ここ最近、ニューラルネットやディープラーニングという単語を目にする機会が増えました。でも、いざ教科書を開いてニューラルネットについて勉強しはじめると、難しい数式がたくさん出てきてなんだかよく分からないなあ……と感じた方もいるでしょう。私がそうでした :)
そうした私のような方にぴったりな、難しい数学を知らなくてもニューラルネットワークの動作の原理を直感的に理解できる、すばらしいツールがあります。TensorFlow Playgroundです。これは、実際のニューラルネットワークをWebブラウザ上で動かしながら遊べる、JavaScriptで記述されたWebアプリです。ボタンクリックやパラメータを調節しながら簡単に自分のニューラルネットワークを設計して動作させることができます。
この記事では、TensorFlow Playgroundを使いながらニューラルネットワークの基本的な考え方を学ぶ方法を紹介します。その実際の動きを目にすれば、ここ数年ニューラルネットワークがなぜこれほどまでに注目を集めているかが直感的に理解できるはずです。
問題を人間が解くか、コンピュータに解かせるか
コンピュータをプログラミングするには、通常は人間のプログラマーが必要です。プログラマーは、個々の問題をどのようなやり方で解くかをたくさんの行数のプログラムに書き下し、コンピュータに教えます。
一方、機械学習やニューラルネットワークでは、そうした問題の一部分をコンピュータ自身に解かせることができます。ニューラルネットワークとは、ひとことで言えば、数学やプログラミング言語における関数に相当します。入力データを入れると、出力データが出てくる関数です。そのユニークな点は、どのような入力に対してどのような出力を出すべきか、学習データに基づいて学習が可能な関数であるという点です。
ニューラルネットワークは学習データをもとにふるまいを学習できる関数
例えば、ネコの画像を認識できるニューラルネットワークをつくるには、たくさんのネコ画像を使って学習させます。すると、ネコ画像を入力すると「cat」というラベルを返す関数ができあがります。もっと実用的な例を挙げれば、ゲームサーバー上のたくさんのユーザー行動ログを入力すると、その中からコンバージョン率の高いユーザーを出力する、といったふうに学習させることも可能でしょう。
では、ニューラルネットワークはどのようにしてこうした処理を実現しているのでしょうか。ここでは、以下のようなデータセットを例にとり、簡単な分類の問題を考えてみます。個々のデータポイントはx1(横軸)とx2(縦軸)の2つの値を持ちます。各データポイントは、オレンジとブルーの2つのグループに分かれています。
ここで、新しいデータポイントが渡されたとき、それがオレンジとブルーのどちらに属するか、あなただったらどのようなコードを書いて判定しますか? おそらくは、以下のように両者の間に直線を引いて、個々のデータポイントがどちらに属するかを適当なしきい値で判定するのではないでしょうか。
つまりは、IF文を書いて、その条件として以下の様な式を使います。
ここで、しきい値となるbの値を上げ下げすることで、直線の位置をオレンジ側とブルー側のどちらに寄せるか調節できます。
さらに、重み(weight)としてw1とw2をそれぞれx1とx2の係数として追加すると、コードを再利用しやすくなります。
これにより、w1とw2の値を変えるだけで、直線の角度を自由に変えられます。つまり、これら3つの値を調節することで、「データを直線で区切って二種類に分類する問題」はすべてこの条件式だけで対応できます。
ただ問題は、これらのパラメータ( w1、w2およびb)として最適な値を、プログラマーが試行錯誤して見つけなければならない点です。
ニューロンの役割:データを二種類に分類する
では、この問題をプログラマーではなくコンピュータに解かせるとどうなるでしょうか。このリンクをクリックしてPlaygroundを開き、左上の再生ボタンをクリックしてみてください。オレンジとブルーの間の直線がゆっくりと動くのが見えたはずです。つづいてリセットボタンをクリックし、もう一度再生ボタンをクリックすると、今度は異なる初期値から直線が動くのが分かります。このようにコンピュータは、オレンジとブルーのデータをきちんと分類するためにはどのような組み合わせの重みとしきい値が最適なのかを見つけようとします。
TensorFlow Playgroundで簡単な分類問題を解く
ここでTensorFlow Playgroundは、1個の人工ニューロンを用いてこの分類を行っています。では、人工ニューロンとは何でしょうか? 人工ニューロンのアイディアは、人間の脳を構成するニューロンの動きをヒントに生まれました。
脳のニューロンの詳しい動作メカニズムについては、Wikipediaのページをご覧ください。かいつまむと、個々のニューロンは、ネットワークにより結ばれた他のニューロンからの電気信号を受けて興奮(活性化)します。ニューロンとニューロンは、それぞれ異なる強さで結ばれています。ひとつのニューロンがあるとき、その周りの特定のニューロンからの信号は強く伝わる一方で、他のニューロンからはあまり伝わらない、もしくは逆に活性化を抑制する、といった違いがあります。これらのニューロンとその結びつきの数千億個もの集まりが、人間の知能の実体です。
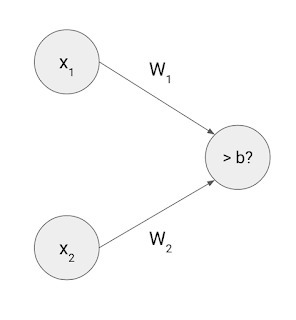
この脳のニューロンの研究結果にヒントを得て、人工ニューラルネットワークと呼ばれる新しい計算パラダイムが1940年代に生まれました。人工ニューラルネットワークでは、ごく簡単な四則演算を用いて脳のニューロンの動きをものまねします。例えば、以下のような1個のニューロンからなる簡単なニューラルネットワーク(パーセプトロンとも呼ばれます)を使えば、先ほどの簡単な分類の問題を解くことができます。
ここで、x1とx2はニューロンに入力される2つの値、w1とw2はニューロン同士を結ぶ強さを表します。bはバイアス(bias)と呼ばれ、入力値にもとづいてニューロンが活性化するかどうかを決めるしきい値を表します。この1個のニューロンの動きは、以下の式で計算できます。
そうです、これは先ほどの「データを直線で区切って二種類に分類する」ための式そのものです。実のところ、人工ニューロンは、基本的には重みやしきい値をもとに「個々のデータポイントを二種類に分類する」という機能しか持ちません。入力値が2つの場合は、x1とx2の二次元平面上に散らばるデータポイントを一本の直線で分類するという働きになります。入力値が3つの場合は3次元空間上のデータポイントを1枚の平面で分類します。これを一般化して、「n次元空間を超平面で分割する」と表現できます。
ニューロンはデータを二種類に分類する
ひとつのニューロンで画像認識
それで結局、この「超平面」なるものは、日々の問題解決にどう役立つのでしょうか? 例として、以下のような手書き数字の画像がたくさんあるとします。
手書き数字の画像
一個のニューロンを学習させると、例えば、これらの画像を「数字の8」か「それ以外」かに分類できます。
その手順を説明しましょう。まずは、学習用のサンプル画像を数万枚集める必要があります。28 x 28ピクセルのモノクロ画像を用いるとすると、28 x 28 = 784個の数字で1枚の画像を表せます。それが5万5千枚あれば、学習用のサンプルデータは784 x 55,000個のデータの集まりとなります。
この5万5千枚のサンプル画像それぞれについて、784個の数字を1つのニューロンに入力し、合わせてそれが「8」かどうかを教えるラベルも渡します。
すると、Playgroundのデモで見たように、コンピュータは個々の画像が「8」かどうかを分類できるような最適な重みとバイアスの組み合わせを見つけようとします。
5万5千枚のサンプル画像を使って学習を終えると、このニューロンの重みには以下のような値が入ります。ここで、青色はプラスの値を表し、赤色はマイナスの値を表します。
これだけです。このごく単純な一個のニューロンだけでも、手書き数字を90%の認識率で分類できます。もし0から9までの数字を認識したければ、それぞれに対応する10個のニューロンを並べるだけです。
やはりここでも、このニューロンは個々のデータポイントを「8」かどうかの二種類に分類しているだけです。では、ここで言う「データポイント」とは何でしょう? この例では、個々の画像を28 x 28 = 784個の数字で表しました。これを数学的にかっこよく言うと、個々の画像は「784次元空間上のひとつの点」を表します。つまりこのニューロンは、784次元空間を一枚の超平面ですぱっと二つに区切り、個々のデータポイント(画像)が「8」かどうかを分類しています(ちなみに、784次元空間だの超平面だのがどんな形に見えるのか、頭のなかで想像するのはムリなのであきらめましょう)。
この例では、手書き文字画像をサンプルデータとして使いました。でもニューラルネットワークは、どのようなデータの分類に用いても構いません。ゲームプレイヤーのアクティビティログを入力して不正プレイヤーを検知したり、コマースサイトのWebサーバのアクセスログとDBサーバの購入履歴をもとにプレミアユーザーを識別したり。数字に変換できるデータならなんでも「n次元空間におけるデータポイント」で表してみて、それをニューロンに入力して「超平面」を学習させ、うまく分類できるか試すことができます。
ニューラルネットワークの学習のしくみ
このように、ニューラルネットワークの基本部分は簡単な算数で実現されており、あまり難しいものではありません。従来のプログラミングとニューラルネットワークの大きな違いは、学習データにもとづいてパラメータ(重みとバイアス)をコンピュータに決めさせるという点です。つまり、学習で得られる重みのパターンは、人間がプログラムしたものではないのです。
この記事では、バックプロパゲーションや勾配降下法のようなニューラルネットワークの学習に用いられるアルゴリズムについて詳しくは触れません。ごく簡単に言うと、コンピュータは個々のパラメータの値をちょっとだけずらしてみて、その結果学習データに照らしてどの程度だけ間違いが減るか、もしくは増えるかを確認します。これを何度も繰り返すことで、最適なパラメータの組み合わせを見つけようとします。
これはちょうど、学生や新入社員を育てるようなものです。学習の初期の段階では、コンピュータはたくさん間違えます。そして十分な時間をかけて、まだ経験したことのないことも含めて、現実の問題を解決して間違いを最小化できる落とし所を探そうとします。これを汎化(generalization)と呼びます。
ニューラルネットワークが間違えなくなるまでの学習には時間がかかる
この話題については、今後の記事で解説したいと思います。とりあえずは、ニューラルネットワークの学習はTensorFlowのようなライブラリにお任せできるので、自分であまり考えたり実装したりする必要はない、という点だけ押さえておいてください。
中間層のニューロンで「いい感じ」を学習
ここまでの例で、ひとつのニューロンを使うと簡単な分類ができることを示しました。一方で、このニューロンをたくさん組み合わせると、なぜ数千もの画像を分類できたり囲碁のチャンピオンと互角に戦えたりするのか、いまいちピンとこない方も多いでしょう。ニューラルネットワークがさらに賢くなれるのには、もうひとつの理由があります。TensorFlow Playgroundのデータセットから、別の例を見てみましょう。
このデータセットに含まれる二つのグループは、一本の直線で区切れないので、一個のニューロンで分類することはできません。これは非線形分類問題(nonlinear classification problem)と呼ばれます。現実世界でも、そう単純にすぱっと白黒つけられない複雑な問題はたくさんありますよね。「青いデータの周りをなんとなく囲んでるのがオレンジのデータだから、いい感じに分けといて」、ってコンピュータにひとことで頼めたらよいのですが。では、そうした「いい感じ」をニューラルネットワークに学習させるにはどうすればよいでしょうか。
その答えは、中間層(hidden layer)の追加です。このリンクをクリックして試してみてください。
TensorFlow Playgroundで非線形分離問題を解く(ここをクリックして試せます)
ここでは何が起きているのでしょうか? 中間層にあるいずれかのニューロンをクリックすれば、それらが以下のような単純な直線による分類しかしていないことを確認できます。
これらは、データの特徴(feature)と呼ばれます。各ニューロンからの出力は、個々の特徴量の大きさを表します。この3つの特徴量を三次元空間上の1つのデータポイントと考えると、最後のニューロンはその空間を一枚の平面で分割し、個々のデータポイントをオレンジかブルーかで分類する働きをします。このように、データの特徴量を軸に持つ空間を特徴空間(feature space)と呼びます。つまり中間層は「もとのデータを特徴空間上のデータポイントに変換し、超平面で分類しやすくする」という役目を担います。
中間層は入力値を特徴空間にあてはめ、超平面で分類しやすくする
Playgroundデモの例では、この変換によって、3つの特徴量から三角形のパターンを抽出してます。「+」ボタンをクリックして中間層のニューロン数を増やすと、学習データに対してぴったりフィットする多角形を構成できることが分かります。
先ほどの新入社員の例に例えると、この変換は、熟練した先輩社員が日々の業務を通じてつかんだコツと同じようなものです。配属されたばかりの新入社員は、たくさんのメールや電話、上司や顧客からの依頼に振り回されて、なかなか要領よく仕事を進めることができません。一方、手慣れた先輩社員は、それらの情報から重要なシグナルを見つけ、いくつかのコツにしたがって日々の業務をそつなくこなします。
ニューラルネットワークも、これと同じように動きます。ある問題をいい感じに解決する上でもっとも重要なデータの特徴は何かを見つけようとします。この性質によって、用途によってはかなり複雑な問題であっても解けるほどの能力を獲得できます。
ニューラルネットワークはデータに隠された問題解決のコツをつかむ
層を深くしてニューラルネットワークを「賢く」する
ニューラルネットワークでは、より多くのニューロンを中間層に置くことで、より多くの特徴を識別できます。そして、より多くの中間層を重ねることで、データの中からさらに複雑な構造を抽出し、「賢さ」を増すことができます。その威力を次の例で紹介しましょう。
このデータセットをオレンジとブルーに分類するには、どのようなコードを書けばよいでしょうか? たくさんのIF文を並べて、個々のデータポイントがどの場所にあるかをチェックするたくさんの条件式としきい値を書きますか? 私だったらそんな面倒な作業は避けたいです。
こうした問題の解決では、人間によるプログラミングよりもコンピューターによる機械学習やニューラルネットワークの方が優秀です。このリンクをクリックして、コンピュータがこの問題をどのように解くか実際に見てみましょう(学習が終わるまでには1〜2分かかります)。
TensorFlow Playgroundで二重らせん問題を解く(このリンクをクリックして試せます)
これ、なんだかぞくっとしませんか? この例では、ディープニューラルネットワークが認識の階層構造を築こうとしているのが分かります。左端の中間層のニューロンはあいかわらず単純な直線による分類しかしていませんが、2番目、3番目の中間層のニューロンはそれらの結果を組み合わせてより複雑な特徴量を抽出し、最終的には二重らせんのパターンを識別しています。
つまり、より多くのニューロン+より多くの中間層=より抽象度の高い認識、が可能になります。この階層構造を作り上げる能力によって、単純なニューロンの集まりが、ネコの品種まで当てられる高度な画像認識やプロ顔負けの囲碁の一手を可能とする「賢さ」を得るカギとなるわけです。
Googleが公開した画像認識用のディープニューラルネットワーク「Inception」
ディープニューラルネットワークの可視化の研究事例のいくつかでは、画像の中の単純な模様から、物体の部分や全体、種類に至るまで、認識機能の階層構造が学習によって形成される例が紹介されています。
ディープニューラルネットワークの可視化の例
ニューラルネットの課題:計算パワー
この記事では、TensorFlow Playgroundのデモをいくつか紹介しながら、ニューラルネットワークの仕組みと能力について解説しました。ここで見たとおり、ニューラルネットワークの基本はとても単純で、個々のニューロンがデータを二種類に分類するだけです。しかしそのニューロンが多数集まり、深い階層構造を作ることで、学習データに隠された本質的な特徴や複雑なパターンを認識できます。
では、なぜこの強力な技術を使っている人がまだ少ないのでしょうか? そこには大きな課題があります。ディープニューラルネットワークの学習には膨大な計算パワーを消費すること。強力なGPU搭載サーバーを用いても、数百万枚の画像を用いた学習には数日や数週間の時間を要します。
また、いろいろなネットワーク設計やアルゴリズム、パラメータをトライアンドエラーで試してみて、最良の組み合わせを探しだす必要もあります。そこでディープラーニングの研究者の中には、数10台ものGPUサーバーや、さらにはスーパーコンピュータまで使って、大規模なニューラルネットワークの分散学習を進めている方もいます。
しかしとても近い将来、Google Cloud Machine Learningのような、クラウド上のたくさんのCPUやGPUによる分散学習をTensorFlowベースのフルマネージドサービスとして低いコストで手軽に行える環境が提供される見込みです。これにより、大規模なディープニューラルネットワークのパワーをより多くの方が使いこなせる日が来ると期待されます。
謝辞
この記事のレビューを快く引き受け、とても価値のあるコメントをいただいたDavid Haと中井悦司さん、Alexandra Barretに感謝します。また、本当にすばらしいデモであるTensorFlow Playgroundの作者、Daniel Smilkov、Shan Carter、およびD. Sculleyに賛辞を贈ります。





























この記事を読みニューラルネットワークに興味を持ち勉強を始めました。
返信削除ニューラルネットワークを目で見て直感的に理解できるのは素晴らしいですね。
半年以上も前の記事なのでコメントを読まれているか分かりませんが、お聞きしたいことがあります。
TensorFlow Playgroundの入力層のFeatureについて勉強をしているのですが、なぜ生の入力値(座標x,y)ではなく、Featureを間にかませているかその背景を教えていただきたいです。
というのも、MNISTのチュートリアル等では縦横28x28ピクセルの784個のアドレスのグレースケールの値を入力とし、入力層に784個のニューロンを並べている解説が
多く、TensorFlow Playgroundで行われているようなFeatureの選択がどこから出てきたものなのか分からないのです。
ちょっと宣伝のようになってしまいますが、自分の学習成果の棚卸のためTensorFlow Playgroundの設定項目の意味について解説するWebサイトを作ってみました。
http://learntensorflowplayground.net
佐藤様の例えや言い回しを一部参考にさせていただきました。誤った内容をもし見つけられましたらご指摘いただけると幸いです。