GCP による深層強化学習 : ハイパーパラメータ調整と Cloud ML Engineで OpenAI Gym ゲームを攻略
Google Cloud Japan Team
深層強化学習でのエージェントのトレーニングにはコンピューティング リソースと時間の両面で高いコストがかかります。通常は、アルゴリズムが数万もしくは数百万ステップのシミュレーション / トレーニングを経て初めて、累積報酬が上昇を開始します。たとえば、DeepMind の論文によると、エージェントが学習成果をはっきり示すまでにおおよそ 20 エポック(同論文によれば、1 エポック = 0.5 時間)を要しています。プロセス全体では 100 エポックかかり、しかもそれはわずか 1 回のトライアルでした。
また、ハイパーパラメータに敏感なことも強化学習の短所として知られています。これは、多くの異なるハイパーパラメータを評価する必要があるということを意味します。
この投稿記事では、こうした点への対応を目標としたうえで、Cloud Machine Learning(ML)Engine のハイパーパラメータ調整サービスを使って多くのジョブを並列にトレーニングする方法を説明します。このサービスには次の 2 つの大きなメリットがあります。
多くのモデルを並列にトレーニングすることができます。そのため、コンセプトを高速に反復でき、利用料金については各ジョブで使ったコンピューティング リソースの分だけに抑えられます。
単純なグリッド検索よりも一般に収束が速いマネージド ハイパーパラメータ調整サービスのメリットを享受できます。
これらの特長はあらゆる機械学習にとって有益ですが、計算が重く、異なるハイパーパラメータを評価するために多くのトライアルがしばしば必要とされる強化学習では特に大きな効果を発揮します。
本稿で使用するコードは GitHub リポジトリのこことここに置いてあります。このコードは強化学習を Google Cloud Platform(GCP)で使用する際の実例となっており、より洗練させればさらに良い結果を生み出せるはずです。
強化学習入門
強化学習は機械学習の形態の 1 つであり、エージェントが環境に対する行動を選択しながら、その一連の選択を通じて得られる目標(報酬)を最大化する方法を学習していくというものです。従来の教師あり学習のテクニックとは異なり、すべてのデータ ポイントにラベルが付けられているわけではなく、エージェントは「疎」な報酬にアクセスできるだけです。強化学習の歴史は 1950 年代までさかのぼることができ、そのアルゴリズムは数多く存在しますが、最近では簡単に実装できる 2 つの強力な深層強化学習アルゴリズム、DQN(Deep Q-Network)と DDPG(Deep Deterministic Policy Gradient)が注目を集めています。この節では、両アルゴリズムとその変種について簡単に紹介します。
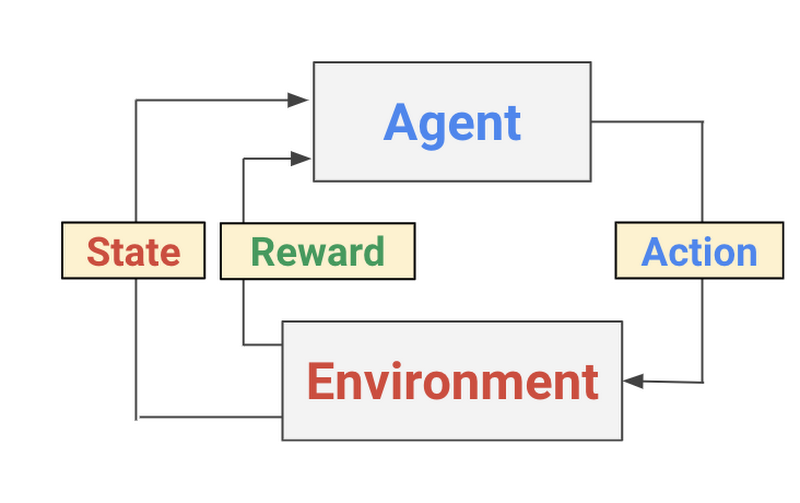
強化学習のプロセス概念図
DQN とは何か
DQN は、Google DeepMind のグループが 2015 年に Nature の論文で発表したアルゴリズムです。論文の著者らは、画像認識分野でのディープ ラーニングの成功に励まされ、ディープ ニューラル ネットワークを Q 学習に組み込み、観測空間が非常に高次元な Atari Game Engine Simulator でアルゴリズムをテストしました。ディープ ニューラル ネットワークは、特定の入力状態に基づいて、出力 Q 値、すなわちある行動を取ることがどの程度望ましいかを予測する関数近似器として機能します。つまり、DQN は価値ベースのアルゴリズムです。DQN はトレーニング アルゴリズムの中でベルマン方程式に従い Q 値を更新していきますが、動くターゲットに合わせる難しさを避けるために、ターゲットの値を予測する第 2 のディープ ニューラル ネットワークを使います。このネットワークの重みは指定されたインターバルでしか更新されず、それによって DQN のトレーニングを助けます。
強化学習は絶えず環境とやり取りすることによってデータを収集するので、データには時間相関があり、それがトレーニング中に DQN が収束するのを妨害します。そこで著者らは、この問題に対処するためにリプレイ バッファを導入しました。リプレイ バッファは以前に収集したデータを保持し、各トレーニングの反復中はこのリプレイ バッファからミニバッチをサンプリングします。
DeepMind グループが DQN の構築で使用したテクニックの詳細については、こちらの論文をご一読ください。
DDPG、TD3、C2A2
DDPG も DQN と同様に価値ベースの強化学習アルゴリズムです。具体的には、Actor(行動器)が環境の状態に基づいて行動を選択し、Critic(評価器)が与えられた状態(または状態と行動のペア)の価値を推計する Actor-Critic のアルゴリズムです。DQN と同じように、DDPG も Actor と Critic の両関数の近似器としてディープ ニューラル ネットワークを使用します。DDPG には、Critic が学習プロセスで過大評価をしがちだという大きな問題があります(これは、DQN を含む価値ベースの強化学習の大半に見られる問題です)。この問題に対処するため、TD3(Twin Delayed Deep Deterministic policy gradient)は 2 つの Critic を持ち、(状態, 行動)のペアに対する両者の評価のうち小さいものを推計値として返すことを提案しています(下記コードの 6-11 行)。TD3 はこれ以外にも、推計誤差の拡大を抑えるためにターゲット ネットワークの更新を遅らせることや、値評価で狭いピークへの過剰適合を防ぐためにターゲット ポリシーを平滑化する正則化も提案しています。TD3 の詳細についてはこちらの論文をご覧ください。
TD3 は優れた機能を発揮し、実装も簡単ですが、エージェントが推計値を低いと思ったときに取れる行動にも選択肢があったほうがよい(そして面白い)でしょう。そこで私たちは、TD3 に Actor をもう 1 つ追加した C2A2 というアルゴリズムを作りました(名前の由来は言うまでもないはずです)。C2A2 は値評価では TD3 と同じですが、追加された Actor が行動の選択肢を提供し、エージェントは推計値が大きい Actor を選択します。下記コードの 18-27 行はこのロジックに相当し、Cloud ML Engineで実行する新しいアルゴリズムを作るうえでプラットフォームに合わせたコード変更は不要だということを示しています。
OpenAI Gym 環境での深層強化学習
OpenAI Gym は、強化学習アルゴリズムの試験や評価に使用できる人気の高いプラットフォームです。OpenAI Gym を使えば、エージェントがやり取りする環境を初期化できます。エージェントがすでにトレーニング済みの場合、エージェントは環境の観測結果を入力として行動を選択します。
Cloud ML Engine で強化学習を実行するためのステップ
Google Cloud でハイパーパラメータ調整のジョブを実行するのは簡単です。必要なステップは次の 5 つです。- 通常の方法でモデルを構築します。
- コマンドライン引数としてハイパーパラメータを指定します。これにより、モデルのロジックからハイパーパラメータが切り離されます。
- Python パッケージを作成します(つまり、__init__.py と setup.py を追加します)。
hyperparameter.yamlファイルを記述します。- コマンドラインで
gcloud ml engine submitと入力し、最初のトレーニング ジョブを送信します。
実際の作業では大半の時間がステップ 1 に費やされ、他の部分は定型のコードで事足ります。私たちの構成では、OpenAI の
gym ライブラリと互換性のあるシンプルな方策勾配エージェントと DQN エージェントを実装し、さらに continuous control problems のために TD3 を実装しました。実装はこことここからチェックアウトできます。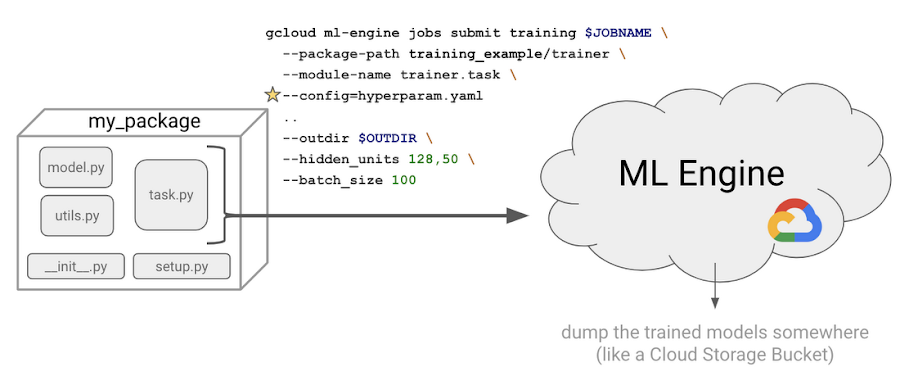
ハイパーパラメータ調整 : コードの準備
強化学習エージェントを作り、解決したいタスクを定義したら、コマンドライン引数にハイパーパラメータを指定する必要があります。これは、すべてのハイパーパラメータを互いに切り離し、個々のハイパーパラメータの効果をそれぞれ評価するうえで、きわめて重要です。たとえば argparse ライブラリを使用すると、ハイパーパラメータをコマンドライン引数として指定できます。Keras では、最適化したい指標を Model オブジェクトの metrics 引数に指定できます。
カスタム指標を追加したい場合もあるでしょう。私たちは次のようにして reward という名前のカスタム指標を追加しました。
TensorFlow を使用している場合は、TensorBoard と同様に指標のログを取得する必要があります。
reward パラメータを YAML ファイルで最適化するよう Cloud ML Engine に指示します。次に、2 番目の重要な追加として、個々のトライアルごとに一意な出力ディレクトリを用意します。トライアルが互いに上書きし合うようなことは避けなければなりません。これは、コマンドラインで --job-dir フラグを使用すれば自動的に実現できますが、TF_CONFIG 環境変数からトライアル番号を手作業で取得することも可能です。
さらに、コードを Python パッケージの形式にまとめる必要もあります。詳細はこちらにありますが、基本的には空の __init__.py と setup.py をフォルダ構造に追加するということです。私たちの最新コードのファイル構成は以下のとおりです。
ハイパーパラメータ調整 : ジョブの送信
モデルを作成したら、調整したいハイパーパラメータ、個々のハイパーパラメータの範囲、最適化したい指標(ここでは reward)を指定するハイパーパラメータ yaml ファイルを定義します。ここでは、どれだけの計算能力を使いたいかを示すスケール階層も指定できます。私たちの場合は 1 つのジョブで 1 つの GPU を使いますが、たとえば複数の GPU を使うようなカスタム セットアップの場合はカスタム スケール階層を指定できます。機械学習に Cloud ML Engine を使うことのメリットは、インフラのことを気にせずにモデル開発とデプロイに専念できることです。
注意すべきポイントは、ベイズ最適化を使うハイパーパラメータ調整サービスは前のステップから学習する逐次アルゴリズムだということです。したがって、
maxTrialsと maxParallelTrials を指定しなければなりません。maxParallelTrials が maxTrials と等しいという極端なケースでは、プロセスは 1 つのモデルのトレーニングに要する時間と同じくらいの短時間で終わります(この場合、algorithm パラメータにはベイズ最適化ではなく、グリッド検索を行う GRID_SEARCH を指定できます)。逆に、 maxParallelTrials が小さければトレーニングに要する時間は長くなりますが、ベイズ最適化プロセスはエポックが増え、それによってモデルを少しずつ良くすることができるので、一般に性能の高いモデルが得られます。以下に例を示しましょう。以上で、Cloud ML Engine にハイパーパラメータ ジョブを送信する準備が整いました。
--config フラグを使ってハイパーパラメータの YAML ファイルを指定している点に注意してください。基本的にこのプロセスは、異なるハイパーパラメータを使用して、さまざまなトレーニング ジョブを実行します。ジョブ ステータスは次の方法で表示できます。
モデルの出来は?
GCP 上で強化学習を実行するための参照例として、私たちは以下の 3 つを作成しました。- TensorFlow と OpenAI Gym を使用して CartPole(倒立振子)を解く、非常にシンプルな方策勾配の実装
- tf.keras を使用して Breakout Gym 環境を解く、より高度な DQN 実装
- BipedalWalker 環境で TensorFlow を使用する TD3
これら 3 つの実装すべてについて、得られた結果(ハイパーパラメータの調整結果を含む)とともに、CartPole、Breakout、BipedalWalker を解いているエージェントのビジュアルをお見せしましょう。すべてのジョブを Cloud Storage 上のモデル ディレクトリに書き込んだので、TensorBoard を使ってトライアル結果を可視化することができます。
複数のトライアルの評価曲線を解釈するのは少し難しいかもしれません。そこで私たちは、最終的な目標値だけを見るようにしています。最終結果は Cloud Console の ML Engine > Jobs から確認できます。

CartPole をプレイする方策勾配の実装では、最良のパラメータ(勾配ステップは 30 に制限。十分に反復すれば、最適とは言えないハイパーパラメータの場合でも、CartPole は最終状態の報酬 200 にたどり着きます)は次のとおりです。
これに対し、見劣りのするハイパーパラメータを使用すると、環境が最終状態に達することはなく、報酬はわずか 32 にとどまりました。
私たちはもっと複雑な Gym 環境を解くための DQN 実装も作成し、そのコードを Breakout で実行しました。ここでは、比較的良好なハイパーパラメータを使用した結果を 2 つ紹介します。トレーニング時間を延長し、大きなハイパーパラメータ スペースを検索すれば、性能は間違いなく向上します。
BipedalWalker の結果
わずか 100 エピソードのトレーニングでは、エージェントはほとんど立つことができませんでした。1000 エピソードのトレーニング後は、エージェントはコースを渡り切ることができました(非効率的な形ですが)。
2000 エピソードのトレーニング後は、エージェントの足取りがすばやくなりました。
まとめ
強化学習は現在、急速なイノベーションの時代を迎えています。Cloud ML Engine も、強化学習による問題解決の実践者や研究者にとって価値の高いツールとなっています。特に、Cloud ML Engine のハイパーパラメータ調整サービスは、異なるタイプのハイパーパラメータの組み合わせを評価することを可能にします。また、単純なグリッド検索と比べて最適化プロセスを高速化できるベイズ最適化を使ったマネージド ハイパーパラメータ調整サービスのメリットも享受できます。ハイパーパラメータ調整の詳細については、こちらのドキュメント ページをご覧ください。参考資料
- By Praneet Dutta, Cloud ML Engineer and Chris Rawles, ML Solutions Engineer and Yujin Tang, ML Strategic Cloud Engineer



