やサービスがどのように動いているかを把握します。
また、これによって両チームの距離も縮まります。Google では経験上、このレビュー段階で開発者と SRE の関係が改善されることもわかっており、事前レビューが終了してもこの状況を続けることがあります。
最後になりましたが、SRE による事前レビューの報告書には、SRE がサポートを担当することによってメリットが生まれるのかどうか、またその理由も(メリットのあるなしにかかわらず)きちんと書かれていなくてはなりません。
ここまで来れば、開発チームと SRE チームの双方が、SRE チームに担当を変更してサービスを継続させるには何が必要かをきちんと理解できているはずです。このブログ記事のパート 3 では、サポート移行の具体的な方法について見ていきます。
* この投稿は米国時間 6 月 29 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer
SRE のサポートを受けるべきアプリとは? : CRE が現場で学んだこと
2017年7月7日金曜日
編集部注 :
社内で多くのアプリケーションやサービスが稼働するようになると、SRE(や運用)チームのサポートが追いつかないケースが出てきます。今回の『
CRE が現場で学んだこと
』シリーズでは、企業内のアプリケーションやサービスの中で何を SRE にサポートしてもらうかを、うまく原則に基づいて防御的に決める方法について見ていきます。
Google では幸いなことに、ストレージやネットワーク、ロード バランシングといった横断的なインフラはもちろん、Google 検索や Google マップ、Google フォトなどの主要なアプリケーションも含め、すべてを Site Reliability Engineering(SRE)チームがサポートしています。とはいえ、SRE にはソフトウェア エンジニアとシステム エンジニアの両方を組み合わせたスキルが求められるため、それを満たす人材を見つけて採用するのは容易ではなく、今も需要が供給を上回る状態が続いています。
SRE チームがサポートできるアプリケーションの数には実質的な制限があります。このことを、私たちは時間の経過とともに学びました。また、他よりもサポートに手間がかかるアプリケーションの特徴もわかってきました。多くのアプリケーションを稼働させている企業では、すべてを SRE チームがサポートすることは無理だと思われます。
Q : どうすれば自社の SRE チームが限界に達しているとわかるのですか? どうすればサポートすべきアプリケーションをうまく選べるのでしょう? SRE チームはいつアプリケーションのサポートを止めるべきなのでしょうか?
いい質問ですね。これらの問題について詳しく見ていきましょう。
SRE によるサポートの実質的な限界
Google の場合、誰も燃え尽きることなくページャー担当者をローテーションさせるのに必要な SRE チームの最低人数は、経験則からいってエンジニア 6 人です。1 日 24 時間週 7 日のローテーションで待機し、目標とするレスポンス時間は 30 分以内、ページャーのアラートがエンジニアの睡眠を妨げることがないよう、待機時間は 1 人のエンジニアにつき連続 12 時間を超えないことが条件です。つまり、エンジニア 6 人のグループが 2 つ必要で、それぞれがページャーに対応する時間帯をほぼ日中に合わせられるよう、各グループは地理的に離れていることになります。
どんな場合においても、ページャーに対応する第 1 担当者が存在します。第 1 担当者にたまたま連絡がつかなかったり、第 1 担当者がインシデント対処中だったりして対応できないときは、第 2 担当者がページャーに応えます。
第 1 担当者と第 2 担当者は通常の運用業務をこなし、他のチーム メンバーには、信頼性向上、より良いモニタリング システムの構築、運用業務の自動化促進といったプロジェクト業務のために時間を費やしてもらいます。つまり、各エンジニアは 6 週間の中で 2 週間、そのうち 1 週間は第 1 担当者として、もう 1 週間は第 2 担当者として運用業務に注力することになります。
Q : エンジニアが 12~16 人いれば、開発チームが作成したアプリケーションすべてを確実にサポートできることになりますよね?
実はその答えはノーです。経験上、SRE チームが効率的に管理できるアプリケーションやサービスの数には明白な認知限界があることがわかっています。
個々のエンジニアが、それぞれのアプリケーションの稼働中に発生したトラブルに対応、診断して解決へと導くには、各アプリケーションのことを十分に知っておく必要があります。
したがって、複数のアプリケーションに対する同時サポートを簡素化するには、その複数のアプリケーションをできるだけ似たようなものにしておくとよいでしょう。共通のパターンやバックエンド サービスを使うように設計するとともに、ロールアウトやモニタリング、アラートなどの運用作業は共通のツールを使って標準化し、デプロイのスケジュールも同じようにしておくのです。もっとも、こうすることでアプリケーションあたりの認知的負荷は軽減できますが、なくなるわけではありません。
十分な人数の SRE を確保できたときは、2 チーム制にして(ここでも 2×6 という最低限の配属人数は守りましょう)、それぞれ異なる分野を担当させることも検討しましょう。
Google の場合、1 つの SRE チームがフロントエンドとバックエンドに分かれ、システムの規模が大きくなるにつれて、それぞれがフロントエンドのみ、バックエンドのみをサポートすることも珍しくありません(このようなチームを私たちは “mitosis” と呼んでいます)。
SRE チームがサポートできるサービスの上限は、以下のような要因によって大きく変わってきます。
サービスがきちんと稼働し続けるために必要な通常の運用タスク。たとえば、リリース、バグ フィックス、緊急性のないアラートやバグなどがこれに相当します。自動化することで、こうしたタスクは(なくすことはできないものの)軽減できるでしょう。
予定外で重要度の低いリクエストによる「割り込み」。これを減らそうと努力しても無駄であることがわかっています。一番効率的な対処法は、頻繁にやって来るリクエストの 50~70 % をセルフサービス ツールに任せることです。
緊急アラートへの対応、インシデント管理、その後のフォローアップ。これらに割く時間を減らす一番の方法は、サービスの信頼性を高め、アラートの精度を調整することです(アラートが発動したときは、サービスで実際に起こっている問題をきちんと示すようにするとよいでしょう)。
Q : 6 週間のうち 4 週間は SRE が運用作業を行っていないことになります。その時間を使って、SRE チームがサポートするサービスの量を増やせないでしょうか?
できないことはないですが、そのような行為は、Google では「種トウモロコシを自ら食べてしまうようなもの」と見なされます。機械ができることはすべて機械にやらせることがゴールです。それを実現するには、SRE に余裕を持ってもらい、サービスの新たな自動化といったプロジェクトに取り組んでもらいましょう。
経験上、50 % という運用作業のしきい値をチームが超えると、すぐに坂道を下って 100 % 運用となってしまいます。こうした状況に陥ると、今後発生するインシデントの頻度や時間、影響などをエンジニアの努力によって削減することが難しくなり、中長期的な運用上のメリットをもたらすエンジニアリングの恩恵を得られなくなります。SRE チームを運用でほぼフル稼働させてしまうと、エンジニアの設計や開発スキルによって得られる利点を逃してしまうのです。
特に注意していただきたいのは、SRE のエンジニア プロジェクトが上に挙げたような要因に対応し、運用負荷を軽減できる点です。上記の要因こそ、SRE チームがサポートできるサービスの数に上限があることの理由なのです。
ここまで読めば、SRE チームに新たなサービスを担当してもらいたいと思いつつも、実際には継続してサポートしてもらうのが難しいことがおわかりいただけるのではないでしょうか。
SRE のサポートに限界が来たらどうするのか
Google の場合、SRE がサポートしていないサービスは、原則として開発を担当したチームがサポートすることになっています。新しいアプリケーションを開発するのに十分な開発者がいるのであれば、サポートする開発者も十分いるだろう、というのが Google の考えなのです。Google の開発者は、モニタリングやロールアウト、インシデント管理を行うにあたって担当 SRE と同じツールを使うことが多いため、運用サポートの負荷も SRE と似通っています。
いずれにしても、Google ではアプリケーションを作成した開発者にしばらくサポートを直接担当してもらいたいと考えています。そうすることで、お客様がどのような経験をされているのかを開発者も実感できます。開発者がそのとき得た情報は、のちに SRE がサービス担当者として加わった際にも役立ちます。
Q : では、開発者に作ってもらいたいと考えている次のアプリケーションの扱いはどうしましょう? 現在のアプリケーションをサポートすることで手一杯なのではないですか?
確かにそうかもしれません。過度のアラートや自動化不足により、稼働中のアプリケーションの運用負荷が高くなっている可能性はあります。しかし、このことで開発チームには、よりサポートしやすいアプリケーションを作ることに時間を費やそうという実用的な動機が生まれます。サポートしやすいアプリケーションの開発は、アラートを調整し、自動化に開発時間を割き、機能変更のスピードを落とすことなどによって実現できます。
開発者が運用業務で手一杯になった場合でも、SRE が運用の専門知識や開発力を提供することで、何とか管理可能なレベルまで開発者の負荷を下げることができるかもしれません。ただし、SRE がサービスの運用責任を負うことになってはいけません。基本的な問題の解決にはつながらないためです。
1 つのチームがアプリケーションを開発し、別のチームが運用業務を引き受けると、モラル ハザードが発生します。開発スピードを上げたいと考えている開発者は、たまにメモリ不足でサーバーの再起動が必要になるようなちょっとしたバグを探し出してやっつけることには興味がありません。一方、運用チームはその再起動を 1 日に何度も実行するために、そのつどページャーで呼び出されるのです。
運用チームにとっては、彼らの睡眠を妨げるバグの修復こそ大切なことなのです。当然のことながら、開発者が自分の開発したシステムの運用まで担当すると、彼ら自身もサポートしやすいシステムを作ることに時間を費やしたいと思うようになります。後で説明しますが、これは SRE チームに自身のアプリケーションをサポートするよう説得する際にも重要なことなのです。
どのアプリケーションをサポートするべきか
SRE がサポートするアプリケーションに優先順位を付ける最も簡単な方法は、売上げや事業の重要度に応じて決めることです。つまり、サービスがダウンするとどうなるかを考えるのです。結局のところ、SRE チームに自社サービスをサポートしてもらうことで、サービスの信頼性や可用性が向上するのですから。
Q : いい考えだと思います。つまり、ビジネスへの影響度に応じて優先順位を付ける方法が常に正しいということですよね?
そうとも限りません。実際にはあまりサポートの必要がないサービスも存在するからです。(分散キーバリュー ストアのように)成熟しており、かつ単純で、更新の頻度も高くないインフラ サービスが良い例です。
このようなサービスは変更されることがほとんどないので、自発的に壊れる可能性も低いのです。そのサービスがユーザー向けアプリケーションと重要な依存関係にあったとしても、SRE が専属でサポートするほどではないでしょう。むしろ、サービスの開発者がページャーを持ち、たまに発生する運用作業を担当するようにしてください。
Google では、SRE チームが注力する分野は以下の 7 つだと考えています。これらは、開発者が通常はあまり注力しない分野です。
モニタリングと測定基準 :
たとえば、レスポンスのレイテンシ、エラー、未対応となっているクエリの率、リソースの利用率がピークに達しているかどうかなどを検知することです。
緊急対応 :
交代でオンコールに対応することや、トラフィックが落ちたことの検知、第 1 担当者や第 2 担当者およびエスカレーション、作戦を練ること、“
Wheel of Misfortune
”(不運のルーレット)などです。
キャパシティ プランニング :
四半期ごとの予測や、突然の持続的なスパイクへの対応、稼働率向上プロジェクトの実施などです。
サービス速度の上げ下げ :
さまざまな場所で稼働しているサービスの場合、(エンドユーザーのレイテンシを低減するなどの理由から)場所に応じて対応速度を上げたり下げたりするスケジュールの計画を立て、そのプロセスを自動化することでリスクや運用負荷を軽減させます。
変更管理 :
カナリア リリース、1 % experiments、ローリング アップグレード、不具合発生時の迅速なロールバック、エラー バジェットの査定などです。
パフォーマンス :
ストレス テストや負荷テスト、リソース利用の効率性監視と最適化のことです。
データの完全性 :
再構成できないデータを、読み込み時に復元性かつ可用性の高い状態で保存しておくこと。これには、バックアップから迅速に復元できるようにすることも含まれます。
「緊急対応」と「データの完全性」を除き、これらの専門分野によって Google のキーバリュー ストアが利益を得ることはありませんし、開発者の代わりに SRE がサポートを担当することで得られる限界利益も大したことはないというのが実情です。
一方、SRE のサポート能力をこうした分野に費やすことで得られる機会費用は大きく、他のアプリケーションも SRE の専門分野によってより多くの利益を享受できる可能性があります。
もう 1 つ、SRE の専門性が必要ないインフラ サービスに対して SRE が責任を持つ場合があります。それは、すでに稼働しているサービスと重要な依存関係にある場合です。このようなケースでは、サービスの変更に対する可視性や管理性を SRE の側で確保しておいたほうがずっとよいのです。
この投稿記事のパート 2 では、SRE がサポートするほうがよいと判断されたビジネス上の重要なサービスを、Google の SRE がどうやって担当しているのか、また担当すべきかどうかをどうやって判断しているのかについて紹介します。
* この投稿は米国時間 6 月 23 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer
カナリアのおかげで命拾い : CRE が現場で学んだこと
2017年4月18日火曜日
信頼性の高いソフトウェアのリリースでは、何かおかしなことが起こったときにロールバックできることが何より重要です。そしてその方法は
前回の投稿
で説明しました。
ひとたびロールバックを身につけてしまえば、その次は、そもそも何かおかしなことが起こり始めていることをどうやって検知するかを知りたいと思うはずです。その方法の 1 つが、今回のテーマであるカナリア リリースです。
Photo taken by
David Carroll
カナリア リリースのコンセプトは、1913 年に生理学者の
John Scott Haldane
氏が、一酸化炭素を検出するためにカゴの中の鳥を炭鉱に連れて行ったことが始まりです。かよわい鳥は人間よりもこの無臭ガスに敏感で、ガス漏れが起きているとすぐに木から落ちてしまうため、それが炭鉱員にとってその場から離れるべきサインとなるのです。
ソフトウェアにおけるカナリアは通常、バイナリや設定のロールアウトなど、何らかの設定を更新してライブ稼働した際にトラフィックを受信する最初のインスタンスのことを指します。新しいリリースは、まずカナリアのみに行くことになるわけです。
カナリアが実際のユーザー トラフィックを処理するという点が肝で、もし不具合があった場合は実際のユーザーが影響を受けます。そのため、カナリア リリースはデプロイ プロセスの最初のステップであるべきで、テストの最終ステップになっては意味がありません。
カナリア リリースを実装するにあたって最初のステップとなるのは、リリース エンジニアが新しいバイナリのリリースをカナリア インスタンスに対して開始する手動プロセスです。
その後、エンジニアはカナリアを監視し、エラーやレイテンシ、負荷が増加していないことを確認します。すべてうまく進んでいるようであれば、カナリア以外の稼働インスタンスに対してもリリースを開始します。
ところが、Google の SRE チームはこのやり方に疑問を呈しました。モニター グラフを手動で監視するだけでは、新しいリリースのパフォーマンス上の問題やエラー率の増加を検知する際の信頼性が十分ではないというのです。
ほとんどのリリースがうまくいっている場合、リリース エンジニアは問題がないことに慣れてしまい、低レベルの問題が発生してもモニターの異常をノイズだと暗黙的に合理化してしまうのです。実際、不具合のあったリリースを内部事後分析すると、根本的な原因が「リリース エンジニアが気にするほどカナリアのグラフが動いていなかったため」だったことが何度かありました。
そこで Google では自動分析に移行しました。これにより、カナリアのロールアウト サービスがカナリアのタスクを測定し、エラーやレイテンシ、負荷が上昇したことを自動的に検知、ロールバックも自動で行うようになりました(もちろん、これは
ロールバックが安全に実施できる
場合にのみ適用されます)。
もしリリース時にカナリアを実装するのであれば、リリースの問題が見えやすくなるように工夫してください。カナリア タスクにおいてどのようにフォールト トレランスを実装するか、入念に考えるようにしましょう。カナリアがクエリに対して最善の力を尽くすようにしてもいいですが、内部エラーや依存しているサービスからのエラーが発生したときは、問題が生じたことがモニターに「大きな声で鳴いて」表示されるようにしなければなりません(ウェールズの炭鉱員がカナリアを有毒ガスに耐えられるように育てなかったり、カナリアに小型ガス マスクを装着しなかったりしたことには、正当な理由があるのですから)。
クライアントでのカナリア リリース
クライアント ソフトウェアをリリースする場合は、カナリア リリースのメカニズムがクライアントの新バージョンに必要であり、次の質問に答えられるようにしておかなくてはなりません。
ごく少数のユーザーにだけ新バージョンをデプロイするにはどうすればよいのか。
新バージョンがクラッシュを繰り返したり、トラフィックを落としたり、ユーザー エラーを表示したりしたときは、どうやって検知するのか(クエリが発生していないことに対するモニター音はどうするのか)。
2 の解決策は、クライアントが自らバックエンド サービスにクライアントの存在を識別させることです。そこにクライアントの OS やアプリケーションのバージョン ID など、各リクエストの情報が含まれていることが理想です。また、サーバーにこれらの情報をログ化させます。クライアントが自らの存在を明確にカナリアとして識別させることができれば、それに越したことはありません。
そうすれば、クライアントの情報を異なる監視測定基準セットにエクスポートできます。クライアントがクエリ送信できていないことを検知するには、一般的に 1 日または 1 週間の特定の時間の着信トラフィックとして妥当な最も低い量を把握しておき、着信トラフィックがそれ以下になった場合にアラートを発するようにしましょう。
高可用性システムのカナリアに対するアラートのルールは通常、評価期間(問題発生となり、モニターがそのことを音で知らせるまでの時間)を主要システムより長めにしてあります。というのも、トラフィック量が少ないため、標準の通知がノイズとなってしまうからです。いくつかのサービス インスタンスが再スタートしたといったような比較的無害の問題によって、簡単にカナリアのエラー率が上がり、通常アラームのしきい値を超えてしまうのです。
リリースは通常、一部のアクティブ ユーザーを除き、幅広いタイプのユーザーをカバーするようにしなくてはなりません。Android クライアントであれば、Google Play Store が
アプリケーション パッケージ ファイル
(APK)の新バージョンを(実質無作為の)一部ユーザーに向けてデプロイすることを許可します。これは、国ごとに行うことが可能です。
ただし、この手法には制限やリスクがあります。以下では、Android APK のリリースについて考えてみます。
ウェブ クライアント
エンドユーザーが、アプリではなくデスクトップやモバイル ウェブを介してサービスにアクセスする場合は、実行される内容を制御しやすくなります。
UI が JavaScript で管理されている一般的なウェブ クライアントは制御がとても簡単で、アップデートした JavaScript のリソースを、ページが読み込まれるたびにクライアントに配信することも可能です。
しかし、JavaScript やそれに似たリソースをクライアント サイドにキャッシュすると、それ自体はサービス負荷やユーザーのレイテンシと帯域の消費を削減できるために便利なのですが、変更に不具合があったときにはロールバックが難しくなります。前回の投稿で説明したように、簡単で迅速なロールバックを阻害するようなものは、すべて問題なのです。
その解決策の 1 つは、JavaScript ファイルをバージョン付けすることです(最初のリリースを /v1/ のディレクトリに入れ、2 番目のリリースを /v2/ に入れるといった具合です)。そうすれば、ロールアウトでは単にルート ページ内のリソース リンクが変更され、新(または旧)バージョンを参照するようになります。
Android APK のリリース
Android アプリの新バージョンをロールアウトする際は、Play Store 内で
段階的にロールアウト
されたものを利用している既存ユーザーのうち、一定の割合のユーザーに対して行うとよいでしょう。そうすることで、ごく一部の既存ユーザーに新しいリリースを試してもらえます。その後、このリリースに自信が持てるようになれば、徐々に他のユーザーにもロールアウトすればよいのです。
一部ユーザーにリリースする方法では、新リリースを受けることができるユーザーの割合を示します。対象となるユーザーがモバイル デバイスを使って更新の有無を Play Store に問い合わせると、アプリに更新があることがわかり、更新が始まります。
ただし、この方法には以下の問題があります。
更新の対象となるユーザーが、実際にいつ更新を確認するかはわかりません。ユーザーが適切にネット接続できる状況にあれば、通常は 24 時間以内でしょう。ただ、携帯電話や WiFi データ サービスが低速だったり、バイト単位の費用が高額だったりするような国では、そうとも限りません。
ユーザーがモバイル デバイスで更新を許諾するかどうかもわかりません。特に新リリースにおいて追加の許可が必要な場合は、ここが課題となります。
上述したカナリア リリースの手順に従えば、カナリアとなるアクティブ ユーザーの母数が増え、新しいトラフィックの特徴が明確になった時点で、新しいクライアント リリースに問題があるかどうかを判断できます。エラー率は上がったのか、レイテンシはどう変化したか、サーバーへのトラフィックが理由もなく急増していないか、などです。
バージョン v に不具合があるとわかっているアプリをうまく修復する方法は(ロールバックできない場合)、リリース v+1 内にバージョン v-1 というコード部分を構築してリリースし、すぐに 100 % 持ち直すことです。こうすることで、コード内に見つかった問題を修復する時間のプレッシャーから解放されます。
リリースの割合を段階的に増やす
新しいバイナリやアプリを徐々にリリースする場合は、アプリのリリースをどのような割合で増やしていくのか、いつ次に進めばよいのかを決めなくてはなりません。その際、次の点を考慮しましょう。
(カナリアの)最初の段階では、監視やロギングによって問題が明確になるように十分なトラフィックを生成する必要があります。ユーザー数がどれだけなのかにもよりますが、だいたい全ユーザーの 1 % ~ 10 % 程度と考えるとよいでしょう。
各段階で手動の作業が数多く発生し、全体のリリースは遅れます。1 日 3 % ずつ段階的に作業すると、完全にリリースするまで 1 か月かかります。
一気に割合を増加させると(たとえば 10 % から 100 % にするなど)、小規模なトラフィックでは生じなかったトラフィックの大問題が発生する可能性があります。こうした懸念がある場合は、各段階で更新をかけるユーザー数を 2 倍以上増やさないようにしましょう。
新バージョンに問題がないときは、大半のユーザーにすぐにでも使ってもらいたいと考えるのが普通です。ロールバックする場合は、新しいリリースを出すときよりも 100 % 速くロールバックするようにしましょう。
トラフィックのパターンは、通常は日中に最も混雑するなど 1 日を通して変化するものです。そのため、リリース後のトラフィック負荷のピークを把握するには、最低でも 24 時間が必要です。
モバイル アプリの場合、ユーザーが新リリースを取り入れ、有効にして使い出すまでに時間がかかると考えましょう。
Android アプリのアップデートを数日以内に大半のユーザーにロールアウトしたいと考えているのであれば、Play Store の
段階的アップデート
を利用するのがよいかもしれません。10 % に対するロールアウトから開始し、次に 50 % へと増加させ、最後に 100 % にするといった具合です。
次のリリースまで最低 24 時間は空けるようにし、次のステップに進むまでモニターやログを確認するようにしてください。そうすれば、最初のリリースから 72 時間以内にほとんどのユーザーが新しいリリースを取り入れ、大抵の問題は手が終えなくなる前に検知できるはずです。
もしリリースによってサービスのトラフィックが急激に増える危険性があるとわかっているのであれば、10 %、25 %、50 %、100 % といった順番でリリースするか、さらに細かい割合で増加させるようにしましょう。
サービス インスタンスを直接アップデートする内部バイナリ リリースの場合は、1 %、10 %、100 % の順で実施してもよいでしょう。1 % のリリース時には、新リリースに全体的なエラーがないか確認します。たとえば、レスポンスの 90 % がエラーになるようなことはないか、といったことです。
10 % のリリースでは、さらに小さなエラーやレイテンシの増加を見つけ出し、全般的なパフォーマンスに違いが出ないかを確認します。
そして通常は、3 回目で完全にリリースします。パフォーマンスに敏感なシステムの場合、つまり通常 75 % 以上の容量で運用しているような場合ですが、ここに 50 % という段階を追加し、パフォーマンスが落ちていないか詳細に確認しましょう。システムの信頼性に対する目標値が高ければ高いほど、それぞれのステップで問題を検知するのに要する時間は長くなります。
理想的なマーケティングに沿ったリリースのシーケンスが 0 - 100 だとして(つまり全員に新機能を同時リリースします)、信頼性を担当するエンジニアの理想的なリリースのシーケンスが 0 - 0 なのだとしたら(何も変更しなければ問題は起こらないためです)、アプリの正しいリリースのシーケンスは交渉によって決まります。
以上が考慮すべきポイントです。お互いにとって納得のいくロールアウトの方法を決める際に、これらのポイントが理にかなった方法として役に立つことを願っています。
下のグラフは、8 日間のリリース期間という枠の中で、それぞれの戦略がどう作用するかを示しています。
まとめ
私たち Google は、どんな状況でもうまくいくようなソフトウェア リリースの哲学を生み出しました。それは次のとおりです。
ロールバックは早期に行い、頻繁に行うこと : この哲学に従うようにサービスを持っていけば、サービスの平均修復時間(MTTR)を削減できます。
ロールアウトではカナリアを使うこと : どれだけテストや QA を実施したとしても、実稼働のトラフィック上でバイナリ リリースに問題が見つかることは少なくありません。効果的なカナリア戦略を取り入れ、正しく監視することで、問題の平均検知時間(MTTD)が短縮でき、影響を受けるユーザー数も大幅に削減できます。
とはいえ、結局のところ、最も優れたリリースは、その機能がバイナリのロールアウトとは関係なく独自に有効となることかもしれません。この件については、またの機会に。
* この投稿は米国時間 3 月 31 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer
信頼性の高いリリースとロールバック : CRE が現場で学んだこと
2017年4月10日月曜日
編集部注 :
サービス停止の原因としてよくあることの 1 つに、サービス バイナリの新リリースが挙げられます。どれだけテストや QA をきちんと行っていても、一部のバグは、その影響を受けるコードが稼働するまで表面に出てこないものなのです。
Google の Site Reliability Engineering
(SRE)チームは、リリースに起因するサービス停止を長きにわたって数多く見てきており、今ではすべての新リリースに 1 つ以上のバグが含まれていると考えています。
ソフトウェア開発者は皆、自分のサービスに新しい機能を追加したいと思うものです。とはいえ、すべてのリリースには不具合のリスクがつきものです。変更個所をカバーするユニット テストや機能テストを追加し、システムのパフォーマンスに何か重大な影響が出ないか把握するために負荷テストを実施したとしても、本番環境でのトラフィックに驚かされることがあるのです。そのときの驚きは、通常あまり気持ちのいいものではありません。
新しいバイナリのリリースによってサービスが停止するというのは、よくあることです。システムの信頼性を担当するエンジニアの観点から見ると、このときの対応には次の 3 つの基本的なタスクが必要となります。
新しいリリースが実際にいつ壊れたのかを把握する
壊れたリリースから、修正された「であろう」リリースへとユーザーを安全に移行させる
最初の段階で壊れたリリースの影響を受けるクライアントの数を抑えるようにする(「カナリア リリース」を実施する)
今回の分析では、
nginx
などのロード バランサの背後にあるマシンや VM で多くのサービス インスタンスを稼働させるとともに、新しいバイナリのためにサービスをアップグレードするときは各サービス インスタンスを一度停めてからスタートする必要があると仮定します。
また、Stackdriver のようなツールを使用してシステムを監視し、内部のトラフィックやエラー率を計測することも前提としています。このようなモニタリング ツールがない場合は、信頼性について意味のある議論をすることが困難なのです。
SRE の書籍
に書かれている “
Hierarchy of Reliability
”(信頼性の階層)によると、モニタリングは信頼性の高いシステムにとって最も基本的な要件です。
検知
不具合のあるリリースにとっていちばん好都合なケースは、そのリリースによってサービス インスタンスが再スタートすることです。そうすると、不適切に処理されたリクエストの大半は HTTP 502 などのエラーを出すか、レスポンスのレイテンシが非常に高くなります。この場合、サービス インスタンスのロールアウトが進むにつれて全体のサービス エラー率が高まるので、リリースに問題があると気づくのです。
もっと微妙なのは、新しいバイナリが比較的少ない一部のクエリに対してエラーを返すケースです。たとえば、ユーザー設定の変更リクエストや、正当な理由が
ある
にしろ
ない
にしろ、名前にアポストロフィーが付いているユーザーだけがエラーになったとしましょう。こうした不具合は、サービス インスタンスの大半がアップグレードされ、総合的なモニタリングを実施して初めてわかることです。そのため、サービス インスタンスのエラーやレイテンシのサマリーをバイナリ リリースのバージョンごとに分類しておくと便利です。
ロールバック
新しいバイナリやイメージをサービスにロールアウトする前に、自分自身に問いかけてみてください。「このリリースに致命的なバグや気が滅入るようなバグ、迷惑なバグがあったらどうするべきか」と。このようなことが起こる可能性があるから考えるのではなく、早かれ遅かれこのような事態は避けられないことだとして、サービスが炎上する前に綿密な計画を立てておいたほうがよいのです。
バグが見つかっても特にそれが致命的ではないときは、すぐにパッチを作成し前に進みたいと思うものです。つまり、バグを修正するための最小限のコードを元のリリースに追加し、そこから新しいリリースを作るということです(修正の「選り好み」)。
ただし、この方法は一般的にあまりお勧めしません。特に、そのバグがユーザーにも見えるようなものだったり、(たとえばクエリのリソース コストが 2 倍になるなど)内部的に重大な問題を起こしていたりする場合は推奨できません。
なぜ前に進んではいけないのでしょうか。それは、ソフトウェア開発者の身になって考えてみると理解できるはずです。
あなたの机の横で飛び跳ねている上司の血圧が見るからに上がっていき、修正版がリリースされるのはいつだと聞いてきます。会社のプロダクト ディレクターがその上司に対し、ユーザーから苦情が来ているとうるさく言っているためです。このままでは毎分 1,000 人単位のユーザーがサービス エラーに遭遇することになるので、あなたには修正版に向けたコーディングを最速で行うことが求められます。このようなプレッシャーの中では、コーディングやテスト、デプロイにおいて間違いが発生することはほとんど避けられないでしょう。
このような状況を Google で何度も見てきました。前に進むべく急いでデプロイした修正版が元の問題を修正できなかったり、さらに状況を悪化させたりといったことがありました。
万が一、その修正版で問題が解決しても、システム内に潜んだ別のバグが後になって見つかることもあります。つまり、よくわかっている状態から、定期的に QA テストを実施する対象となっていない、いわば野生の世界へと引きずり込まれていくのです。
Google には「ロールバックは普通だ」という哲学があります。新しいリリースにエラーが見つかったりエラーが疑われたりすると、リリースを担当したチームは最初にロールバックを行い、次に問題を調査します。
ロールバックをお願いすることが、リリース担当チームや、バグを含んだコードを書いた開発者への攻撃だと見なされることはありません。むしろ、ユーザーにとってシステムをできるだけ信頼できるものにするための正しい行為だと考えられているのです。発見された問題がロールバックの変更リストに記述されている限り、「なぜこの変更をロールバックしたんだ?」などと言う人は誰もいません。
そこで、ロールバックを成功させるには、次のような点を暗黙の了解としておくべきでしょう。
簡単に実行できる
低リスクであると確信できる
この 2 つ目の項目を実現するにはどうすればよいのでしょうか。
ロールバックのテスト
もし数週間にわたってロールバックしていないのであれば、とにかくロールバックしてみましょう。互換性のないバージョンや、故障した自動化 / テストなどの落とし穴をすべて見つけられるようにするのです。
ロールバックがうまくいけば、すべてのログやモニタリングを確認したうえで再度前に進みましょう。ロールバックがうまくいかない場合は、前に進んで不具合を取り除き、ロールバックが失敗した原因を突き止めることに全力を尽くします。新しいリリースが火を噴いてサービスが強制的に停止したからといって、よくわかっている元のリリースに戻ろうとするのはいただけません。それよりも、新しいリリースがきちんと動いている間に不具合を見つけるほうが、ずっといいのです。
互換性のない変更
ロールバックが簡単にいかないことも必ずあります。たとえば、新しいリリースにてアプリのデータベース内に(新しいコラムといった)スキーマの変更が必要となるケースです。ここで危険なのは、新しいバイナリをリリースし、データベースのスキーマをアップグレードした後で、ロールバックが必要となるようなバイナリの問題が見つかることです。こうなると、新しいスキーマを受け付けず、テストもされていないバイナリが存在しているだけとなります。
このとき推奨される方法としては、機能なしのリリースを出すことです。バイナリのバージョン v から開始し、新しいデータベースのスキーマを安全に扱えること以外は v とまったく同じである新しいバージョン v+1 を構築しましょう。新しいスキーマを活用する新機能はバージョン v+2 に入ります。これにより、ロールアウトの計画は以下のようになります。
バイナリ v+1 をリリースする
データベースのスキーマをアップグレードする
バイナリ v+2 をリリースする
これで、新しいバイナリのいずれかに問題があった場合、スキーマをロールバックすることなく前のバージョンにロールバックできるようになります。
ここで、より一般的な問題での特別なケースについて話しましょう。サービスの依存関係をグラフ化し、直接的な依存関係をすべて特定するときには、依存関係のいずれかが突然オーナーによってロールバックされた場合にどうするか計画を立てる必要があります。依存関係にあるサービス S のバージョンが r から r+1 になってからリリースしようとしているのであれば、S がバージョン r+1 でずっと「とどまる」ことを確認しておかなくてはなりません。
考えられる方法としては、どんなサービスもひとつ前のバージョンにロールバックする可能性があるといったエコシステムを想定することです。つまり、この場合は自分のサービスが r+1 の機能に依存するバージョンへと移る前に、S がバージョン r+2 になるのを待つということです。
まとめ
今回わかったことは、リリースに対応するロールバックの準備ができていない限り、優れたリリースにはならないということです。とはいえ、不具合のあるリリースによってサービス全体が影響を受けるのを回避しつつ、その中でロールバックするタイミングを見極めるにはどうすればよいのでしょうか。
この投稿のパート 2 では、カナリア リリース戦略を紹介します。これは、新しいリリースにおける稼働トラフィックのほとんどを危険にさらすことなく、実際の稼働段階での問題を検知する方法です。
* この投稿は米国時間 3 月 24 日、Customer Reliability Engineer である Adrian Hilton によって投稿されたもの(投稿は
こちら
)の抄訳です。
- By Adrian Hilton, Customer Reliability Engineer
12 か月間のトライアル
300 ドル相当が無料になるトライアルで、あらゆる GCP プロダクトをお試しいただけます。
Labels
.NET
.NET Core
.NET Core ランタイム
.NET Foundation
#gc_inside
#gc-inside
#GoogleCloudSummit
#GoogleNext18
#GoogleNext19
#inevitableja
Access Management
Access Transparency
Advanced Solutions Lab
AI
AI Hub
AlphaGo
Ansible
Anthos
Anvato
Apache Beam
Apache Maven
Apache Spark
API
Apigee
APIs Explore
App Engine
App Engine Flex
App Engine flexible
AppArmor
AppEngine
AppScale
AprilFool
AR
Artifactory
ASL
ASP.NET
ASP.NET Core
Attunity
AutoML Vision
AWS
Big Data
Big Data NoSQL
BigQuery
BigQuery Data Transfer Service
BigQuery GIS
Billing Alerts
Bime by Zendesk
Bitbucket
Borg
BOSH Google CPI
Bower
bq_sushi
BreezoMeter
BYOSL
Capacitor
Chromium OS
Client Libraries
Cloud API
Cloud Armor
Cloud Audit Logging
Cloud AutoML
Cloud Bigtable
Cloud Billing Catalog API
Cloud Billing reports
Cloud CDN
Cloud Client Libraries
Cloud Console
Cloud Consoleアプリ
Cloud Container Builder
Cloud Dataflow
Cloud Dataflow SDK
Cloud Datalab
Cloud Dataprep
Cloud Dataproc
Cloud Datastore
Cloud Debugger
Cloud Deployment Manager
Cloud Endpoints
Cloud Firestore
Cloud Foundry
Cloud Foundry Foundation
Cloud Functions
Cloud Healthcare API
Cloud HSM
Cloud IAM
Cloud IAP
Cloud Identity
Cloud IoT Core
Cloud Jobs API
Cloud KMS
Cloud Launcher
Cloud Load Balancing
Cloud Machine Learning
Cloud Memorystore
Cloud Memorystore for Redis
Cloud monitoring
Cloud NAT
Cloud Natural Language API
Cloud Networking
Cloud OnAir
Cloud OnBoard
cloud Pub/Sub
Cloud Resource Manager
Cloud Resource Manager API
Cloud SCC
Cloud SDK
Cloud SDK for Windows
Cloud Security Command Center
Cloud Services Platform
Cloud Source Repositories
Cloud Spanner
Cloud Speech API
Cloud Speech-to-Text
Cloud SQL
Cloud Storage
Cloud Storage FUSE
Cloud Tools for PowerShell
Cloud Tools PowerShell
Cloud TPU
Cloud Translation
Cloud Translation API
Cloud Virtual Network
Cloud Vision
Cloud VPC
CloudBerry Backup
CloudBerry Lab
CloudConnect
CloudEndure
Cloudflare
Cloudian
CloudML
Cluster Federation
Codefresh
Codelabs
Cohesity
Coldline
Colossus
Compute Engine
Compute user Accounts
Container Engine
Container Registry
Container-Optimized OS
Container-VM Image
Couchbase
Coursera
CRE
CSEK
Customer Reliability Engineering
Data Studio
Databases
Dbvisit
DDoS
Debugger
Dedicated Interconnect
deep learning
Deployment Manager
Developer Console
Developers
DevOps
Dialogflow
Disney
DLP API
Docker
Dockerfile
Drain
Dreamel
Eclipse
Eclipse Orion
Education Grants
Elasticsearch
Elastifile
Energy Sciences Network
Error Reporting
ESNet
Evernote
FASTER
Fastly
Firebase
Firebase Analytics
Firebase Authentication
Flexible Environment
Forseti Security
G Suite
Gartner
gcloud
GCP
GCP Census
GCP 移行ガイド
GCP 認定資格チャレンジ
GCPUG
GCP導入事例
gcsfuse
GEO
GitHub
GitLab
GKE
Go
Go 言語
Google App Engine
Google Apps
Google Certified Professional - Data Engineer
Google Cloud
Google Cloud Certification Program
Google Cloud Client Libraries
Google Cloud Console
Google Cloud Dataflow
Google Cloud Datalab
Google Cloud Datastore
Google Cloud Endpoints
Google Cloud Explorer
Google Cloud Identity and Access Management
Google Cloud INSIDE
Google Cloud INSIDE Digital
Google Cloud INSIDE FinTech
Google Cloud Interconnect
Google Cloud Launcher
Google Cloud Logging
Google Cloud Next '18 in Tokyo
Google Cloud Next '19 in Tokyo
Google Cloud Platform
Google Cloud Resource Manager
Google Cloud Security Scanner
Google Cloud Shell
Google Cloud SQL
Google Cloud Storage
Google Cloud Storage Nearline
Google Cloud Summit '18
Google Cloud Summit ’18
Google Cloud Tools for IntelliJ
Google Code
Google Compute Engine
Google Container Engine
Google Data Analytics
Google Data Studio
Google Date Studio
Google Deployment Manager
Google Drive
Google Earth Engine
Google Genomics
Google Kubernetes Engine
Google maps
google maps api
Google Maps APIs
Google Maps Platform
Google SafeSearch
Google Service Control
Google Sheets
Google Slides
Google Translate
Google Trust Services
Google VPC
Google マップ
Google 公認プロフェッショナル
GoogleNext18
GPU
Gradle
Grafeas
GroupBy
gRPC
HA / DR
Haskell
HEPCloud
HIPAA
Horizon
HTCondor
IaaS
IAM
IBM
IBM POWER9
icon
IERS
Improbable
INEVITABLE ja night
inevitableja
InShorts
Intel
IntelliJ
Internal Load Balancing
Internet2
IoT
Issue Tracker
Java
Jenkins
JFrog
JFrog Artifactory SaaS
Jupiter
Jupyter
Kaggle
Kayenta
Khan Academy
Knative
Komprise
kubefed
Kubeflow Pipelines
Kubernetes
KVM
Landsat
load shedding
Local SSD
Logging
Looker
Machine Learning
Magenta
Managed Instance Group
Managed Instance Group Updater
Maps API
Maps-sensei
Mapsコーナー
Maven
Maxon Cinema 4D
MightyTV
Mission Control
MongoDB
MQTT
Multiplay
MySQL
Nearline
Network Time Protocol
Networking
neural networks
Next
Node
NoSQL
NTP
NuGet パッケージ
OCP
OLDISM
Open Compute Project
OpenCAPI
OpenCAPI Consortium
OpenShift Dedicated
Orbitera
Organization
Orion
Osaka
Paas
Panda
Particle
Partner Interconnect
Percona
Pete's Dragon
Pivotal
Pivotal Cloud Foundry
PLCN
Podcast
Pokemon GO
Pokémon GO
Poseidon
Postgre
PowerPoint
PowerShell
Professional Cloud Network Engineer
Protocol Buffers
Puppet
Pythian
Python
Qwiklabs
Rails
Raspberry Pi
Red Hat
Redis
Regional Managed Instance Groups
Ruby
Rust
SAP
SAP Cloud Platform
SC16
ScaleArc
Secure LDAP
Security & Identity
Sentinel-2
Service Broker
Serving Websites
Shared VPC
SideFX Houdini
SIGOPS Hall of Fame Award
Sinatra
Site Reliability Engineering
Skaffold
SLA
Slack
SLI
SLO
Slurm
Snap
Spaceknow
SpatialOS
Spinnaker
Spring
SQL Server
SRE
SSL policies
Stack Overflow
Stackdriver
Stackdriver Agent
Stackdriver APM
Stackdriver Debugger
Stackdriver Diagnostics
Stackdriver Error Reporting
Stackdriver Logging
Stackdriver Monitoring
Stackdriver Trace
Stanford
Startups
StatefulSets
Storage & Databases
StorReduce
Streak
Sureline
Sysbench
Tableau
Talend
Tensor Flow
Tensor Processing Unit
TensorFlow
Terraform
The Carousel
TPU
Trace
Transfer Appliance
Transfer Service
Translate API
Uber
Velostrata
Veritas
Video Intelligence API
Vision API
Visual Studio
Visualization
Vitess
VM
VM Image
VPC Flow Logs
VR
VSS
Waze
Weave Cloud
Web Risk AP
Webyog
Wide and Deep
Windows Server
Windows ワークロード
Wix
Worlds Adrift
Xplenty
Yellowfin
YouTube
Zaius
Zaius P9 Server
Zipkin
ZYNC Render
アーキテクチャ図
イベント
エラーバジェット
エンティティ
オンライン教育
クラウド アーキテクト
クラウド移行
グローバル ネットワーク
ゲーム
コードラボ
コミュニティ
コンテスト
コンピューティング
サーバーレス
サービス アカウント
サポート
ジッター
ショート動画シリーズ
スタートガイド
ストレージ
セキュリティ
セミナー
ソリューション ガイド
ソリューション: メディア
データ エンジニア
データセンター
デベロッパー
パートナーシップ
ビッグデータ
ファジング
プリエンプティブル GPU
プリエンプティブル VM
フルマネージド
ヘルスケア
ホワイトペーパー
マイクロサービス
まっぷす先生
マルチクラウド
リージョン
ロード シェディング
運用管理
可用性
海底ケーブル
機械学習
金融
継続的デリバリ
月刊ニュース
資格、認定
新機能、アップデート
深層学習
深層強化学習
人気記事ランキング
内部負荷分散
認定試験
認定資格
料金
Archive
2019
8月
7月
6月
5月
4月
3月
2月
1月
2018
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2017
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2016
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2015
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2014
12月
11月
10月
9月
8月
6月
5月
4月
3月
2月
Feed
月刊ニュースレターに
登録
新着ポストをメールで受け取る
Follow @GoogleCloud_jp