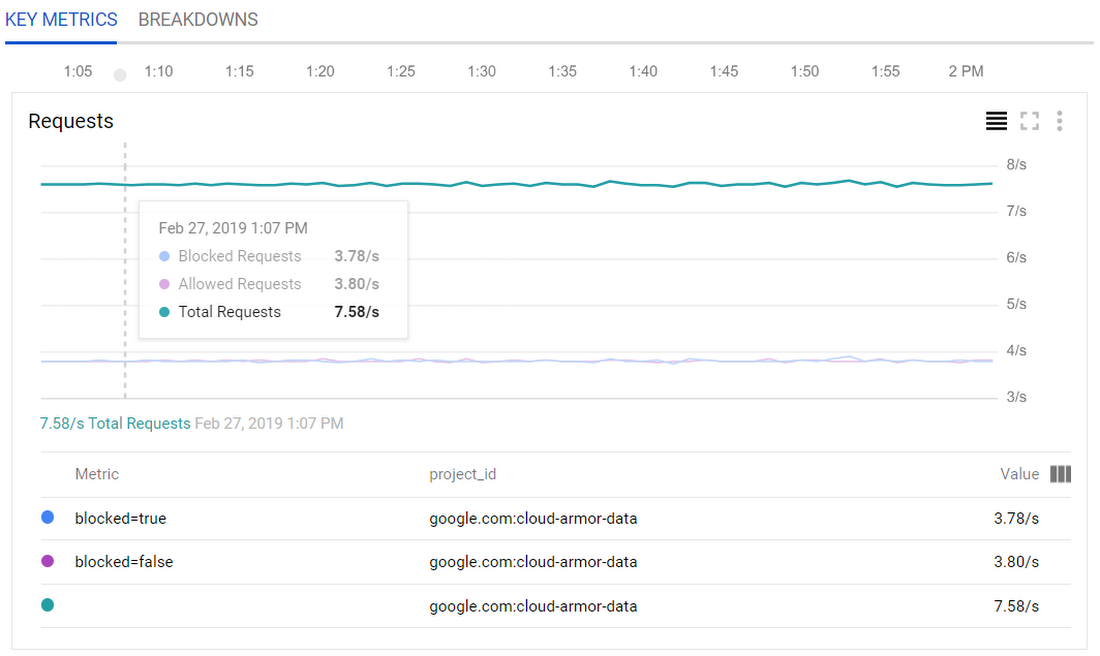
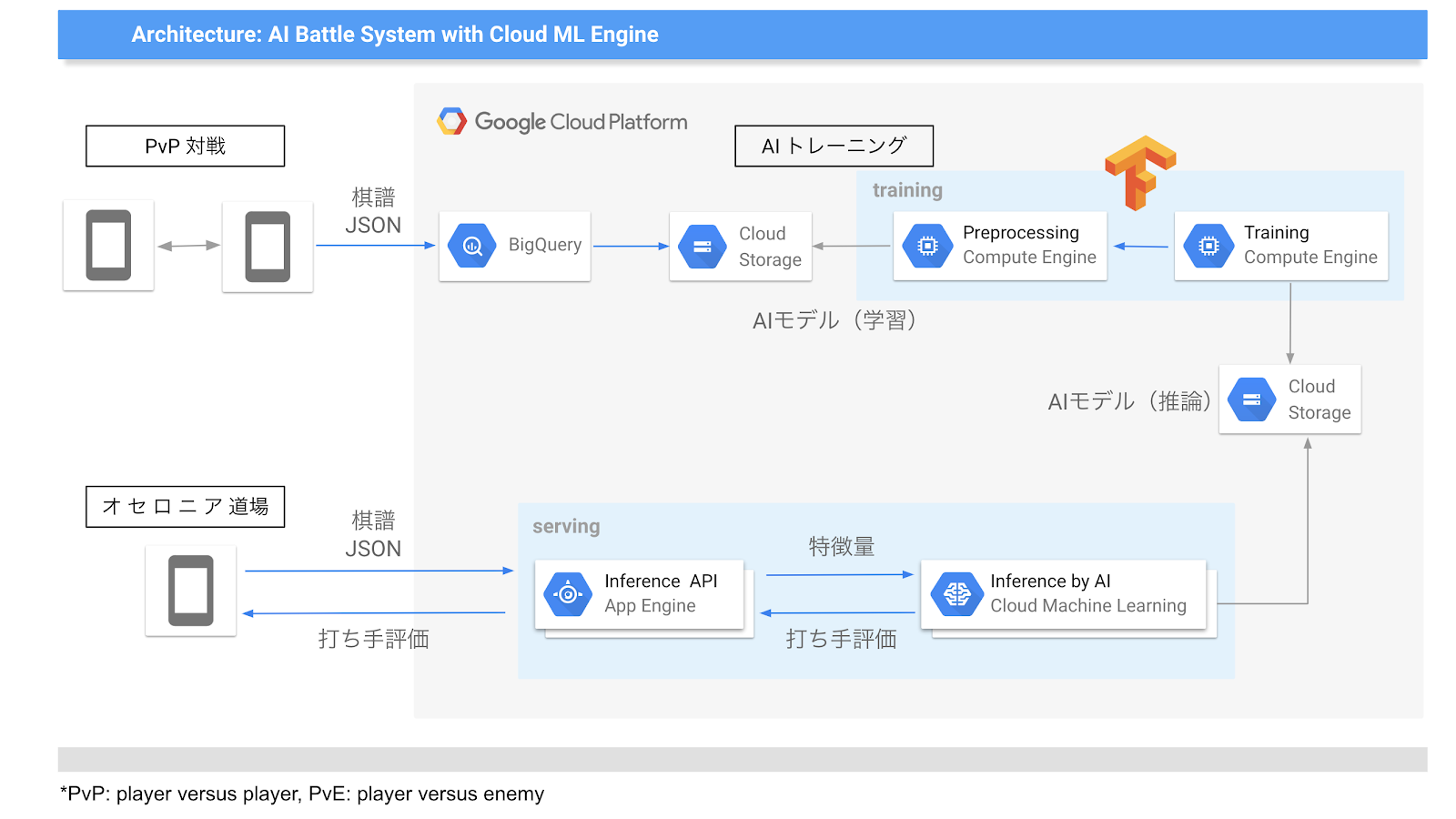
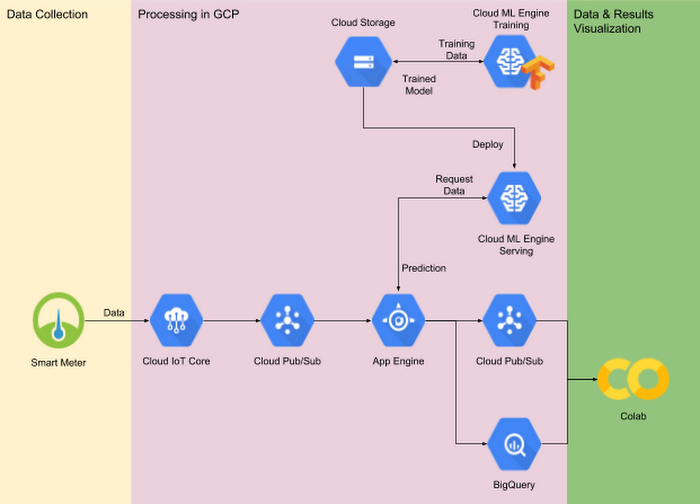
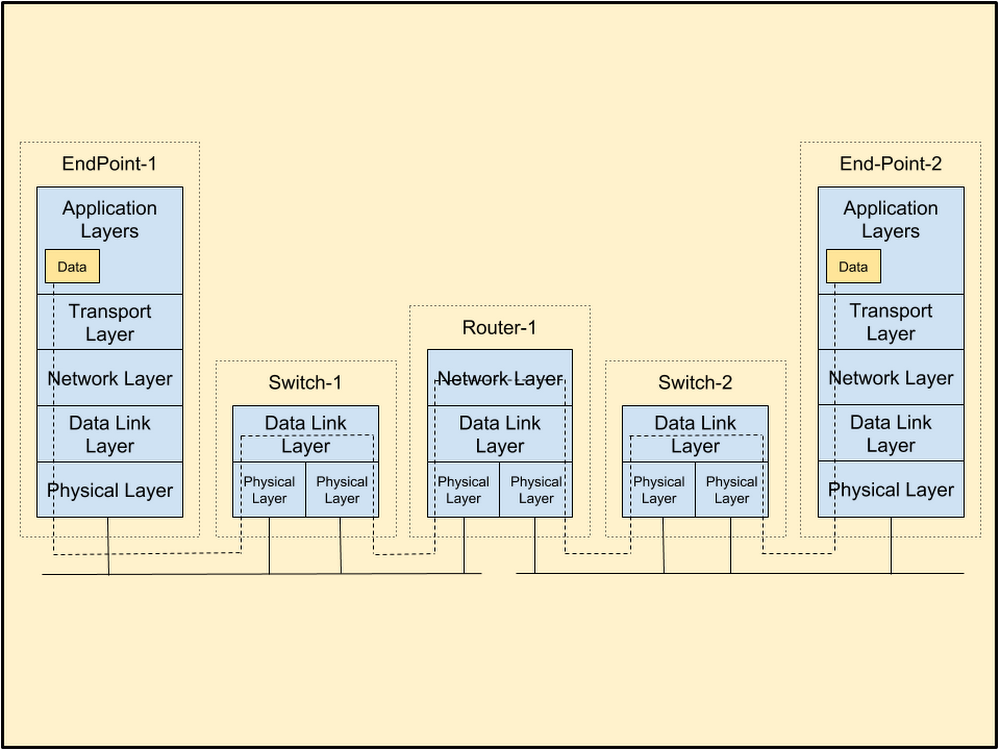
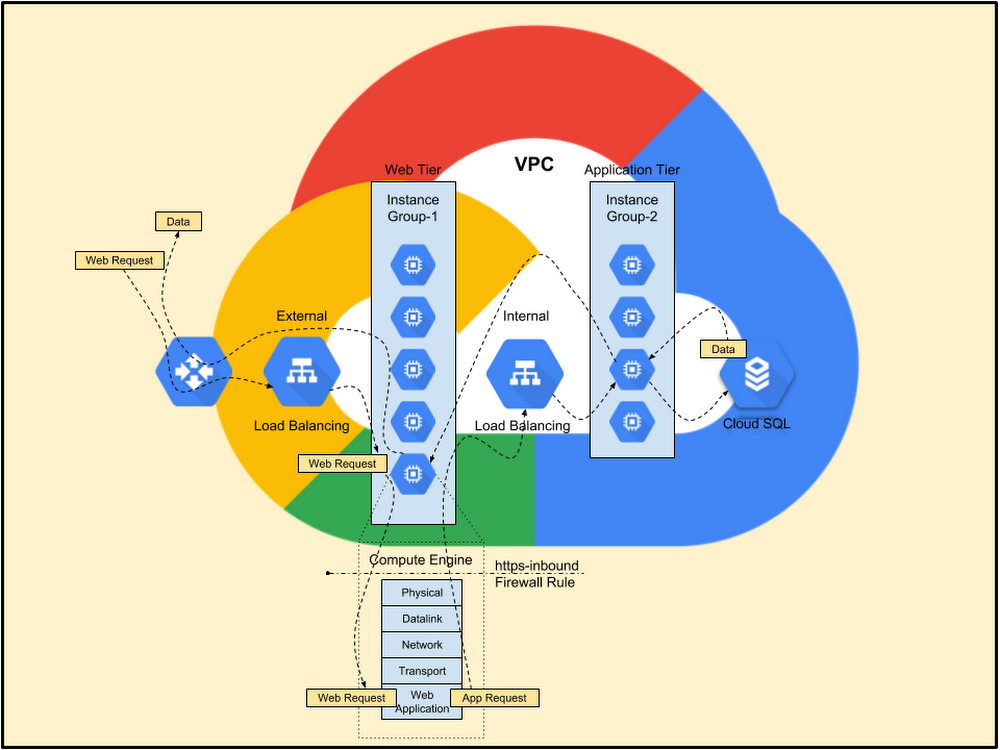
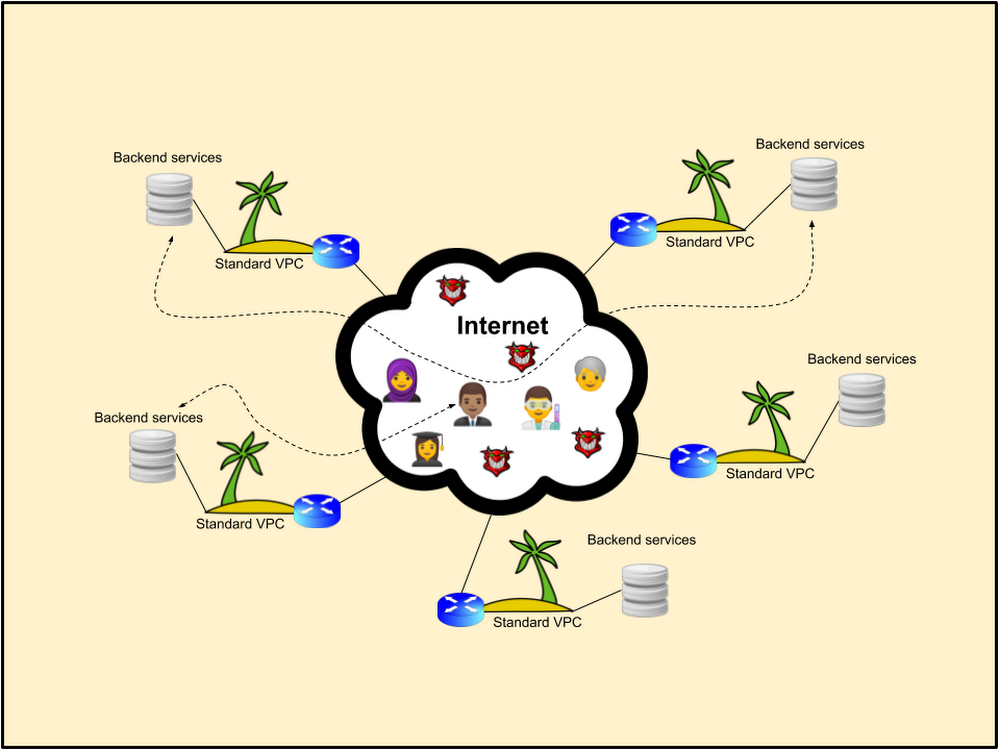
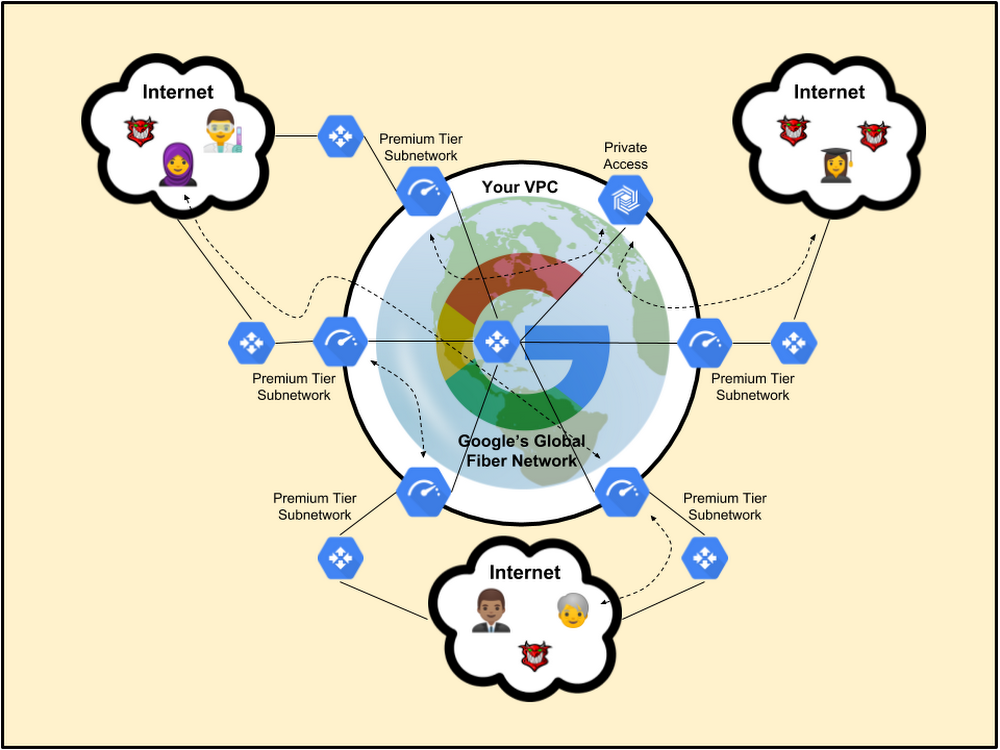
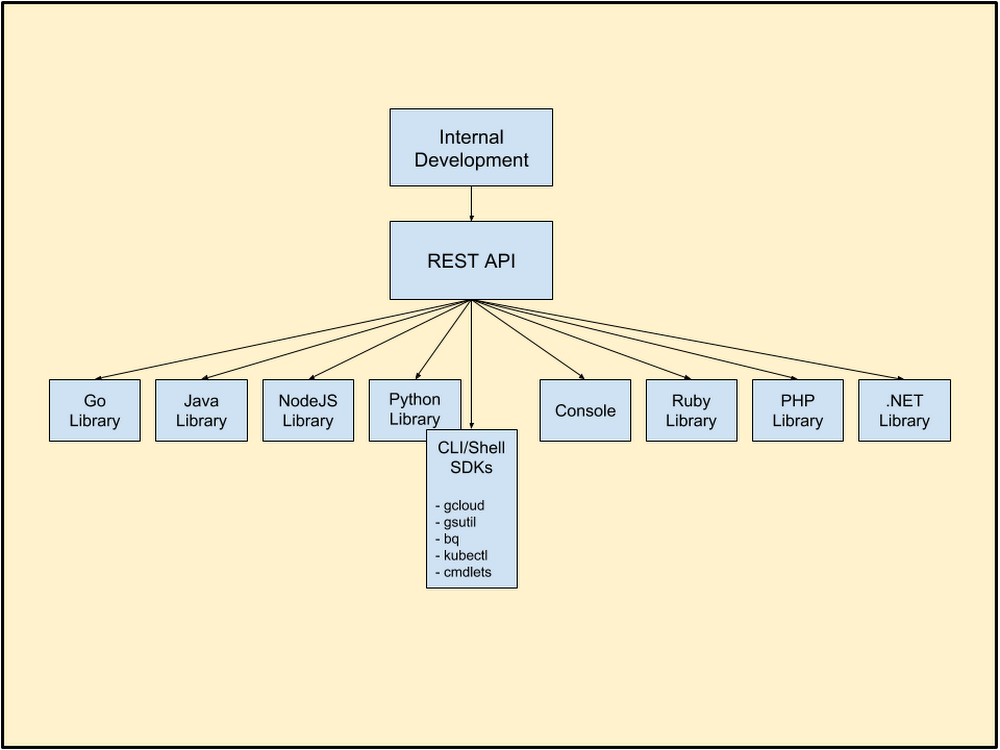
Google Kubernetes Engine、Cloud SQL、Google Cloud Storage、Cloud Pub/Sub、Google Cloud Load Balancing、Cloud IoT Core、Google BigQuery など
2016 年に創業された、宇宙通信ベンチャー。人工衛星との通信を行う地上局共有プラットフォーム「StellarStation」のほか、世界中の衛星運用者とメーカー、大学、サービス提供者を繋ぐ EC プラットフォーム「Makesat」など、人類が宇宙空間をより有意義に活用できるようにするためのサービスを開発・提供している。現在の従業員数は 22 名(2018 年 12 月現在)。
Google Cloud Machine Learning Engine、Google BigQuery、Google Compute Engine、Google App Engine、Google Stackdriver、Cloud Pub/Sub、Google Cloud Functions、Cloud Datastore など
1999 年に設立されたモバイルを中心としたインターネット サービス企業。2017 年度の売上高は 1,394 億円。収益の中心はゲーム事業となっているが、その他にもタクシー配車アプリやカーシェアリングなどを中心としたオート モーティブ事業や、横浜DeNAベイスターズを運営するスポーツ事業など、幅広く展開。ゲームに留まらない多彩なビジネスに挑戦している。従業員数は 2,475 名(連結 / 2018 年 3 月末時点)
Google Kubernetes Engine、Google Cloud Load Balancing、 Container Registry、Stackdriver Logging、Google BigQuery、 Cloud SQL、Google Cloud Storage、Cloud Memorystore
2013 年 6 月設立。代表取締役社長は今泉 卓也氏。ゲーム情報等の提供をおこなうメディア事業を展開する株式会社GameWith は国内最大級のゲーム情報・攻略サイト「GameWith」を運営し、ゲームを有利に進めるための情報を提供する「ゲーム攻略」、ゲームを見つけるための情報を提供する「ゲームレビュー」、ゲームユーザー同士で交流できる機能を提供する「コミュニティ」、専属のゲームタレントが YouTube 上でおこなう「動画配信」という主な 4 つのコンテンツを提供しています。2018 年 12 月には、スマートフォン向け WEB マンガサービス「MangaWith」をリリース。今後は日本のみならず海外展開やブロックチェーン、eスポーツなどの事業を拡大予定。
def publish(self): # Finish if inactive if not self._active: return # Process network events. self.client.loop() # Wait if backoff is required. if Publisher.should_backoff: # If backoff time is too large, give up. if Publisher.minimum_backoff_time > MAXIMUM_BACKOFF_TIME: print('Exceeded maximum backoff time. Giving up.') return # Otherwise, wait and connect again. delay = (Publisher.minimum_backoff_time + random.randint(0, 1000) / 1000.0) print('Waiting for {} before reconnecting.'.format(delay)) time.sleep(delay) Publisher.minimum_backoff_time *= 2 self.client.connect(self.mqtt_bridge_hostname, self.mqtt_bridge_port) # Refresh token if JWT IAT has expired. seconds_since_issue = (datetime.datetime.utcnow() - self._jwt_iat).seconds if seconds_since_issue > 60 * self.jwt_exp_mins: print('Refreshing token after {}s').format(seconds_since_issue) self._jwt_iat = datetime.datetime.utcnow() self.client = self.get_client() # Generate payload d, t = self._data[self._count] Publisher.rotate_message(self._msg, d, t) payload = json.dumps(self._msg).encode('utf-8') # Publish "payload" to the MQTT topic. qos=1 means at least once # delivery. Cloud IoT Core also supports qos=0 for at most once # delivery. self.client.publish(self._mqtt_topic, payload, qos=1) self._count += 1
def publish(self):
# Finish if inactive
if not self._active:
return
# Process network events.
self.client.loop()
# Wait if backoff is required.
if Publisher.should_backoff:
# If backoff time is too large, give up.
if Publisher.minimum_backoff_time > MAXIMUM_BACKOFF_TIME:
print('Exceeded maximum backoff time. Giving up.')
# Otherwise, wait and connect again.
delay = (Publisher.minimum_backoff_time +
random.randint(0, 1000) / 1000.0)
print('Waiting for {} before reconnecting.'.format(delay))
time.sleep(delay)
Publisher.minimum_backoff_time *= 2
self.client.connect(self.mqtt_bridge_hostname, self.mqtt_bridge_port)
# Refresh token if JWT IAT has expired.
seconds_since_issue = (datetime.datetime.utcnow() - self._jwt_iat).seconds
if seconds_since_issue > 60 * self.jwt_exp_mins:
print('Refreshing token after {}s').format(seconds_since_issue)
self._jwt_iat = datetime.datetime.utcnow()
self.client = self.get_client()
# Generate payload
d, t = self._data[self._count]
Publisher.rotate_message(self._msg, d, t)
payload = json.dumps(self._msg).encode('utf-8')
# Publish "payload" to the MQTT topic. qos=1 means at least once
# delivery. Cloud IoT Core also supports qos=0 for at most once
# delivery.
self.client.publish(self._mqtt_topic, payload, qos=1)
self._count += 1
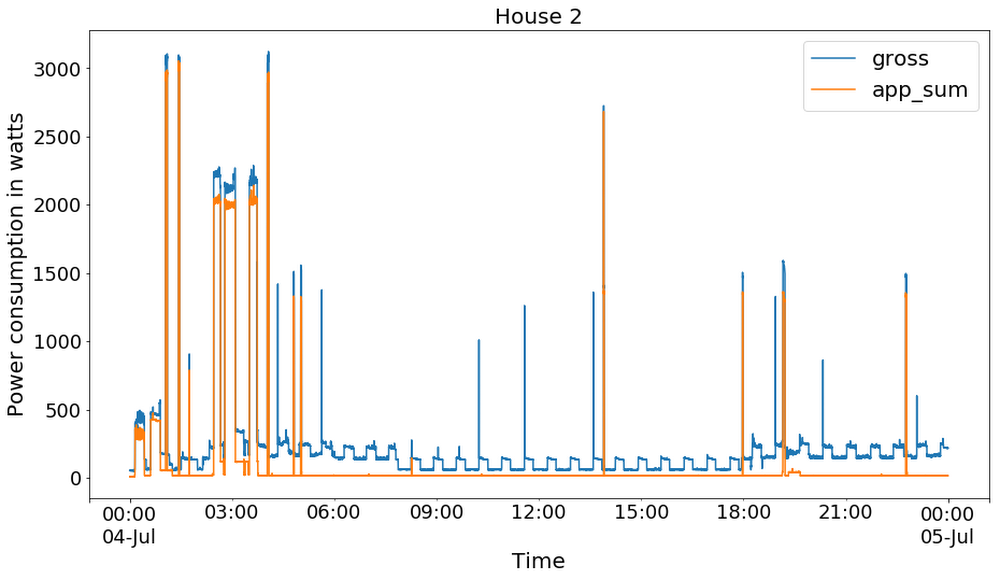
EnergyDisaggregationDemo_Client.ipynb
EnergyDisaggregationDemo_View.ipynb
README
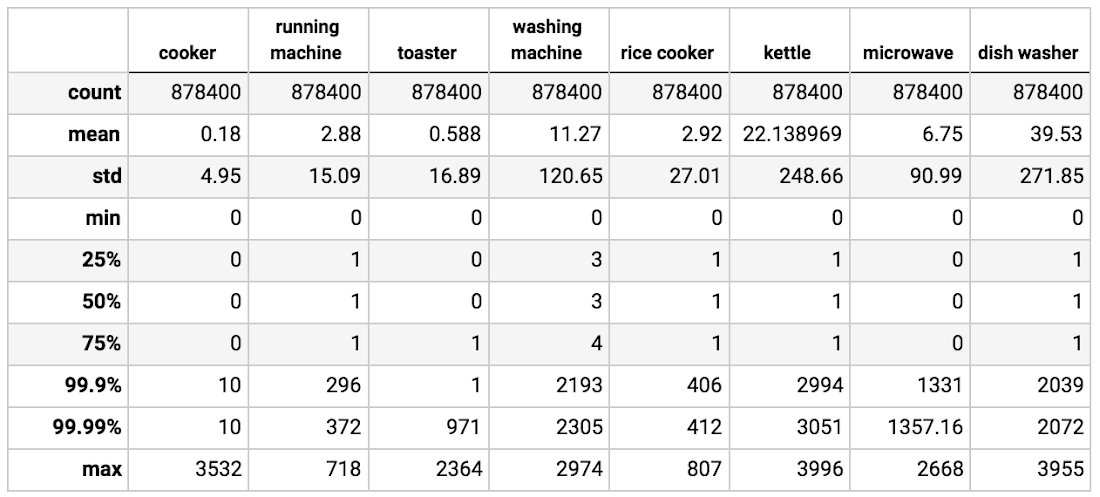
def _mk_data(*argv): data = {'ActivePower_{}'.format(i+1): x for i, x in enumerate(tf.split(argv[0], seq_len))} flags = [tf.split(x, seq_len)[-1][0] for x in argv[1:]] return (data, tf.cast(tf.stack(flags), dtype=tf.uint8)) record_defaults = [tf.float64,] + [tf.int32] * (len(cols) - 1) dataset = tf.contrib.data.CsvDataset( [data_file,], record_defaults, header=True, select_cols=cols) dataset = dataset.apply( tf.contrib.data.sliding_window_batch(window_size=seq_len)) dataset = dataset.map(_mk_data, num_parallel_calls=os.cpu_count())
def _mk_data(*argv):
data = {'ActivePower_{}'.format(i+1): x
for i, x in enumerate(tf.split(argv[0], seq_len))}
flags = [tf.split(x, seq_len)[-1][0] for x in argv[1:]]
return (data, tf.cast(tf.stack(flags), dtype=tf.uint8))
record_defaults = [tf.float64,] + [tf.int32] * (len(cols) - 1)
dataset = tf.contrib.data.CsvDataset(
[data_file,], record_defaults, header=True, select_cols=cols)
dataset = dataset.apply(
tf.contrib.data.sliding_window_batch(window_size=seq_len))
dataset = dataset.map(_mk_data, num_parallel_calls=os.cpu_count())
tf.data
def _filter_data(data, labels): rand_num = tf.random_uniform([], 0, 1, dtype=tf.float64) thresh = tf.constant(filter_prob, dtype=tf.float64, shape=[]) is_all_zero = tf.equal(tf.reduce_sum(labels), 0) return tf.logical_or(tf.logical_not(is_all_zero), tf.less(rand_num, thresh)) if train_flag: dataset = dataset.filter(_filter_data)
def _filter_data(data, labels):
rand_num = tf.random_uniform([], 0, 1, dtype=tf.float64)
thresh = tf.constant(filter_prob, dtype=tf.float64, shape=[])
is_all_zero = tf.equal(tf.reduce_sum(labels), 0)
return tf.logical_or(tf.logical_not(is_all_zero), tf.less(rand_num, thresh))
if train_flag:
dataset = dataset.filter(_filter_data)
if shuffle: dataset = dataset.apply( tf.contrib.data.shuffle_and_repeat( buffer_size=batch_size * 10, count=num_epochs)) else: dataset = dataset.repeat(count=num_epochs) dataset = dataset.batch(batch_size) dataset = dataset.prefetch(buffer_size=None)
if shuffle:
tf.contrib.data.shuffle_and_repeat(
buffer_size=batch_size * 10,
count=num_epochs))
else:
dataset = dataset.repeat(count=num_epochs)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(buffer_size=None)
n
m
tf.layers
tf.nn
tf.keras
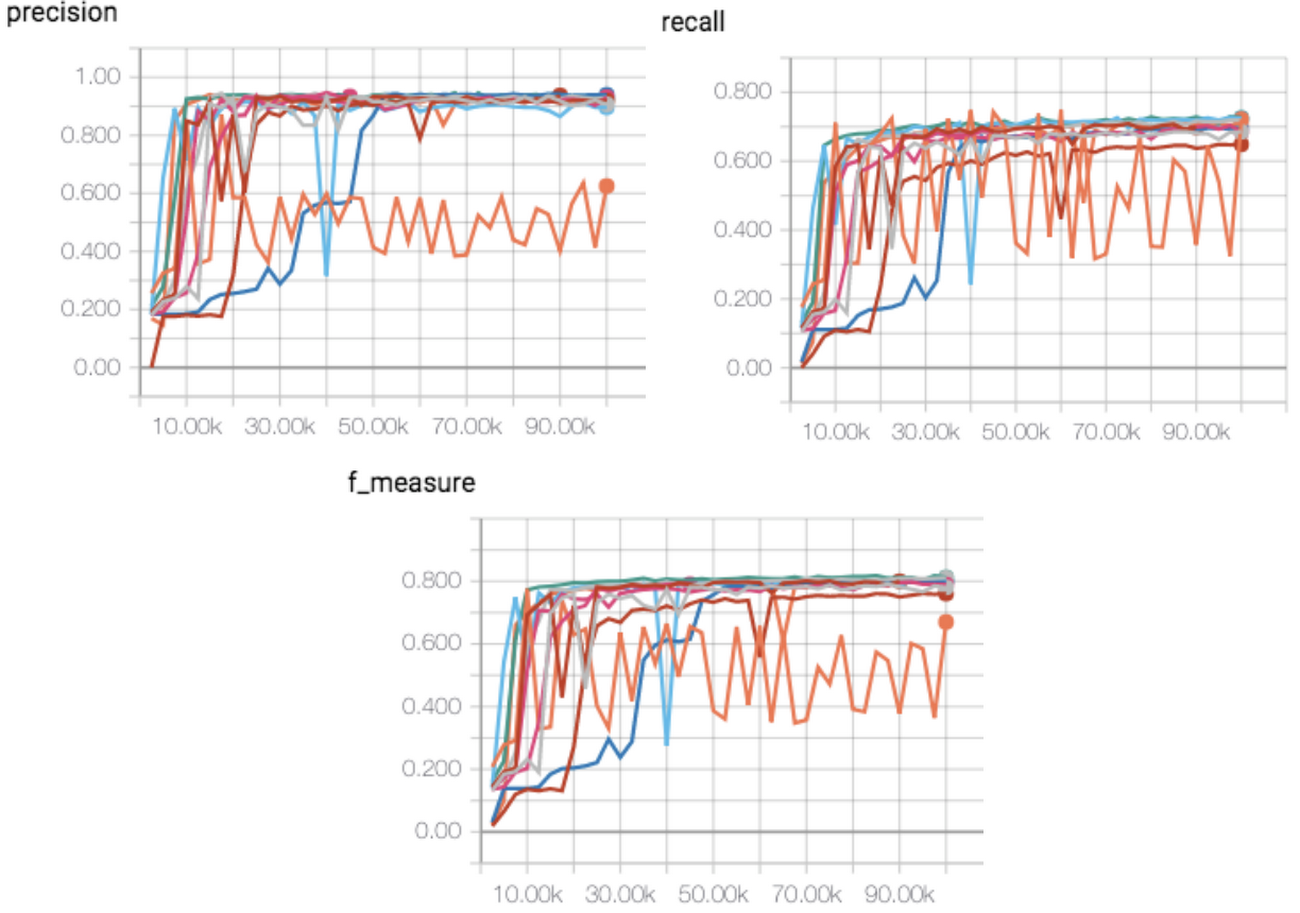
# RNN network using multilayer LSTM cells = [tf.nn.rnn_cell.DropoutWrapper( tf.nn.rnn_cell.LSTMCell(params['lstm_size']), input_keep_prob=1 - params['dropout_rate']) for _ in range(params['num_layers'])] lstm = tf.nn.rnn_cell.MultiRNNCell(cells) # Initialize the state of each LSTM cell to zero state = lstm.zero_state(batch_size, dtype=tf.float32) outputs, states = tf.nn.dynamic_rnn(cell=lstm, inputs=tf.expand_dims(seq_data, -1), initial_state=state, dtype=tf.float32) # Flatten the 3D output to 2D flatten_outputs = tf.layers.Flatten()(outputs) logits = tf.layers.Dense(params['num_appliances'])(flatten_outputs)
# RNN network using multilayer LSTM
cells = [tf.nn.rnn_cell.DropoutWrapper(
tf.nn.rnn_cell.LSTMCell(params['lstm_size']), input_keep_prob=1 - params['dropout_rate'])
for _ in range(params['num_layers'])]
lstm = tf.nn.rnn_cell.MultiRNNCell(cells)
# Initialize the state of each LSTM cell to zero
state = lstm.zero_state(batch_size, dtype=tf.float32)
outputs, states = tf.nn.dynamic_rnn(cell=lstm,
inputs=tf.expand_dims(seq_data, -1),
initial_state=state,
dtype=tf.float32)
# Flatten the 3D output to 2D
flatten_outputs = tf.layers.Flatten()(outputs)
logits = tf.layers.Dense(params['num_appliances'])(flatten_outputs)
# RNN network using multilayer LSTM with the help of Keras model = keras.Sequential() for _ in range(params['num_layers']): model.add( keras.layers.LSTM(params['lstm_size'], dropout=params['dropout_rate'], return_sequences=True) ) # Flatten the 3D output to 2D model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(params['num_appliances'])) logits = model(tf.expand_dims(seq_data, -1))
# RNN network using multilayer LSTM with the help of Keras
model = keras.Sequential()
for _ in range(params['num_layers']):
model.add(
keras.layers.LSTM(params['lstm_size'],
dropout=params['dropout_rate'],
return_sequences=True)
)
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(params['num_appliances']))
logits = model(tf.expand_dims(seq_data, -1))
Google Kubernetes Engine、Google BigQuery、Google Compute Engine、Google Cloud SQL、Google Cloud Storage、Google Cloud Functions、Google Stackdriver など
オンライン ストア作成サービス『STORES.jp』などで知られる株式会社ブラケット(現:ストアーズ・ドット・ジェーピー株式会社)の創業者、光本 勇介氏が 2017 年 2 月に創業したスタートアップ。『見たことのないサービスで新しい市場をつくる』をテーマに、現在は、即時買い取りサービス『CASH』(2017 年 6 月リリース)、あと払い専門の旅行代理店サービス『TRAVEL Now』(2018 年 6 月リリース)を提供中。現在の従業員数は約 60 名(2019 年 1 月時点)。
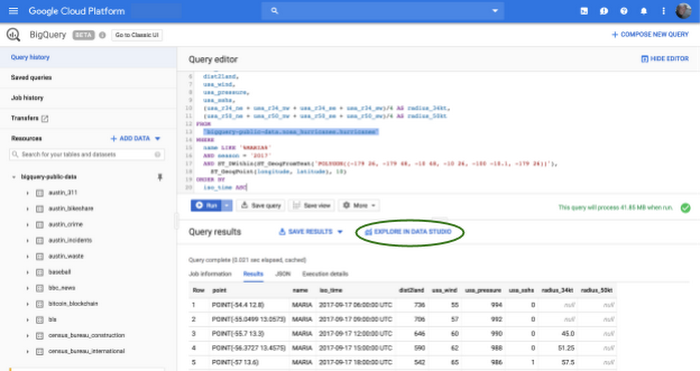
「Google は、NOAA のデータを GCP の BigQuery などのツールと統合することで、科学データ フォーマットの理解や分析データの準備に関連する多くの障害を効果的に解消し、一般のユーザーによる NOAA データの利用拡大に貢献しています。Google サービスを一定の制限付きで手軽に、そして無料で利用できるサブスクリプションの導入も、データ分析の敷居を下げています。」― NOAA の最高データ責任者、Ed Kearns 氏
「BigQuery サンドボックスのおかげで、数千の Firebase プロジェクトでアプリケーションの使用状況の把握や、クラッシュが発生したコンテキストの分析、リリース候補の評価が的確にできるようになっています。こうしたことが有意義な判断につながっています。」― Firebase のテクニカル リード マネージャー、Eugene Girard
名 称:第 7 回 Google Cloud INSIDE Games & Apps 会 期:2019 年 4 月 18 日 (木) 15 : 00 - 18 : 45 会 場:ベルサール渋谷ファースト 〒150-0011 東京都渋谷区東1-2-20 住友不動産渋谷ファーストタワー 主 催: グーグル・クラウド・ジャパン合同会社 定 員:700 名 参加費 : 無料 (事前登録制) スピーカー: 株式会社グレンジ 株式会社セガゲームス グーグル合同会社 グーグル・クラウド・ジャパン合同会社 他 調整中 プログラム: 14 : 30 受付開始 15 : 00 - 18 : 45 講演およびパネルディスカッション 詳細・参加申し込み https://goo.gl/XX21Je 上記リンクからお申し込みください。 ※ 競合他社様、パートナー企業様からのお申し込みはお断りさせていただくことがございます。 ※ 報道関係者のご参加はお断りさせていただきます。 ※ ビジネス向けのイベントとなっております。学生の方のご参加はご遠慮ください。 ※ お申し込み多数の場合は抽選を行います。参加いただける方には、後日、ご登録されたメールアドレスに参加のご案内をお送りします。
https://goo.gl/XX21Je