Stackdriver IRM のリリースと新たなパートナーシップ ―― インフラストラクチャのさらなる信頼性向上を目指して

Google Cloud Japan Team
※この投稿は米国時間 2018 年 10 月 11 日に Google Cloud blog に投稿されたものの抄訳です。
アプリケーションをいつも安心して使えるようにすることは、ソフトウェアを提供するすべての組織が解決しなければならない課題です。私たち Google が、SRE(Site Reliability Engineering)と呼ばれる方法論を生み出して実践しているのも、それが理由です。数十億のユーザーが安心して使えるサービスを私たちが構築し運用できるのは、SRE のプラクティスに従っているからです。
Google には社内外のサービスをサポートする 2,500 人ほどの SRE 担当者がいます。SRE の原則は、組織のユーザーにとって適切なサービス レベルの指標を確立するための拠りどころとなり、発生した問題を検出し修復するにあたって規範的な手順を提供します。また SRE の原則は、非難を伴わない事後分析などを通じて、継続的な改善の文化も生み出します。こうした SRE については、担当者の雇用方法を知りたい、SRE の原則を実践に移すツールを使いたい、より良い結果を達成したいといった問い合わせが多くの企業から寄せられています。
モニタリング、APM(Application Performance Management)、ロギングの各サービスからなる Google Stackdriver で私たちが目指しているのは、長年築き上げてきた、システムの信頼性に関するベスト プラクティスに基づいて、完成された管理ツールセットを提供することです。これらの Stackdriver ツールは、SRE の原則と、信頼性および可用性のさらなる向上という目標をベースに生み出されたものです。
私たちはこのたび、Google Cloud Platform(GCP)のもとで Stackdriver IRM(Incident Response and Management)のアルファ提供を開始し、システムのオブザーバビリティ(observabiliity; 可観測性)を大きく引き上げました。Stackdriver IRM は、インシデントの精査、理解、緩和、および修復に必要なツールを提供します。Stackdriver IRM のアルファ プログラムに参加をご希望の方は、こちらからサインアップしてください。
また、モニタリングおよび信頼性ツールセットの構築に有用な新しい統合サービスを提供するべく、Blue Medora や Grafana Labs と協力して作業を進めています。
システムの信頼性に光を当てる Stackdriver IRM
私たちがモニタリング ツールを進化させながら考えていることは、ユーザーができる限り簡単に SRE を導入して前に進めるようにしたいということです。組織に SRE を根づかせることは容易ではありませんが、Stackdriver IRM のようなツールは、SRE や、IT サービスを通じてユーザー エクスペリエンスを高める手法からインスピレーションを得ています。Stackdriver IRM は、基準に違反している指標や、アラートの状態を可視化します。Stackdriver IRM には、アラート ポリシー ドキュメントと、典型的なケースを処理する方法を示したガイダンスが組み込まれています。またインシデントと環境の状況に基づき、精査プロセスを加速させる重要情報にスポットライトを当てます。
Stackdriver IRM で得られるのは次のとおりです。
- 包括的なデータ収集とアナリティクスによるインシデントの徹底的なライフサイクル管理
- SRE の経験から生まれた緊急応答プロトコルに基づく効率的な多応答者インシデント管理のための体系化されたプロセス
- 知見を引き出し、重要情報にスポットライトを当てるとともに、精査プロセスを迅速化し、障害から復旧にかかる時間を短縮する最新 Stackdriver データの自動相関化
- 状況を重視し、事後分析生成プロセスを向上させるために頻繁に使われる非公式な慣習的手順(問題点の追跡手順など)の構造化
次の画面は、Stackdriver IRM においてインシデントに関する認識を段階的に深めていく場合の具体的な例です。
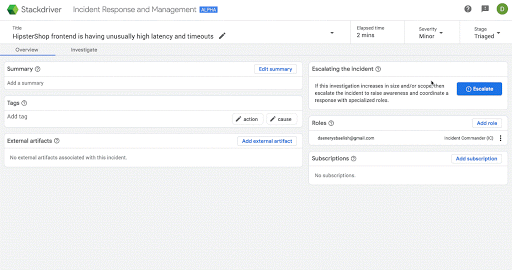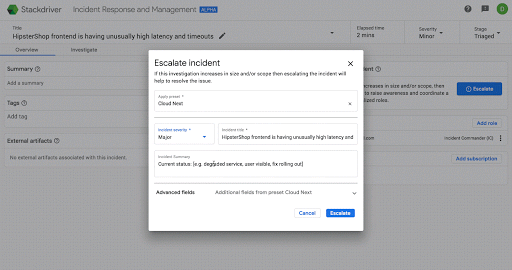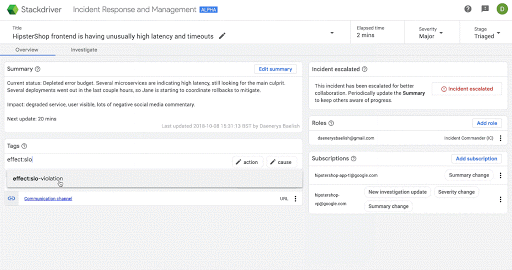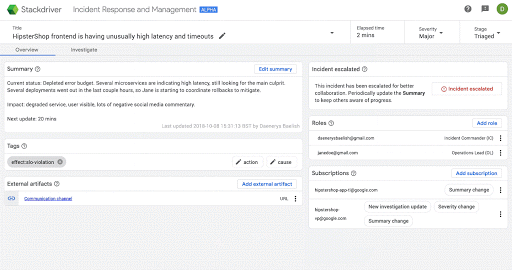
可視性や柔軟性の向上を支援する新しいパートナー
オープン クラウドの一部になるということは、ベンダーを選ばないということです。Stackdriver は柔軟で拡張性の高いプラットフォームであり、私たちはパートナーと協力しながらモニタリング データの可視化を支援することに取り組んでいます。分散インフラストラクチャにおいてサイトの信頼性と可用性を担当する IT チームは、問題の検出やトリアージの際の徹底した分析のために、広範なシグナルを収集する必要があります。しかし、インフラストラクチャにおけるパフォーマンス障害の原因はいつも自明だとは限らず、問題の徴候を知らせるシグナルはインフラストラクチャ、OS、ネットワーキング、サービス、アプリケーション レイヤなどさまざまな場所に散らばっています。
この難題を解決するべく、私たちは、クラウド環境やインフラストラクチャ、ネットワーク機器、データベース、ストレージ環境、基幹アプリケーションなどを含む広範なリソースの包括的な可観測機能を提供する Blue Medora と共同で作業を行っています。つまり、Stackdriver のモニタリング機能をより多くのリソースやワークロードに拡張し、状況を包括的に把握できるようにするわけです。Blue Medora のプラットフォームは、実行中のワークロードの下に隠れたスタックの幅広いオブザーバビリティを提供します。なお、この統合機能は現時点ではアルファ リリースです。関心のある方は、こちらのフォームに必要事項を入力してお送りください。
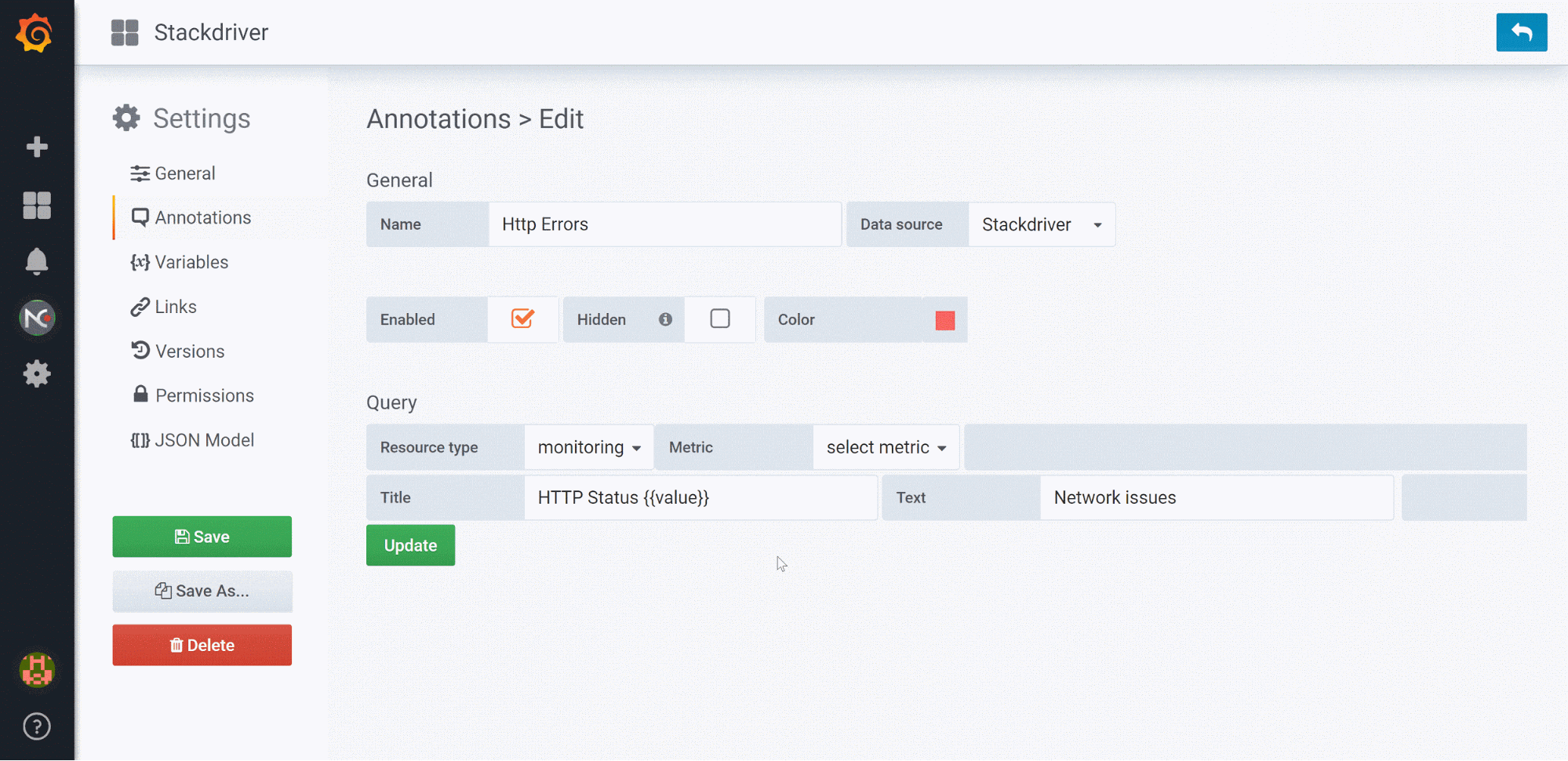
また、より強力な可視化オプションを Stackdriver ユーザーに提供するため、私たちは Grafana Labs ともパートナーシップを結びました。Grafana の時系列データ可視化ソリューションは市場で人気が高く、オブザーバビリティダッシュボードとモニタリング データ アナリティクス(潜在的な問題、根本原因、顕著な傾向について、その可視化、分析、特定を行う)のためのオープンフレームワークを基盤としています。このパートナーシップにより、Stackdriver Monitoring 用の可視化ツールとして Grafana を使用できるようになります。Stackdriver プラットフォームによって収集、ホスティングされているサービスのモニタリング データを可視化するための選択肢が広がるわけです。Grafana はこちらからダウンロードでき、そのユーザー インターフェースは次のとおりです。
今後に向けて
スピード、セキュリティ、安全性を確保するためには、このレベルの自動化がすべてのデベロッパーとオペレーターに対して与えられるべきです。私たちは、SRE / 運用チームによるアプリケーションの確実な運用をより効率化するエコシステムの拡張を計画しています。手間のかかる作業を自動化したいとお考えなら、今すぐ Stackdriver IRM のアルファ プログラムにサインアップしましょう。こちらでは Stackdriver について詳しく学ぶこともできます。今後の展開にご期待ください。- Post by Melody Meckfessel, VP of Engineering



