Google Cloud Platform Japan Blog
最新情報や使い方、チュートリアル、国内外の事例やイベントについてお伝えします。
リアルタイムに近いログのストリーミングと分析を Google Cloud Platform と Logentries で実現
2015年6月30日火曜日
* この投稿は、米国時間 6 月 22 日、 Google Cloud Platform の PM、Deepak Tiwari と Logentries の共同設立者かつチーフ サイエンティストである Trevor Parsons によって
投稿
されたものの抄訳です。
Google では、Google Cloud Platform のユーザーにとって DevOps をいかに簡単にできるかを常に考えています。
Google App Engine
、
Google Compute Engine
、あるいは他のサービスでも、システムやアプリケーションが生成するログにアクセスしたいことでしょう。
Google Cloud Platform では
Google Cloud Logging
でログ情報を集中化し、ログデータの表示、検索、分析が可能です。Cloud Logging では、
Google Cloud Storage
にログをアーカイブしたり、ログを
Google BigQuery
に送ったりする機能が含まれています。加えて Cloud Logging では、
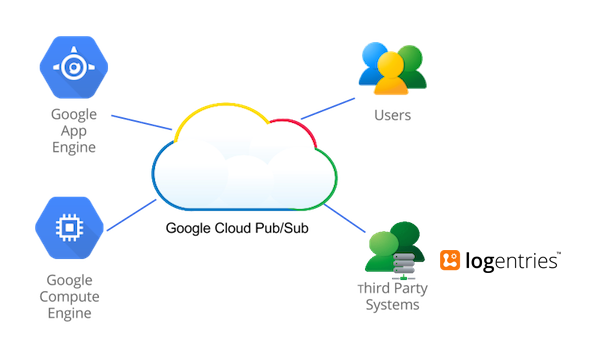
リアルタイムに近いストリーミングを行える Google Cloud Pub/Sub API
経由でサードパーティーのログ管理ツールなどにログを転送し、さらに高度でカスタマイズされたログ分析を行うこともできます。
そしてこのたび、サードパーティーのログ分析サービスである Logentries を Google Cloud Platform で使えるようになりました。これにより、Google Cloud Platform のユーザーは、ログ管理や異常検出を含む高度な分析を手軽に構成することができます。 Google App Engine で Logentries が利用できるようになったので、Cloud Dataflow サービスなどとも併せてスタートがさらに容易になりました
Google Cloud Pub/Sub API の概要
Cloud Pub/Sub は、毎秒 100 万以上のメッセージを処理する場合であっても数ミリ秒以内に配信する速度で、アプリケーション間でデータをルーティングする役割を担う強力なメッセージング サービスです。リアルタイムに近い多対多、非同期のメッセージング サービスであって、送信側と受信側とを切り離すことによってシンプルで高信頼の柔軟なアプリケーションを作成するのに役立ちます。別個に作成されたアプリケーション間においてセキュアな高可用性通信が可能になります。
そのため Cloud Pub/Sub はログを転送するための理想的なサービスであり、ログイベントの送信やログイベントが発生した際の受信ができます。
リアルタイムに近いログ分析サービスである
Logentries
は、Google Cloud Pub/Sub と統合してほぼリアルタイムに近いログのストリーミング転送を行うサードパーティー製の最初のサービスであり、アラートを設定したり、異常検出や高度な分析を実行したりすることができます。
Google Cloud Logging で Logentries を設定する方法
Google Cloud Platform のログを Logentries にストリーミングするには次のように設定します。
Cloud Pub/Sub API を有効にする
プロジェクトに Logentries サービスのアカウントを追加する
Cloud Pub/Sub へのエクスポートを設定する
Logentries でログを追加する
ステップバイステップの
手順
もご参考ください。
リアルタイムに近いログ分析
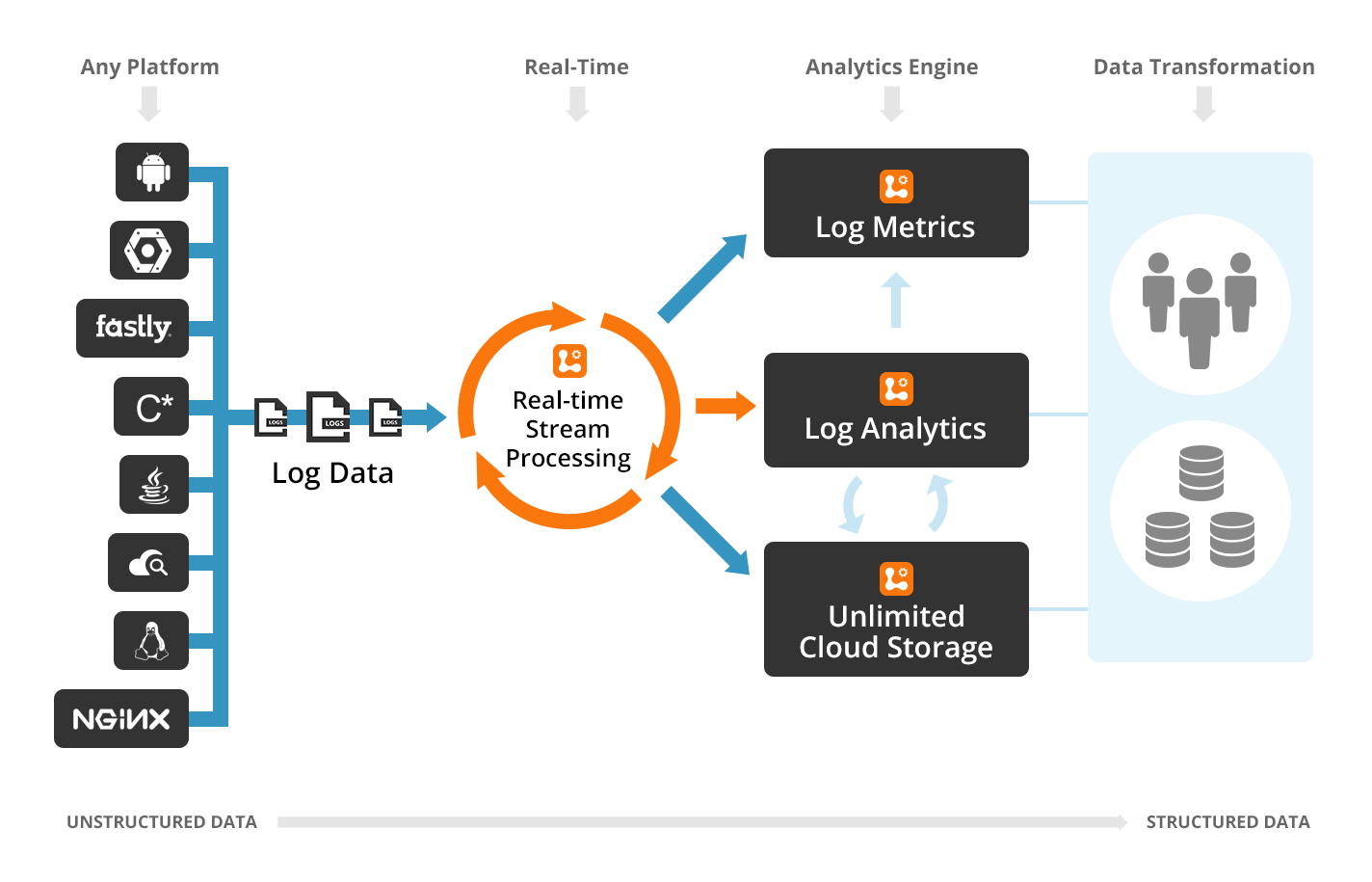
Logentries は独自の前処理エンジンを使用し、Google のログに対して高度な分析をリアルタイムに近いスピードで実行します。データを事前に分析するので、重要なシステムやユーザーのアクティビティを識別するための複雑な検索クエリをログに対して実行する必要が少なくなります。
Google Cloud Platform と Logentries により、ログデータ全体の長期的な動向を把握するのみならず、問題点を迅速に特定することができます。Google Cloud Platform のユーザーに役立つ Logentries の機能の一部を以下に紹介します。
イベントのタグ付けによるライブ追跡: Logentries の前処理エンジンは自動的に例外、警告、エラーなどの重要なイベントにタグを付けるため、ログデータのライブビューで容易に問題を発見することができます。
リアルタイムに近い通知および動作停止アラート:重要なイベントが発生すると数秒以内に通知します。通知は、電子メールで送信するように設定したり、または他のサードパーティーの API やツール(例えば、Slack、HipChat、PagerDuty など)と組み合わせることができます。
ログをデータとして使用:ログにはスタック トレースやエラーコードのほかにも非常に有用な情報が多数含まれています。
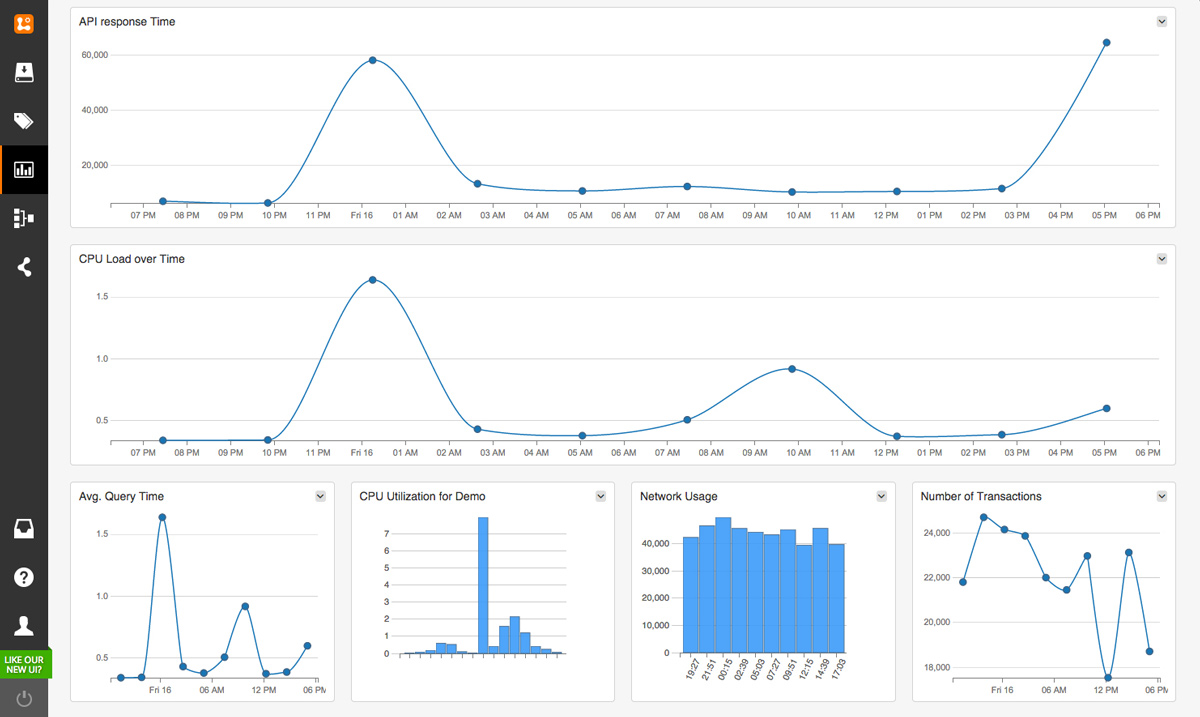
フィールド レベルのログ分析
により、ログから主要な指標(例えば、サーバー リソースの使用状況や API の応答時間)を抽出したり、そうした指標をチャートやグラフに要約したりすることができます。
Google Cloud Logging は google-fluentd コレクタ経由で
既知のログ形式
を多数サポートしています。例えば、Apache、Chef、MongoDB、NginX などがそうです。Logentriesはまた、
コミュニティ パック
を通じて、これらのログ形式に対応したすぐに使える機能(タグ、アラート、ダッシュボード)を提供しているため、ルールやクエリの設定に時間を費やす必要がありません。
Google Cloud Logging と Logentries の開始方法はこちらからどうぞ
。また、
Logentries フォーラム
もご参照ください。
- Posted by Deepak Tiwari (Product Manager, Google Cloud Platform) and Trevor Parsons (Co-founder and Chief Scientist, Logentries)
App Engine for PHP が正式リリース - 高速かつスケーラブルな環境をすべてのユーザーに
2015年6月26日金曜日
* この投稿は、米国時間 6 月 16 日、ソフトウェア エンジニアの
Stuart Langley によって投稿
されたものの抄訳です。
App Engine for PHP とは、PHP ベースのウェブ アプリケーションをクラウドで実行するために
Google Cloud Platform
に用意されているスケーラブルな環境です。
このたび、App Engine for PHP から「ベータ」のラベルを剥がして、すべてのお客様に向けて正式にリリースしました。
App Engine の SLA
と非推奨ポリシーは App Engine for PHP にも適用されます。
App Engine 上で PHP アプリケーションを実行すると、次のようなメリットが得られます。
App Engine のデフォルト セキュリティ ポリシーとインフラの自動パッチ機能(本番稼働しているアプリケーションにも働きます)によって、シェル注入攻撃、ファイル インクルード攻撃、
ハートブリード
のようなセキュリティ バグによるアプリケーションの脆弱性を軽減します。
App Engine は組み込みで自動スケーリング機能を提供するため、秒あたりのクエリ 0 から数千までアプリケーションを自動的にスケーリングできます。トラフィックが落ち込むようなことがあれば、App Engine が自動的にスケールダウンし、使った分だけの料金しか発生しません。
App Engine は、NoSQL データストア、memcached、ユーザー認証 API など、さまざまな管理付きサービスを提供します。これにより、可用性の高いアプリケーションをスピーディに構築できます。
すでに数万のデベロッパーが App Engine 上で PHP アプリケーションを構築、デプロイし、毎週 8 億以上の PHP クエリを処理しています。App Engine 上で毎日見られている、PHP で生成されたウェブページを 1 枚の紙に印刷して積み上げていったとすると、7 マイル以上の高さになる計算です(これはボーイング 747 ジャンボジェットが安定飛行する高度とほぼ同じです)。
App Engine for PHP には
一定の無料枠
が設けられています。お気に入りのフレームワークを選び、今すぐ
SDK をダウンロード
して動かしてみてください。Google は皆さんのすばらしいアプリケーションを心待ちにしています。行き詰まったときには
Stack Overflow タグ
を利用することも、あるいは
Google から直接サポート
を受けることもできます。
- Posted by Stuart Langley, Software Engineer
Google Container Engine のベータリリースと Container Registry の新機能 – アプリのデプロイと管理が容易に
2015年6月25日木曜日
* この投稿は、米国時間 6 月 22 日、Google Cloud Platform プロダクトマネージャーの
Eric Han と Kit Merker によって投稿
されたものの抄訳です。
アプリケーションのデプロイと管理の方法が、Google のコンテナによって変わろうとしています。このたび
Google Container Engine
をベータ リリースとし、価格情報に加えてコンテナ クラスタの管理強化に役立つ新機能をアップデートしました。同時に
Google Container Registry
も GA (正式リリース) となります。これにより、プライベート リポジトリへのコンテナ イメージの保存や、保存したイメージへのアクセスが容易になります。
Google Container Engine ベータ :新機能と価格
コンテナによってアプリケーションのパッケージングは容易になりますが、DevOps や IT 管理者が必要としているのは、コンテナ化が約束するメリットをもっと確実に享受するためのツールです。Container Engine は、コンテナ クラスタのセットアップとアプリケーションの管理を容易にします。CPU やメモリの要件といったコンテナのニーズを定義するだけで、Container Engine はクラスタにコンテナをスケジューリングし、自動的に管理します。また、Container Engine はオープンソースのコンテナ管理
Kubernetes
の上に構築されているので、ワークロードを移動したり、複数のクラウド プロバイダを利用したりすることができます。
「 Container Engine は、私たちを縛り付けることなく Google のインフラパワーを私たちに与えてくれる。おかげで、インフラについて何ら心配することなく、ソフトウェアを書くことに専念できる」 - Brian Fitzpatrick, 創設者兼CTO,
Tock
「 Container Engine と Kubernetes のおかげで、週に 1 時間のダウンタイムを設けて 1 つのデプロイだったものが、ダウンタイムなしで 1 日に 8 つのデプロイをこなせるようになった」 - Frits Vlaanderen, システムエンジニア,
Travix
Container Engine の新機能はコンテナ クラスタの管理強化に役立ちます。
Kubernetes の ver.1 リリース候補
をサポートするコンテナ クラスタを数分で作れます。
Container Engine が Kubernetes のアップタイムを管理するので、いつでもコンテナのスケジューリングが行えます。
Google が Kubernetes システムに対するアップデートを管理しており、いつアップデートを受け入れるかはユーザー側で選べます。コマンドを 1 つ実行するだけで、コンテナ クラスタを最新バージョンにアップグレードできます。
Google Cloud VPN
を使ってデータセンターを Google に接続している場合、コンテナ クラスタのために IP アドレスの範囲を予約できます。そのため、クラスタ IP とプライベート ネットワーク IP の共存が可能です。
1 つのチェックボックスで
Google Cloud Logging
を有効にできます。そのため、アプリケーションがどのように動作しているかを容易に把握できます。
従来と同様に、ベータテスト中は使用している Google Cloud Platform リソースの料金以外に Container Engine のための追加料金は発生しません。正式リリース後は、Container Engine のために 2 段階の価格が設定される予定です。
スタンダード クラスタは 1 時間あたり 0.15 ドルになる予定です。スタンダード クラスタは 100 個までの仮想マシンノードを含むことができ、Google がクラスタの可用性を管理します。
ベーシック クラスタは 5 個以下の仮想マシンノードで Container Engine を試せるものです。可用性の管理が必要なときは、容易にスタンダード クラスタにアップグレードできます。現在のプロモーションのもとでは、ベーシック クラスタを使っても追加料金は発生しませんが、将来は課金される可能性があります。
価格の詳細は
Container Engine pricing details
を参照してください。
Google Container Registry の正式リリース
Google Container Registry は、Cloud Platform 上に構築された非公開暗号化レジストリにコンテナ イメージを容易に格納できるようにするものです。Container Registry へのイメージ格納に関する価格体系は単純で、Google Cloud Storage 以外の料金は発生しません。イメージのプッシュも無料で、Google Cloud Platform リージョンへの Docker イメージのプルも無料です(リージョンの外へのプルには域外料金がかかります)。
Container Registry は本番環境での使用に十分に応えます。
暗号化と認証 - コンテナ イメージは安定した状態のもとで暗号化され、アクセスは Cloud Platform OAuth で認証されます。そして SSL 経由で転送されます。
高速 -
Cloud Storage
と
Cloud Networking
の上に作られているため、アプリケーションの需要を迅速に処理できます。
単純 – Docker を使用している場合は、イメージに
gcr.io
タグを付けてレジストリにプッシュすればすぐに
始められます
。Google Developer Console でイメージを管理できます。
ローカル - クラスタがアジアやヨーロッパで実行されている場合、
asia.gcr.io
、
eu.gcr.io
タグを使って、アジアやヨーロッパ専用リポジトリにイメージを
格納
できます。
Container Registry を本番システムで使用中のユーザーを紹介しましょう。
「昨秋からコンテナと Kubernetes を使い始めたが、Container Registry は気に入っている。当たり前に動いているので、これがいかに役に立っているかをつい忘れてしまいそうだ」 - Steve Reed, プリンシパルソフトウェアエンジニア,
zulily
「 Container Registry は、コンテナ環境に移行するにあたって必要不可欠なコンポーネントだ。Docker コンテナを動かすための単純な環境を提供してくれるので、コンテナがセキュアで改ざんされないという安心感が得られる」 - Dave Tucker, エンジニアリング担当VP,
Workiva
「 Container Registry のおかげで、デベロッパーたちはプロジェクトの既存のセキュリティ設定のもとでプライベート リポジトリを作り、プライベートな構築済みコンテナに効率よくコードをデプロイできる。 これだけの規模になると、デプロイにかかる時間が短縮されればコスト削減効果も大きい。数千のインスタンスで、分単位ではなく秒単位でデータを処理するためには、コンテナ レジストリと計算インスタンスの間に超高速ネットワークがあることが極めて重要なのだ」 - Tim Kelton, 共同創設者,
Descartes Labs
「 Google Container Registry の最大の特徴はパフォーマンスだ。イメージのプッシュ、プルでは明らかに最速である」 - Avi Cavale, CEO&共同創設者,
Shippable
さあ、始めましょう
Container Engine を試すには、最初に
専用サイト
と
ドキュメント
をご覧ください。Container Registry の詳細を知りたいなら、
ドキュメン
トをご覧になるか
メール
で要望を送ってください。Container Engine と Container Registry は、コンテナ化が約束するメリットをフルに享受できるようにしてくれるでしょう。
- Posted by Eric Han & Kit Merker, Product Managers on Google Cloud Platform
データセンター ネットワークに対する Google の取り組み - 最新世代の Jupiter を紹介
2015年6月23日火曜日
* この投稿は、米国時間 6 月 17 日、Googleフェロー兼ネットワークテクニカルリードの
Amin Vahdat によって投稿
されたものの抄訳です。
Google File System
に始まり、
MapReduce
、
Bigtable
を経て
Borg
に至るまで、Google は長らく分散コンピューティングとデータ処理の開拓者として時代の先頭を走ってきました。当初から Google は、このような偉大なコンピューティング インフラストラクチャが偉大なデータセンター ネットワーキング テクノロジーを必要とすることを認識していました。しかし当時は、Google が求める分散コンピューティングの要件を満たしたデータセンター ネットワークを作っている会社は、どこにも見当たりませんでした。
そこで、Google はこの 10 年間、社内データセンターのすべてのサーバーを相互接続して分散コンピューティング、ストレージ システムを支えるため、自らネットワーク ハードウェアとソフトウェアを構築してきました。Google は現在、Google Cloud Platform を通じて、この強力で柔軟に変形できるインフラストラクチャを外部デベロッパーのために開放しています。
そして Google は、先日開催された
2015 Open Network Summit
で、5 世代の社内ネットワーク テクノロジーの詳細を初めて公開しました。初の社内データセンター ネットワークである 10 年前の Firehose から最新世代の Jupiter ネットワークに至るまで、Google は 1 つのデータセンター ネットワークの能力を 100 倍以上に増強してきました。実際、現在の Jupiter ファブリックは二分割帯域幅で 1 ペタビット/秒を超えています。これだけの能力があれば、10 万台のサーバーがそれぞれ 10Gb /秒で情報を交換でき、アメリカ国会図書館所蔵図書のスキャンしたコンテンツ全体を 1/10 秒未満の時間で読み込むことができるでしょう。
Google は次の 3 原則に基づいてデータセンター ネットワークを設計しました。
CLOS トポロジー
、すなわち比較的小さい(安価な)スイッチを大量に使って、はるかに大規模な論理スイッチの機能を提供できるようにアレンジしています。
一元的なソフトウェア コントロール スタックを使って、データセンター内の数千のスイッチを管理し、それらが 1 つの巨大なファブリックとして機能するようにしています。
ベンダー各社の原材料を使い、標準インターネット プロトコルに大きく依存せず、データセンター向けに最適化されたカスタム プロトコルを多用して、独自のソフトウェアとハードウェアを構築しています。
これら 3 つをまとめると、Google のネットワーク コントロール スタックは、伝統的なルーター指向のインターネット プロトコルよりも、Google の分散コンピューティング アーキテクチャに似ています。Google では 10 年前から
SDN(Software Defined Networking)
ネットワークの利点を取り入れ、活用してきたと言う人さえいます。数年前、Google は世界最大の WAN の 1 つである Google のデータセンター WAN、
B4
が SDN によって作られていることを明らかにしました。Google Cloud Platform の SDN 仮想化スタック、
Andromeda
の詳細も昨年公開しています。実際、これら 2 つのシステムのアーキテクチャ面でのアイデアは、Google 初期のデータセンター ネットワーキングに由来するものなのです。
傑出したデータセンター ネットワークは、優れたハードウェアとソフトウェアだけで実現できるものではありません。当初から世界最高のネットワーク構築、運用チームとの連携が不可欠です。Google のネットワークに対するアプローチは、ネットワークのデータ、制御、管理の水準を根本から変えていくものです。そのような徹底的なシフトは、ある程度の波乱を引き起こさずには実現できませんが、Google の運用チームは難題に応える以上の働きをしています。Google は、社内の分散システム群が必要とする帯域幅を確保するため、全地球規模のインフラストラクチャ全体で数世代のネットワークをデプロイ、再デプロイしてきました。
結論としては、Google のデータセンター ネットワークは全体として、いまだかつてないスピードを実現しています。データセンター ネットワークはモジュール性を重視して作られ、最新世代のサーバー群の帯域幅に対する止めどない需要に合わせて絶えずアップグレードされています。管理では可用性を重視し、最も多くのリソースを必要とする一部のサービス、顧客のアップタイム要件を満足させています。何より大切なのは、Google のデータセンター ネットワークが共有インフラストラクチャだということです。これは、Google の社内インフラストラクチャ、サービスを動かしているのと同じネットワークが Google Cloud Platform を動かしているということです。Google は、世界中のデベロッパーにこの能力を開放し、次代の偉大なインターネット サービス、プラットフォームが、ワールドクラスのネットワーク インターフェースを新たに作らなくてもすぐに活用できることに最も誇りを感じています。
- Posted by Amin Vahdat, Google Fellow and Technical Lead for Networking, Google
HTC、より速くより信頼性の高いモバイルアプリ エクスペリエンス を Google Cloud Platform で実現
2015年6月19日金曜日
* この投稿は、米国時間 6 月 16 日
ポストの Google Cloud Platform ブログ
の抄訳です。
本日のゲストは、スマートフォンやタブレット製品をリードする HTC のクラウドコンピューティングシニアディレクター、ジョン ソン氏です。
トンネルや地下鉄に入る時、モバイルアプリがフリーズしてしまった経験は誰にでもあることでしょう。上司への企画書作成中、または Candy Crush で最終レベルまで上り詰めている最中に、アプリへアクセス不能になると、アプリに対しても怒りや苛立ちを感じてしまいます。急速に成長するモバイルの世界で、人々はデータやアプリが即座に使用でき、切断されないことを期待します。しかし、モバイル デバイスでアプリを使う時、頻繁に起こる 2 つの問題があります。信頼性と帯域幅です。それに通信料金が高い国々では、データ使用量を減らすことが重要です。
HTCでは、
HTC Gallery
や Zoe
、
One M9 Photo Editor
など私たちが構築しているモバイルアプリでユーザーエクスペリエンスをより良くする取り組みを行っています。信頼性を高め、帯域幅の使用量を減らすために、オール イン ワンソリューションとして
Google Cloud Platform
の導入を開始しました。事実、Google Cloud Platform で新しいモバイルアプリのフレームワークを構築したことで、今後はさらに多くのアプリ構築をより速く進めることができるでしょう。
Google Compute Engine
や
Google Cloud Storage
から
Google Cloud Datastore
に至るまで、ツールのコンビネーションが、ユーザーエクスペリエンスを向上させ、デベロッパーにより良い機能を構築するための自由な時間を与えてくれます。
切断や帯域幅使用といった問題に対処するため、弊社では Cloud データストアのデータ同期特性を利用しました。
One Gallery アプリ
は、データ更新時にデータパケット全体ではなく変更箇所のみの送信を行います。つまりユーザーは、接続中断前にロードされたデータにアクセスし続けることが可能です。例えば One M9 Photo Editor ユーザーが写真に二重露光その他の視覚効果を加えている場合、ネットワーク切断時も写真編集を続行することが出来ます。接続がいったん回復すると、アプリが最新の変更箇所のみを取り込みます。
安定したネットワーク接続は、より良いエンドユーザー エクスペリエンスの鍵となるだけでなく、ソフトウェア開発やデバッグコードにも不可欠です。Google Cloud Platform の安定したネットワークにより、弊社デベロッパーはレイテンシに対処する必要がなく、高品質なユーザーエクスペリエンスを提供する製品を構築することが出来ます。例えば、HTC Gallery アプリを用いて 1 万枚の写真をアップロードすれば、アプリがスリープ状態になったり、速度が極端に遅くなることがありません。また、安定したネットワークにより、デベロッパーは写真を別々のページに載せるのではなく、イメージ ページをスクロールする設計にすることが出来ます。
Google のバックエンドは安定しているため、弊社デベロッパーは低レイテンシを原因とするバグ修正ではなく、より良い機能の構築に自分たちのエネルギーを費やすことが出来ます。Google Cloud Platform を採用しているため、バックエンドのダウンタイムは一切ありません。より多くのアプリを構築し、カスタマー ベースを増やす際も、データ分割や更なるデータベータ追加に煩わされることはありません。なぜなら Compute Engine のオートスケール機能があるからです。
弊社では IT コストを 40 パーセント削減しました。また、
アンドロイド向けの Google Cloud Messaging
や
Google BigQuery
を使用することにより経費削減を行っています。以前は内部でツール構築を考えていましたが、今では Google Cloud Platform 製品を使用することにより時間や経費、そしてリソースを削減しています。
Google Cloud Platform を使えば、新しいモバイルアプリの構築にフォーカスでき、豊富でシームレスなユーザーエクスペリエンスを提供し、信頼性の高いネットワークで全て構築が可能になります。
- Posted by John Song, Senior Director of Cloud Computing, HTC
Google Compute Engine における信頼性の高いタスク スケジューリング
2015年6月15日月曜日
* この投稿は、米国時間 6 月 11 日、Solutions Architect の
Preston Holmes によって投稿
されたものの抄訳です。
スケジューリングしたタスクを定期的に実行しなければならないシステムはたくさんありますが、 分散環境でそのようなタスクを確実に実行することは驚くほど難しい場合があります。
多数の仮想マシンで UNIX の cron サービスを実行しようとするとどうなるか、想像してみましょう。オートスケールとネットワークのパーティショニングのために、個別の仮想マシンは出入りが激しくなります。すると、タスクをスケジューリングしたマシンが使えなくなり、重要なタスクが実行されないケースが出てきます。あるいは、オートスケーラーが新しいサーバーをオンラインにすると、1 度だけ実行するつもりだったタスクが、それら多数のサーバーで重複して実行されることもあります。
このような場合には、Google
App Engine の Cron サービス
でスケジューリングし、
Google Cloud Pub/Sub
でメッセージングをすれば、仮想マシンでフォールト トレラントな分散スケジューラを作ることができます。その方法は、
Google Compute Engine のための信頼性の高いタスク スケジューリング
を参照してください。ここからは、GitHub 上の
サンプル実装のコード
にもアクセスできます。
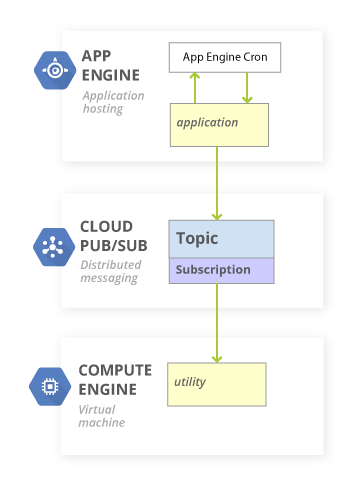
このデザイン パターンでは、軽い App Engine アプリケーションを使って Cron サービスのイベントをスケジューリングします。Cron サービスがこの App Engine アプリケーションのイベント ハンドラを呼び出すと、App Engine アプリケーションは Cloud Pub/Sub を使って、個々の Compute Engine インスタンスで実行されているユーティリティにイベントを伝えます。
サブスクライブしているユーティリティは、メッセージを受信すると、Cloud Pub/Sub トピックに対応するスクリプトを実行します。スクリプトは、Cron によって実行されたかのようにインスタンス上でローカルに実行されます。実際、このデザイン パターンでは既存の Cron スクリプトを再利用できます。
分散メッセージングのために Cloud Pub/Sub を使っているので、多数のサーバーの中の 1 台だけでタスクを実行するとか、複数のサーバーでタスクを並行実行するといった形でイベントをスケジューリングすることができます。トピックとサブスクライバ モデル (下図参照)によって、特定のタスクをどのインスタンスに渡すかを細かく制御できるのです。
図 1 - Compute Engine から App Engine Cron を利用する
このデザイン パターンの詳しい説明については、
Google Compute Engine のための信頼性の高いタスク スケジューリング
を参照してください。この記事には、GitHub 上の
サンプル実装
へのリンクが含まれています。このサンプルはオープンソースなので、自由にプル リクエストできますし、直接イシューを開くことができます。使って便利だと思われたときには、Twitter のアカウント、
@ptone
にぜひお知らせください。
- Posted by Preston Holmes, Solutions Architect
JDA,Google Cloud Platform で新たな考え方を。
2015年6月11日木曜日
* この投稿は、米国時間
6 月 10 日ポストの Google Cloud Platform ブログ
の抄訳です。
今日のゲストはサプライチェーンや小売向けソリューションの主要プロバイダとして業界をリードする JDA Software Group 技術担当グループ副社長ジョン サルヴァリ氏です。
JDA では何千ものビジネスに対してサプライチェーン管理の技術やコンサルティング サービスを提供し、収益を上げながらコストを下げています。我々のソリューションやサービスの根底にあるのは豊富な情報量で、我々は実績あるテクノロジーを駆使し、データから実現可能な洞察を得てクライアントの事業展開の向上をお手伝いします。入手可能なデータの量や種類が急増し、より鋭い消費者ニーズへの洞察を提供できるチャンスです。
Google Cloud Platform
はクライアントのニーズに応えるために必要なスケールを抜群の規模で展開することを可能にするのです。
我々は常に、クライアントのニーズに応える新たな方法を模索しており、より良いサービスを提供できるようにしてきました。Google Cloud Platform は、JDA がサポートしているビジネス プロセスを完全に見直せる特長を備えていました。実際、我々は去年、データサイエンスに関するイノベーションやユーザー体験、製品イノベーションに特化した 50 人体制のチームである JDA Labs を導入しました。このチームは先進的なアイデアを生み出し、過去
9 ヶ月
で特許申請したアプリケーションの数を
2倍
にするというインパクトをもたらしました。
Google Cloud Platform を利用したことで、強力かつ信頼性の高いバックエンド システムの恩恵を受け、その結果、市場にイノベーションをもたらすことに集中し、4 千社以上ものクライアントがデータに基づいた判断を下すお手伝いをしています。我々は数多くの Google Cloud Platform 製品を活用していますが、弊社の成功にとって特に重要なのは
Google App Engine
と
Google Cloud Dataflow
です。Google App Engine のような PaaS (Platform as a Service) はオンプレミス テクノロジーの制約を取り除きます。例えば、より効率的に、より多くの製品を買って生産し、売るための営業予測ソリューションを製造業者や小売業者のいずれに対しても提供しています。予測をするためには何億ものデータ処理が必要となります。Google Cloud Platform にはソーシャルメディアや天気、また IoT 情報(例えば農作業情報について報告するセンサーなど)のような追加データの統合を可能にするテクノロジーがあって、予測の正確性を向上させ、クライアントのニーズに応えるために適正な商品が最適なタイミングで提供されることを保証します。
Google Cloud Platform がクライアントのニーズに対応する速さには圧巻です。小さな Google Cloud Dataflow 構成のおかげで、リアルタイムに毎分 5 万件以上の POS 取引補充注文を生み出すこともできました。以前であればもっと多くのハードウエアが必要となり、夜通しのバッチ作業を経て処理したものです。Google Cloud Dataflow を使えば、膨大な量の情報処理もリアルタイムで簡単になります。
Google Cloud Platform を活用する新たな機会を発見し続けながらも、我々チームはクラウドにおける未来のソリューション開発にコミットしています。申請中を含め 400 ある特許と 1.25億ドルの研究開発投資額から分かるように、我々はイノベーションを生きがいとしており、Google にも同じようにイノベーションを推進する文化があることをありがたく思っています。我々にとって Google との協働は、市場のリーダーであり続けるための新たな考え方を検討するための手助けとなっています。
Posted by John Sarvari, Group Vice President of Technology, JDA Software Group
Google BigQuery :パートナー エコシステムを拡大
2015年6月10日水曜日
* この投稿は、米国時間 6 月 8 日、Strategic Partner Development Manager の
Tanya Shastri によって投稿
されたものの抄訳です。
このブログで先日、ストリーミングの挿入やセキュリティ強化、EU ゾーンへの提供開始などの
Google BigQuery
の改良を発表しました。このような
BigQuery
を進化させていく一方で、パートナーのエコシステムを向上させる努力もしています。その目的は、皆さんのデータベースソリューションの選択肢を広げるためです。今回は、それらのソリューションについてお知らせします。
データの準備とロード
BigQuery へのデータロードをより簡単にしてほしいという皆様の声を聞き、選択肢を広げました。
BigQuery は
Google Cloud Storage
や
Google Cloud Logging
、
Google アナリティクス プレミアム
などをはじめとする様々な Google サービスと統合されています。
オンプレミスとクラウドのハイブリッド ソリューションや異なるフォーマットの様々なアプリケーションのデータソース、あるいはフルマネージドの ETL サービスのオプションを利用しているかもしれません。
SnapLogic
や
Talend
、
xPlenty
などのBigQuery 統合ソリューションで、BigQuery で分析を行うための準備ができます。
結果のビジュアライゼーション
リッチでインタラクティブなフロントエンドもBigQuery で構築できます。BigQuery は JDBC/ODBC などの技術をサポートしており、
Tableau
や
QlikTech
、
Bime
、
Looker
のサービスなどとインテグレーションが可能です。これらのオプションはシームレスなアクセスを提供し、非常に大きなデータセットの分析を通して素早いビジネスインサイトを可能にします。
BigQuery でのソリューション開発
進化し続ける BigQuery エコシステムは
Fluentd
などのオープンソースツールを含み、いくつものソースからデータ採集ができます。
re:dash
を使ってデータ コラボレーションを向上させたり、
OWOX
で BigQuery と Google スプレッドシートを合わせて使用したりできます。また
Hadoop connector for BigQuery
を使えば、Hadoop および Spark アプリケーションで BigQuery のデータにアクセスが可能になります。
さらに
Bimotics
や
Archipelago
などのサービスパートナーが、戦略的な洞察の提供やBigQuery によるエンド ツー エンド カスタム ソリューションの開発を行い、
クラウド流ビッグデータ
利用するためのお手伝いをします。
BigQuery エコシステムについて詳しくは
こちらをご覧ください
。また、
StackOverflow
にはアクティブな BigQuery コミュニティがありますので、ユーザー同士でお互いに質問をしたり、知識を共有することもできます。
- Posted by Tanya Shastri, Strategic Partner Development Manager
今度は Couchbase Server が Google Compute Engine 上で高パフォーマンスを実証、110 万 / 秒の書き込みを記録
2015年6月5日金曜日
* この投稿は、米国時間
5 月 28 日ポストの Google Cloud Platform ブログ
の抄訳です。
今回のゲストは Cihan Biyikoglu 氏です。Cihan は、ハイパフォーマンスのドキュメント データベースで、Google Cloud Platform パートナーでもある
Couchbase Server
の製品管理担当部長です。
昨年は、テクノロジー パートナー各社が Google Compute Engine 上で素晴らしいパフォーマンスを実証したというニュースでもちきりでした。特に、1 秒あたり 100 万回もの書き込みを記録した
Cassandra
には驚かされました。これを受け、我々 Couchbase も、どこまでスケールを上げてパフォーマンスあたりの価格を引き下げられるかを試してみることにしました。結果は満足のいくもので、それぞれ 500GB の SSD
永続ディスク
を接続したわずか 50 台の n1-standard-16 VM で、1 秒あたり 110 万という書き込みを継続して実行できたのです。
Couchbase Server
は、JSON ドキュメント データベースとキー バリュー ストアを組み込んだオープンソース、マルチモデルの NoSQL 分散データベースです。エンタープライズ ウェブやモバイル、IoT アプリケーションが一貫して高いパフォーマンス、可用性、スケーラビリティを発揮できるように、メモリ重視のアーキテクチャで作られています。Couchbase Server は、ドキュメント データベース、キー バリュー ストア、分散キャッシュとして使うことができます。そして、ほとんどのモバイル デバイスを含む複数のプラットフォームでの同期をサポートします。また、Google Compute Engine 上では特に優れた性能を発揮し、高いコスト パフォーマンスを示します。
Couchbase Server の今回のベンチマークに関する詳細は次のとおりです。
Couchbase Server は、それぞれ 200 バイトの値を持つアイテムを使って合計 30 億アイテムを操作しました。
Couchbase Server は、可用性と永続性のために 2 コピーのデータを使うようにセットアップされました(マスターが 1 つ、レプリカが 1 つ)。
平均レイテンシは 15m 秒、上から 95% 番目のレイテンシは 27m 秒でした。
ベンチマークを 1 時間実行するために要したコストの合計は $56.3 / 時でした。
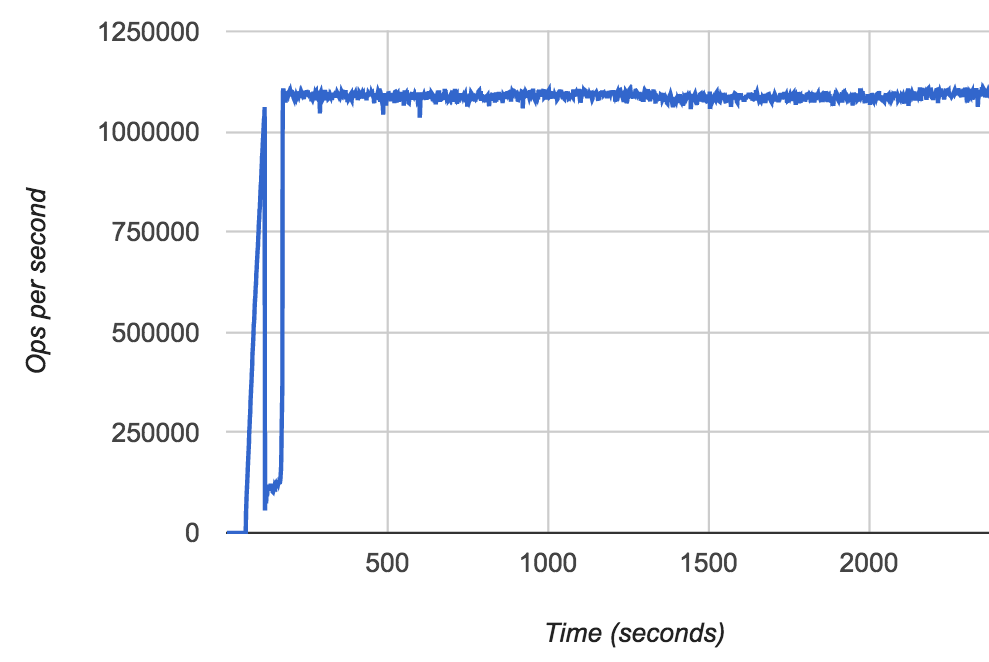
1 秒あたり 110 万書き込みを持続
ベンチマークの実行中、サーバーは一貫性、可用性、持続性を維持するように設定されています。書き込みが書き込みとして認められるのは、2 つのデータ ノードが書き込みを受け取ってからです。それからデータは、サーバーの永続ディスク(持続ストアになっています)にフラッシュされます。Couchbase Server の場合、このレプリケートされる永続データは持続フラグ “ReplicateTo=1” を指定して行います。
2 台のサーバーにデータをレプリケートし、Google Cloud Platform の永続ディスクにフラッシュすれば、Couchbase と Google Cloud Platform の持続性維持の機能がともに働き、持続性の保証が強化されます。また、持続性を保証するための作業中は書き込みレイテンシを抑えるため、Couchbase のメモリ ツー メモリのレプリケーションを使えます。
このレベルのパフォーマンスとサービス品質は、Couchbase がお客様に約束しているレベルと一致します。Couchbase のお客様には、数百万の顧客やユーザーを抱える大企業(多くは広告、テクノロジー、旅行、金融、電気通信といった業種)が含まれ、これらの企業は大規模なパーソナライゼーション、プロファイル管理、詐欺検出、デジタル通信などのミッション クリティカルなサービスを実装するために Couchbase を使っています。
我々は今回のベンチマーク結果に満足しており、Google Cloud Platform 上でのコスト パフォーマンスは Couchbase のユーザーにとってきわめて価値あるものだと考えています。ベンチマークの実行方法や数値の再現方法の詳細は
Couchbase ブログ
をご覧ください。
クラウドにおけるモバイルファースト開発
2015年6月4日木曜日
* この投稿は、米国時間 5 月 29 日、Product Marketing Manager の
Andy Tzou によって投稿
されたものの抄訳です。
ユーザーがモバイルファースト、そしてモバイルオンリーへと移っていくようになり、Google では、モバイル特有の課題に対するソリューションを用意することを目指してきました。例えば、デベロッパーがアプリのフロントエンド ユーザー エクスペリエンスに専念できるフル マネージド サービスや、デベロッパーがプロジェクトに必要なだけ管理できるプラットフォームと IaaS (infrastructure-as-a-service) などです。
モバイルの世界
Firebase
は、モバイルの世界において、これまでのプログラミング モデルの限界への画期的な一歩です。
RESTful
なモデルは、特にウェブにおいては大きな役割を果たしてきましたが、モバイルにおいてはどうでしょう。例えば、地下鉄へ入る時、飛行機モードにする時、接続エリアが制限された場所では、ネットワークの接続が断続的になったり、ネット環境自体が存在しないことさえあります。こんな環境でシームレスなサービスを作ることは難しいのに、ユーザーはオフラインでも動くアプリを求めるようになっています。
シームレスなオフライン機能
先日の Google I/O で Firebase は、
iOS
と
Android
での
オフライン
をネイティブサポートすると公表しました。Firebaseは、デベロッパーに代わってデータを維持し、ネットワークが利用できない場合には自動的にデータをデバイスにローカル保存します。接続が回復すると、自動的にアプリケーション データをクラウドに同期します。RESTful なモデルでは、デベロッパー自身がシームレスなオフライン環境を作ろうと努めなければならず、さらには、モバイル、デスクトップ、Android、iOS と、多種多様なクライアントにアプリケーション データを常に同期させることを期待され、デベロッパーにとって複雑さは勢いを増すばかりです。Firebase は、接続状態に関係なく、デベロッパーに代わって、デバイス全体にわたるデータ同期を管理します。
リアルタイム
オフラインに加え、ユーザーはアプリには素早く、迅速な応答を期待します。自分が乗る予定の車が徐々に近づいていることを地図上で確認したり、SNS への投稿が瞬時に表示されたり、Google ドキュメントでリアルタイムに共同編集したりです。リアルタイムであることは、ユーザー エクスペリエンスにおいて重要になってきました。
Firebase は、モバイル アプリケーションに対するリアルタイム同期アプローチの先駆けです。アプリケーション データは、デベロッパーの労力を必要とせずに、クラウドおよびクライアント デバイス全体とリアルタイムで同期されます。
インフラストラクチャとコンピューティング
さらに、Google Cloud Platform では、既存のバックエンドの管理または移行を検討するモバイル デベロッパーのために、
Google App Engine
や
Managed VM
、
Google Compute Engine
といったモバイル アプリ構築のためのさまざまなオプションを提供しています。長期的なジョブのホスト、分析の実行、またはカスタム ビジネス ロジックの記述のために最適です。
Google Cloud Platform では、モバイル デベロッパーおよびモバイルへの対応を最優先に考えています。例えば、
Rovio
の Angry Birds、
Feedly
のモバイル コンテンツ、
Citrix
のリモート コラボレーションなど、実際の例も読んでみてください。
Firebase
や
Google Cloud Platform
を使って、次世代の素晴らしいモバイル エクスペリエンス構築を!
-Posted by Andy Tzou, Product Marketing Manager, Google Cloud Platform
トレーニング コース (日本語字幕付き) : Python と Google App Engine でスケーラブルなアプリケーションを構築
2015年6月4日木曜日
* この投稿は、米国時間 6 月 3 日、Technical Training and Certification Manager の
John Souchak によって投稿
されたものの抄訳です。
スケーラビリティ問題を解決する
あなたの書いたアプリケーションが想像以上の成功をおさめている様子を想像してください。驚くほどのトラフィック量にどう対処しますか。ご心配なく!Google は Udacity に新しい
オンライン トレーニング コース
を開設しました。強靭でスケーラブルなアプリケーションをPython で構築するために必要なすべての知識を身に付けることができるのです。
去年の夏に
Developing Scalable Apps in Java
を公開したところ、Python のリクエストを多くいただいたので、ご要望にこたえ、今回
Developing Scalable Apps for Python
をリリースすることとなりました。
Magnus Hyttsten
、
Jocelyn Becker
、そして Karl Krueger の 3 名が作り上げたこのコースでは、Google App Engine でスケーラブルなアプリケーションを構築することをメインコンセプトとして解説していきます。ステップ バイ ステップで、モバイルでもウェブでも動くアプリを実際に作ってみましょう。
* ビデオは英語ですが、ほとんどのレッスンに日本語の字幕がついています。
オンライン コースの内容
コース終了までには、以下のことを達成できるでしょう:
スケールするアプリケーション開発のために、どうやって Task Queues や Memcache、Edge Caching、Datastore などのテクノロジーを組み合わせるのかを学びます。
実際に使える機能をもつ、スケーラブルなアプリケーションをゼロから構築できるようになります。
興味がある方は、Udacity コースの
Python
バージョン、または
Java
バージョンにサインアップしてください。
Jenkins、Packer、Kubernetes でイメージ ビルドを自動化
2015年6月1日月曜日
* この投稿は、米国時間 5 月 27 日、Solutions Architect の
Evan Brown によって投稿
されたものの抄訳です。
移植性と処理スピードを高めることは、とりわけクラウドでは歓迎されます。そこで今回、
新しいソリューション ペーパー
とオープンソースのリファレンス実装をリリースしました。これは、
Google Compute Engine
仮想マシンのブートをさらに高速化するのに役立ち、Compute Engine イメージとともに Docker 用のポータブル イメージを自動的にビルドできるようにします。
Compute Engine インスタンスでアプリケーションを実行するときは、最初に 1 台以上の仮想マシンをデプロイし、アプリケーションが動作するようにシステムを設定しなければなりません。通常は、アプリケーションとその依存ファイルをインストールしてから、データベース接続文字列や API キーといった、アプリケーションが必要とする他のコンフィグレーションをセットアップすることになります。
ブート後に各インスタンスに接続して各要素を設定すれば、手作業でのセットアップも可能です。しかし、それでは時間がかかり、エラーも起きやすくなって、首尾一貫しない特異なインスタンスが生まれることになります。起動時に自動的にコンフィギュレーション スクリプトを実行したとしても、反復可能でスケーラブルな分だけましにはなりますが、それでも事前に行わなければならない作業が多く、依然としてヒューマン エラーに悩まされることでしょう。さらに、インストールしようとしているパッケージが一時的に入手できない状態になっていると、そのインスタンスはブートしません。また、インストールしようとしているパッケージが大きかったりコンパイルを必要とするものだったりすると、ブート時間が長くなり、自動的なスケーリングに影響が及びます。
ブート時間を減らしながら信頼性を高めるには、インスタンスを起動する前にカスタム イメージをビルドすることが最も優れた方法です。本日、Google は
Jenkins
、
Packer
、
Kubernetes
でイメージ ビルドを自動化する方法を解説した
ソリューション ペーパー
と
オープンソースのリファレンス実装
を公開します。これを見れば、広く使われているオープンソース テクノロジーを使って、Compute Engine、Docker ベース アプリケーションのために継続的にイメージをビルドする方法が学べます。中央のプロジェクトでイメージをビルドし、組織内の他のプロジェクトとイメージを共有して、継続的インテグレーション( CI )パイプラインにステップとしてイメージ ビルドを組み込むのです。
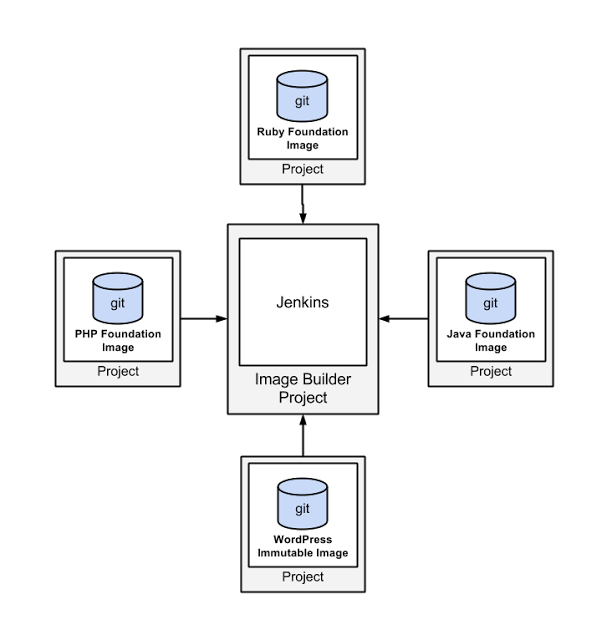
下図は、Compute Engine、Docker イメージをビルドするためのハブとなる Jenkins イメージ ビルダーを示しています。
図 1 : Jenkins がアカウント内の他のプロジェクトのためにイメージをビルドする
ソリューション ペーパーでは、セキュアでスケーラブルなイメージ ビルド パイプラインの作り方に加え、Kubernetes 上で信頼性の高い Jenkins インストレーションを実行する方法、Jenkins のバックアップ / 復元とワーカー ノードのスケーリングの方法も解説しています。
Jenkins
、
Packer
、
Kubernetes
を使ってインスタンスとコンテナの起動を高速化し、信頼性を上げるには、
自動化されたイメージ ビルドに関するソリューション ページ
を参照してください。それが終わったら、
リファレンス実装のチュートリアル
に従ってインフラストラクチャのデプロイに進んでください。ご意見はいつでも歓迎します。チュートリアルに関する提案については
GitHub プル リクエスト
か
イシュー
、Google Cloud Platform をどのように使っているかについては
Google+
や Twitter の
@evandbrown
までお知らせください。
-Posted by Evan Brown, Solutions Architect
12 か月間のトライアル
300 ドル相当が無料になるトライアルで、あらゆる GCP プロダクトをお試しいただけます。
Labels
.NET
.NET Core
.NET Core ランタイム
.NET Foundation
#gc_inside
#gc-inside
#GoogleCloudSummit
#GoogleNext18
#GoogleNext19
#inevitableja
Access Management
Access Transparency
Advanced Solutions Lab
AI
AI Hub
AlphaGo
Ansible
Anthos
Anvato
Apache Beam
Apache Maven
Apache Spark
API
Apigee
APIs Explore
App Engine
App Engine Flex
App Engine flexible
AppArmor
AppEngine
AppScale
AprilFool
AR
Artifactory
ASL
ASP.NET
ASP.NET Core
Attunity
AutoML Vision
AWS
Big Data
Big Data NoSQL
BigQuery
BigQuery Data Transfer Service
BigQuery GIS
Billing Alerts
Bime by Zendesk
Bitbucket
Borg
BOSH Google CPI
Bower
bq_sushi
BreezoMeter
BYOSL
Capacitor
Chromium OS
Client Libraries
Cloud API
Cloud Armor
Cloud Audit Logging
Cloud AutoML
Cloud Bigtable
Cloud Billing Catalog API
Cloud Billing reports
Cloud CDN
Cloud Client Libraries
Cloud Console
Cloud Consoleアプリ
Cloud Container Builder
Cloud Dataflow
Cloud Dataflow SDK
Cloud Datalab
Cloud Dataprep
Cloud Dataproc
Cloud Datastore
Cloud Debugger
Cloud Deployment Manager
Cloud Endpoints
Cloud Firestore
Cloud Foundry
Cloud Foundry Foundation
Cloud Functions
Cloud Healthcare API
Cloud HSM
Cloud IAM
Cloud IAP
Cloud Identity
Cloud IoT Core
Cloud Jobs API
Cloud KMS
Cloud Launcher
Cloud Load Balancing
Cloud Machine Learning
Cloud Memorystore
Cloud Memorystore for Redis
Cloud monitoring
Cloud NAT
Cloud Natural Language API
Cloud Networking
Cloud OnAir
Cloud OnBoard
cloud Pub/Sub
Cloud Resource Manager
Cloud Resource Manager API
Cloud SCC
Cloud SDK
Cloud SDK for Windows
Cloud Security Command Center
Cloud Services Platform
Cloud Source Repositories
Cloud Spanner
Cloud Speech API
Cloud Speech-to-Text
Cloud SQL
Cloud Storage
Cloud Storage FUSE
Cloud Tools for PowerShell
Cloud Tools PowerShell
Cloud TPU
Cloud Translation
Cloud Translation API
Cloud Virtual Network
Cloud Vision
Cloud VPC
CloudBerry Backup
CloudBerry Lab
CloudConnect
CloudEndure
Cloudflare
Cloudian
CloudML
Cluster Federation
Codefresh
Codelabs
Cohesity
Coldline
Colossus
Compute Engine
Compute user Accounts
Container Engine
Container Registry
Container-Optimized OS
Container-VM Image
Couchbase
Coursera
CRE
CSEK
Customer Reliability Engineering
Data Studio
Databases
Dbvisit
DDoS
Debugger
Dedicated Interconnect
deep learning
Deployment Manager
Developer Console
Developers
DevOps
Dialogflow
Disney
DLP API
Docker
Dockerfile
Drain
Dreamel
Eclipse
Eclipse Orion
Education Grants
Elasticsearch
Elastifile
Energy Sciences Network
Error Reporting
ESNet
Evernote
FASTER
Fastly
Firebase
Firebase Analytics
Firebase Authentication
Flexible Environment
Forseti Security
G Suite
Gartner
gcloud
GCP
GCP Census
GCP 移行ガイド
GCP 認定資格チャレンジ
GCPUG
GCP導入事例
gcsfuse
GEO
GitHub
GitLab
GKE
Go
Go 言語
Google App Engine
Google Apps
Google Certified Professional - Data Engineer
Google Cloud
Google Cloud Certification Program
Google Cloud Client Libraries
Google Cloud Console
Google Cloud Dataflow
Google Cloud Datalab
Google Cloud Datastore
Google Cloud Endpoints
Google Cloud Explorer
Google Cloud Identity and Access Management
Google Cloud INSIDE
Google Cloud INSIDE Digital
Google Cloud INSIDE FinTech
Google Cloud Interconnect
Google Cloud Launcher
Google Cloud Logging
Google Cloud Next '18 in Tokyo
Google Cloud Next '19 in Tokyo
Google Cloud Platform
Google Cloud Resource Manager
Google Cloud Security Scanner
Google Cloud Shell
Google Cloud SQL
Google Cloud Storage
Google Cloud Storage Nearline
Google Cloud Summit '18
Google Cloud Summit ’18
Google Cloud Tools for IntelliJ
Google Code
Google Compute Engine
Google Container Engine
Google Data Analytics
Google Data Studio
Google Date Studio
Google Deployment Manager
Google Drive
Google Earth Engine
Google Genomics
Google Kubernetes Engine
Google maps
google maps api
Google Maps APIs
Google Maps Platform
Google SafeSearch
Google Service Control
Google Sheets
Google Slides
Google Translate
Google Trust Services
Google VPC
Google マップ
Google 公認プロフェッショナル
GoogleNext18
GPU
Gradle
Grafeas
GroupBy
gRPC
HA / DR
Haskell
HEPCloud
HIPAA
Horizon
HTCondor
IaaS
IAM
IBM
IBM POWER9
icon
IERS
Improbable
INEVITABLE ja night
inevitableja
InShorts
Intel
IntelliJ
Internal Load Balancing
Internet2
IoT
Issue Tracker
Java
Jenkins
JFrog
JFrog Artifactory SaaS
Jupiter
Jupyter
Kaggle
Kayenta
Khan Academy
Knative
Komprise
kubefed
Kubeflow Pipelines
Kubernetes
KVM
Landsat
load shedding
Local SSD
Logging
Looker
Machine Learning
Magenta
Managed Instance Group
Managed Instance Group Updater
Maps API
Maps-sensei
Mapsコーナー
Maven
Maxon Cinema 4D
MightyTV
Mission Control
MongoDB
MQTT
Multiplay
MySQL
Nearline
Network Time Protocol
Networking
neural networks
Next
Node
NoSQL
NTP
NuGet パッケージ
OCP
OLDISM
Open Compute Project
OpenCAPI
OpenCAPI Consortium
OpenShift Dedicated
Orbitera
Organization
Orion
Osaka
Paas
Panda
Particle
Partner Interconnect
Percona
Pete's Dragon
Pivotal
Pivotal Cloud Foundry
PLCN
Podcast
Pokemon GO
Pokémon GO
Poseidon
Postgre
PowerPoint
PowerShell
Professional Cloud Network Engineer
Protocol Buffers
Puppet
Pythian
Python
Qwiklabs
Rails
Raspberry Pi
Red Hat
Redis
Regional Managed Instance Groups
Ruby
Rust
SAP
SAP Cloud Platform
SC16
ScaleArc
Secure LDAP
Security & Identity
Sentinel-2
Service Broker
Serving Websites
Shared VPC
SideFX Houdini
SIGOPS Hall of Fame Award
Sinatra
Site Reliability Engineering
Skaffold
SLA
Slack
SLI
SLO
Slurm
Snap
Spaceknow
SpatialOS
Spinnaker
Spring
SQL Server
SRE
SSL policies
Stack Overflow
Stackdriver
Stackdriver Agent
Stackdriver APM
Stackdriver Debugger
Stackdriver Diagnostics
Stackdriver Error Reporting
Stackdriver Logging
Stackdriver Monitoring
Stackdriver Trace
Stanford
Startups
StatefulSets
Storage & Databases
StorReduce
Streak
Sureline
Sysbench
Tableau
Talend
Tensor Flow
Tensor Processing Unit
TensorFlow
Terraform
The Carousel
TPU
Trace
Transfer Appliance
Transfer Service
Translate API
Uber
Velostrata
Veritas
Video Intelligence API
Vision API
Visual Studio
Visualization
Vitess
VM
VM Image
VPC Flow Logs
VR
VSS
Waze
Weave Cloud
Web Risk AP
Webyog
Wide and Deep
Windows Server
Windows ワークロード
Wix
Worlds Adrift
Xplenty
Yellowfin
YouTube
Zaius
Zaius P9 Server
Zipkin
ZYNC Render
アーキテクチャ図
イベント
エラーバジェット
エンティティ
オンライン教育
クラウド アーキテクト
クラウド移行
グローバル ネットワーク
ゲーム
コードラボ
コミュニティ
コンテスト
コンピューティング
サーバーレス
サービス アカウント
サポート
ジッター
ショート動画シリーズ
スタートガイド
ストレージ
セキュリティ
セミナー
ソリューション ガイド
ソリューション: メディア
データ エンジニア
データセンター
デベロッパー
パートナーシップ
ビッグデータ
ファジング
プリエンプティブル GPU
プリエンプティブル VM
フルマネージド
ヘルスケア
ホワイトペーパー
マイクロサービス
まっぷす先生
マルチクラウド
リージョン
ロード シェディング
運用管理
可用性
海底ケーブル
機械学習
金融
継続的デリバリ
月刊ニュース
資格、認定
新機能、アップデート
深層学習
深層強化学習
人気記事ランキング
内部負荷分散
認定試験
認定資格
料金
Archive
2019
8月
7月
6月
5月
4月
3月
2月
1月
2018
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2017
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2016
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2015
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2014
12月
11月
10月
9月
8月
6月
5月
4月
3月
2月
Feed
月刊ニュースレターに
登録
新着ポストをメールで受け取る
Follow @GoogleCloud_jp










![GCP_Jupiter_GooglePlus[1].png](https://lh5.googleusercontent.com/FStRzy8BNbjLkALzM4UFPY2SXBzVO-BytCzgNgeHlzW9CSn-Y2p9ZDNNIx5lTC-V8BRrs1dhtU6VRXWnhoLHs-uczZqm9j-DDlUyuNzvZdR3bXkMMMI-1nI6zDt8FsN_ga3xBDM)