Google Cloud Platform Japan Blog
最新情報や使い方、チュートリアル、国内外の事例やイベントについてお伝えします。
うるう秒がやって来る!〜 6 月 30 日の ” 1 秒”に備えよう〜
2015年5月26日火曜日
* この投稿は、米国時間 5 月 21 日、Site Reliability Engineers の
Noah Maxwell & Michael Rothwell によって投稿されたもの
の抄訳です。
1 秒だって暇はないというあなた。もうすぐ手に入ります。UTC で 2015 年 6 月 30 日の 23 時 59 分 60 秒ちょうどに、世界は 26 回目の
うるう秒
を迎えます。Google にとっては、今回のうるう秒は 3 回目です。
Google Compute Engine
をお使いの方は、うるう秒がどのような影響を及ぼすのかを知っておく必要があります。
うるう秒って何 ?
うるう秒は非常に小さなうるう年のようなものです。一般に、地球の回転は時間とともに遅くなり、1 日が長くなります。うるう年では 2 月に 1 日を追加して暦年を遅らせ太陽年に合わせますが、同様にうるう秒も、ときどき 1 秒を追加して協定世界時を太陽時に合わせます。ちなみに、UNIX 時間のうるう秒は 1 日の最後の秒を繰り返すという形で実現します。
うるう秒はどうやって発生するの ?
一般に、うるう秒は 6 月の末か 12 月の末に発生します。しかし、うるう年とは異なり、うるう秒は一定間隔で発生するわけではありません。地球の回転速度は天候や地質学的な条件によって不規則に変化します。
たとえば
2011 年の日本の地震により、地球の回転速度が上がって 1 日は 1.8 マイクロ秒短くなっています。
Google はうるう秒にどう対処するの ?
2011 年 9 月の
ブログ
にもあるとおり、Google は巧妙な方法でうるう秒を処理します。1 秒を反復するのではなく、余分な 1 秒をわかりにくくして消してしまいます。うるう秒を中心として 20 時間のぼかし期間を設け、すべてのサーバーのシステム クロックを少しだけ遅らせるのです(おおよそ 100 万分の 14 ずつ)。ぼかし期間が終わると、ちょうど 1 秒分が追加され、常用時と同期した状態に戻ります(この方法は、2011 年のブログに記載したうるう秒処理よりも少し単純ですが、結果は同じです。時間の不連続は発生しません)。20 時間後には、うるう秒が完全に加えられ、ぼかしの入らない時間と同期するのです。
なぜうるう秒をぼかすの ?
イベントを順序正しく並べていくことが必要なシステムは、秒が繰り返されると問題を起こすことがあります。この問題は、マルチノード分散システムでは特に悪化します。1 秒が 2 秒になると、複数のノード間における同期のずれが劇的に拡大してしまうのです。本来なら、片方のイベントがもう片方のイベントよりも先なのに、両方のイベントが同じタイムスタンプでデータベースに書き込まれたらどうなるか、想像してみてください(悪くすると、後のほうのイベントが早いタイムスタンプで書かれることもあります)。では、後で本当の順序を知るにはどうすればよいでしょうか。ほとんどのソフトウェアは、明示的にうるう秒を処理するようには書かれていません(Google の多くのソフトウェアもそうです)。Google は 2005 年のうるう秒のときに、社内システムでこの種のさまざまな問題が起きることに気づきました。そして、時間を参照するすべてのソフトウェアをうるう秒対応に書き換えるのを避けるため、一度にまとめて 1 秒を加えるのではなく、約 1 日をかけてうるう秒のごく一部ずつをサーバーのクロックに追加し、うるう秒が見えなくなるようにしたのです。
Google Cloud Platform のどのサービスが影響を受けるの ?
Google Compute Engine 上で実行される仮想マシンだけはマニュアルで時間を同期できるため、時間のぼかしの影響を受けます。Google Cloud Platform のその他のサービスについては、Google が適切な処置を施すので影響はありません。
どのような影響を受けるの ?
Google のすべての Compute Engine サービスは、ぼかしの入った時刻を自動的に受け取るため、デフォルトの NTP サービス( metadata.google.internal )かシステム クロックを使っていれば自動的に必要な操作が行われます(デフォルト NTP サービスは
Leap Indicator
ビットをセットしていないことに注意してください)。しかし、外部のタイム サービスを使っていると、まる 1 秒分のステップか、複数の小さなステップが加わります。Google では外部の NTP サービスがうるう秒をどのように処理するかはわからないので、時刻の同期がどのように行われるかを予測することはできません。Compute Engine 仮想マシンで外部 NTP サービスを使っている場合は、それらのタイム ソースがうるう秒をどのように処理し、それがあなたのアプリケーションやサービスにどのような影響を与えるかを理解することが必要です。可能なら、うるう秒の時期だけでも、Compute Engine で外部の NTP ソースを使うのは避けたほうが賢明です。
うるう秒の時期に最悪とも言えるシステム構成は、ぼかし NTP サーバーと非ぼかしNTP サーバー(あるいは、ぼかし方の異なるサーバー)を混ぜて使うことです。どのような動作になるかはわかりませんが、おそらく困ったことになるでしょう。
Google Compute Engine と、うるう秒をぼかさない他のプロバイダーの両方を使用するのであれば、うるう秒の前後に時間の食い違いを起こす可能性があることを認識しておいてください。
Google の NTP サービスはどうなっているの ?
Google Compute Engine で実行されている仮想マシンから使用できる NTP サービスには metadata.google.internal があります。また、単純にシステム クロックを使う方法もあります。システム クロックはうるう秒のぼかし処理と自動的に同期します。Google はうるう秒をぼかし処理する外部 NTP サービスを提供していません。
Compute Engine インスタンスでの NTP の設定方法に関するドキュメントは、
ここ
にあります。困ったときは
Help & Support Center
にお越しください。
-Posted by Noah Maxwell & Michael Rothwell, Site Reliability Engineers
Google Cloud Launcher に 25 の新ソリューションを追加、Cloud Monitoring も統合
2015年5月22日金曜日
* この投稿は、米国時間 5 月 21 日、Group Product Manager の
Ophir Kra-Oz によって投稿
されたものの抄訳です。
去る 3 月、Google は
Google Cloud Launcher
の利用開始を
発表
しました。Bitnami か Google Click to Deploy で設定された、人気の高い 120 種類以上のオープンソース アプリケーション パッケージを起動できるようにしたのです。それ以来、Google には多くのお客様からソリューション追加のリクエストが届きました。そうしたリクエストに Google はお応えします。
3 月の発表からまだ 3 か月も経っていませんが、Cloud Launcher に 25 種類の新しいソリューションを追加しました。新たに追加されるのは、
Chef
、
Crate
、
OpenCart
、
Sharelock
、
Codiad
、
SimpleInvoices
などです。ソリューションは今後も随時追加していきます。
同時に、
14 種類の新 OS
を Cloud Launcher に追加します。この中には、
Windows
、
Ubuntu
、
Redhat
、
SUSE
、
Debian
、
CentOS
が含まれます。作業をすばやくシンプルなものにするため、初期作成フローも単純化しました。
図 1 - アップデートされた Cloud Launcher の OS セクション
Cloud Launcher のソリューション インターフェースも新しくなりました。ソリューションを比較しやすくするため、価格、サポート( OS のみ)、無料体験の詳細情報が追加されています。
図 2 - アップデートされた Cloud Launcher のソリューション詳細インターフェース
すぐにデプロイできる完全なソリューションを提供するという Google のビジョンに則り、50種のソリューションについては
Google Cloud Monitoring
を統合することとしました。
MySQL
、
Apache
、
Cassandra
、
Tomcat
、
PostgreSQL
、
Redis
といったコンポーネントにはレポートが組み込まれ、DevOps にアプリケーションの統合ビューを提供します。
図 3 - Apache Web Server のための Google Cloud Monitoring Dashboard
今から
Cloud Launcher
を始めても、Google Cloud Platform 上で使いたいアプリケーション パッケージをものの数分で起動できます。そしてぜひ、Cloud Launcher 内のリンクからご意見をお寄せください。
メーリングリスト
にも参加して、アップデート情報を受け取り、議論に参加してください。快適なシステム構築を!
ビッグデータを低コストで超高速転送
2015年5月21日木曜日
* この投稿は、米国時間 5 月 12 日、 Software Engineer の
Stanley Feng によって投稿
されたものの抄訳です。
どんなアプリケーションでも、少なくとも何らかのデータがなければ動きません。ゲーム分析、気象予報モデリング、ビデオ レンダリング、Apache Flume や MapReduce などのツール、データベースのレプリケーションといったビッグデータ アプリケーションは、言うまでもなく大量のデータを処理、転送します。一見単純なウェブサイトでも、辞書、記事、画像、その他あらゆるタイプのデータを VM 間でコピーしなければならないことがあります。そして、そのようなデータでも、蓄積されればかなりのサイズになるかもしれません。しかも、データにはファイル システムを介してアクセスしなければならないことがあります。すると、scp のような旧来のツールでは、増えていくデータ サイズに対応しきれなくなる恐れがあります。
一般に、ビッグデータ アプリケーションはディスクからデータを読み出し、それを変換してから scp などのツールでデータを他の VM に転送して、さらなる処理を行います。scp は、スレッディング モデルから VM CPU の暗号化ハードウェアに至るさまざまな面で制限を抱えており、最終的には VM 当たりの仮想ディスク読み書きクォータによって制限されます。scp の転送速度は 128 MB / 秒(シングルストリーム)か 240 MB / 秒(マルチストリーム)ほどです。
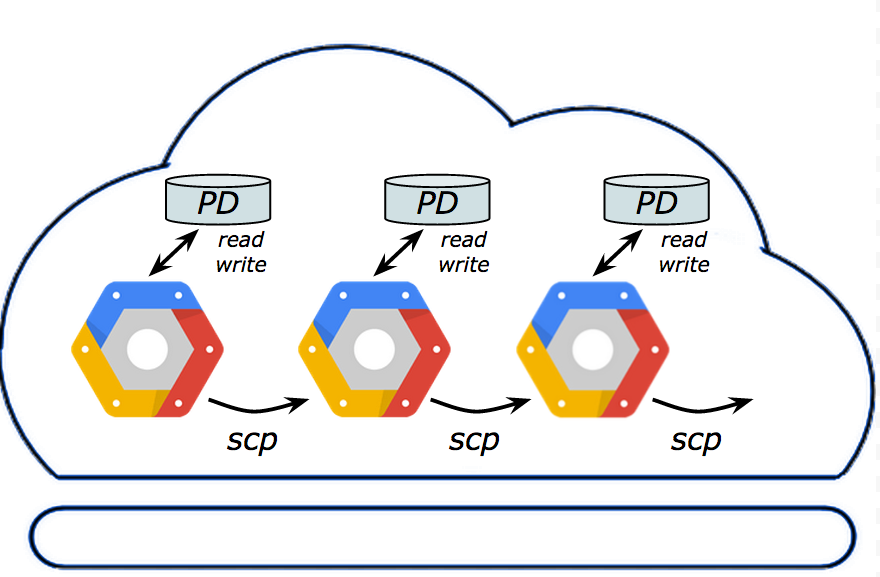
現在のフローを図示すると、次のようになります。
一般的なデータ パイプラインのシナリオ
ここでは、VM 間で大量のデータを転送するためのまったく新しい方法を紹介します。Google Compute Engine
Persistent Disks
は、ディスク上のすべてのデータのポイント イン タイムコピーを作る
Snapshots
という機能を持っています。この機能は一般にバックアップのために使われますが、すぐに新しいディスクに変換することもできます。このようにして作った新ディスクは、作成元とは異なる実行中の VM にアタッチ(接続)できます。こうすると、第 1 の VM から第 2 のVM にデータを転送できるわけです。スナップショット機能を使ったデータ転送は、次に示す 3 つの単純な手順で実行できます。
ソース ディスクからスナップショットを作ります。
新しいデスティネーション ディスクにスナップショットをダウンロードします。
新しい VM にデスティネーション ディスクをアタッチ、マウントします。
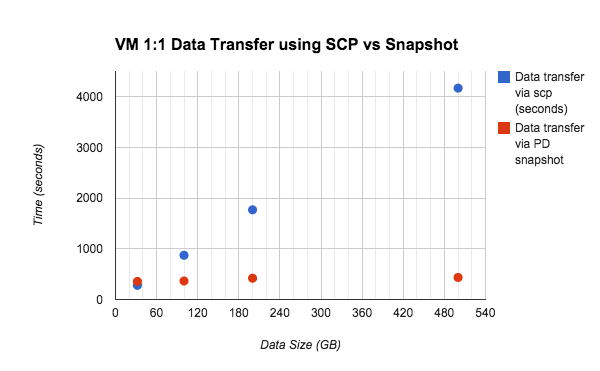
Persistent Disk Snapshot を使えば、1024 MB / 秒( 8 Gbps )以上のスピードで、VM 間でデータを転送できます。これは、scp の 8 倍のスピードです。次のグラフは、scp と Persistent Disk Snapshot を使ったときのデータ転送速度を比較したものです。
scp と PD Snapshot のデータ転送速度比較
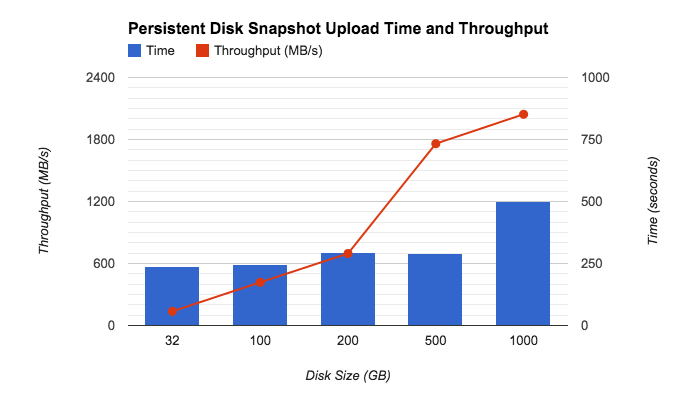
スナップショット機能を使ったデータ転送でとてつもなく大きなメリットが得られるのは、Persistent Disk Snapshot のパフォーマンスが非常に高いからです。次のグラフは、永続ディスクのスナップショットを取得するのに要する時間と実効スループットを示しています(この実験では PD-SSD が使用されています)。スナップショットを取得するのに要する時間(青い棒グラフ)は、サイズが 500 GB まではほぼ同じで、1 TB になると少し長くなっています。そのため、スナップショット プロセスの実効スループット(スピード)は、ほぼ線形に増えていきます(赤の折れ線グラフ)。
Google Compute Engine Persistent Disk Snapshot のスピードは、業界内でも突出しています。 次のグラフは、スナップショット機能を提供している他のクラウド プロバイダーとの間でアップロード時間を比較したものです。ご覧のように、Google Compute Engine のアップロード時間はサイズが大きくなってもほとんど変わりませんが、競合他社の場合のアップロード時間はサイズの増加とともに顕著に上がっていきます。
Google Compute Engine のテストは、PD-SSD を使用して us-centra1-f で実行。スナップショット サイズは、32 GB、100 GB、200 GB、500 GB、1000 GB
Persistent Disk の
価格
は 1 か月当たり 2.6 セント / GB です。 VM の利用料金以外に、これだけのコストがデータ コピーのためにかかるのは高いと思われるかもしれません。しかし、転送目的で使われるスナップショットは短命( 10 分未満)で、価格は秒単位で比例案分されるので、
実際の平均コストは 500 GB のデータの転送ごとに 0.003 ドルほど
です。スナップショットは転送が完了したら直ちに削除できます。そのため、
1 セント未満の料金で、かつ従来のツールの 8 倍のスピードで 1 TB のデータを転送できる
ことになります。
実際に試してみたい方は、
ドキュメント
にスナップショット コマンドの詳しい説明があります。また、Persistent Disk Snapshot の安全な使い方については、
以前のブログ
を参照してください。快適なスナップショット ライフを!
-Posted by Stanley Feng, Software Engineer, Cloud Performance Team
Google Cloud Platform の価格を引き下げ
2015年5月19日火曜日
* この投稿は、米国時間 5 月 18 日、Technical Infrastructure の Senior Vice President、
Urs Hölzle によって投稿
されたものの抄訳です。
クラウド サービスのプロバイダーには多くの選択肢があります。しかし、アプリケーションやワークロードに最適なクラウド サービスの選択は、意外と難しいのではないでしょうか。
Avaya
や
Snapchat
、
Ocado
、
Wix
などのお客様には、Google のイノベーションと実証済みのパフォーマンスに加えて、柔軟な価格モデルを備えた Google Cloud Platform を選択いただきました。最近では、低価格で高速なコールド データサービスの
Google Cloud Storage Nearline
や NoSQL データベースの
Google Cloud Bigtable
などの新しいサービスをご紹介しましたが、本日発表の価格改訂は、Google Cloud Platform の魅力をさらに引き上げることができると考えています。
本日、すべての Google Compute Engine インスタンスタイプの価格を引き下げるだけでなく、短期的でステートレスな計算能力を提供する、新しいクラスのプリエンプティブル VM を、非常に低価格かつ固定料金制のプランでご案内できることを発表しました。
自動割引
、
分単位の課金
、マシンタイプ変更へのペナルティがないこと、長期的コミットメントが必要ないことなどと相まって、私たちが価格やパフォーマンスで業界をリードしている理由がおわかりいただけると思います。
プライス ダウン
昨年、Google Cloud Platform の価格は
ムーアの法則
に従うことをお約束しました。そして本日、その約束を果たすべく、仮想マシンの価格を最大 30 %まで引き下げます。
設定
価格引き下げ率(米国)
Standard
High Memory
High CPU
Small
Micro
20%
15%
5%
15%
30%
欧州とアジアでも、同様に価格を引き下げます。Google Cloud Platform の価格に関する詳細は、Compute の価格に関する詳細は、
Compute Engine 価格ページ
をご覧ください。
上図のように、Google Compute Engine の価格は、2013 年 11 月の発売以来、下がり続けています。
Google Compute Engine プリエンプティブル VM の特徴
もしワークロードが柔軟なら、
新しいプリエンプティブル VM
は短期間のバッチ ジョブをレギュラー VM よりも 70 %安価に実行できます。プリエンプティブル VM はレギュラー VM とそっくりですが、可用性がシステムの供給と需要に影響されることが異なります。プリエンプティブル VM は、アイドル状態となるはずのリソースを活用して実行されるため、実質的なコスト削減をもたらします。
Descartes Labs
などのお客様は、Hadoop MapReduce や 視覚的効果のレンダリング、財務分析、その他の計算処理などのワークロードにとって、プリエンプティブル VM が素晴らしいオプションになりうることをすでに理解されています。
重要なのは、プリエンプティブル VM の価格が固定されていることです。他のクラウド プロバイダーのインスタンスとは異なり、プリエンプティブル VM ではコストを正確に予測できるのです。
Regular n1-standard-1
Preemptible n1-standard-1
コスト低減率
$0.050 /時間
$0.015 /
時間
70%
プリエンプティブル VM の価格については、Google の
ドキュメントページ
を参照ください。
価格に関する詳細は、
価格ページ
をご覧ください。まずは手始めとして、ワークロードをテストできる
無料トライアル
もご用意しています。
- Posted by Urs Hölzle, Senior Vice President, Technical Infrastructure
プリエンプティブル VM 登場: 標準価格の 3 割で使える、まったく新しい VM
2015年5月19日火曜日
* この投稿は、米国時間 5 月 18 日、Senior Product Manager の
Paul Nash によって投稿
されたものの抄訳です。
多くのデベロッパーは、単にウェブサービスを利用することにとどまらず、膨大な計算能力を必要とするワークロードのためにクラウドを利用しています。クラウドなら、スケーラビリティが高く”ペイアズユーゴー”(使った分だけの課金)で高いコストパフォーマンスが得られます。クラウドで行われている処理は、ビデオエンコード、ビジュアルエフェクトのレンダリング、データ解析やシミュレーション、ゲノミクスのためのビッグデータクランチングなどです。これらのユースケースは、大量のコンピューティングリソースを消費しますが、大抵は散発的に実行されるだけなので、クラウドコンピューティングはベストマッチです。
そして今日、すべての地域のすべてのお客様を対象として、
Google Compute Engine プリエンプティブル VM
をベータリリースしました。プリエンプティブル VM は、通常のインスタンスとまったく同じですが、1 つだけとても大きな違いがあります。プリエンプティブル VM は、いつシャットダウンされるかもしれないのです。ずいぶん乱暴な話に聞こえるかもしれませんが、1 つのインスタンスを継続的に使える状態にしておく必要のない、分散的でフォールト トレラントなワークロードでは、この特徴が大きくものを言います。無期限のアップタイムの保証を捨てれば、通常のインスタンスよりも大幅に料金が安くなるのです。プリエンプティブル VM の価格は固定です。変化する市場価格のもとで賭けに出るリスクを負わずに、いつでも低コストが保証され、必要コストが予測できます。使い始めた最初の瞬間からコスト節減効果が上がります。価格は、コア時間あたりわずか 0.01 ドルです。
一部のお客様は、すでにプリエンプティブル VM でコスト削減を実現しています。
Citadel
社は、クラウドソリューションの一部としてプリエンプティブル VM を使っています。同社 CIO の Joe Squeri 氏は、次のように述べています。「これは最高の効率、イノベーション、達成だ。私たちはクラウドのリソース消費が大きいので、地域によって変わる価格体系をうまく使いこなすという複雑でわかりにくい作業をせずに、魅力的な価格で使える Google Cloud Platform のプリエンプティブル VM を歓迎している」
ディープラーニング AI の
Descartes Labs
社は衛星画像の解釈に力を入れており、最近では約 3 万の CPU を使って、わずか 16 時間で 1 ペタバイトの NASA の画像を処理するという大規模な実験を成功させています。同社 CEO で共同創設者の Mark Johnson 氏は、次のように述べています。「シード ファンドで成り立っている私たちのようなスタートアップ企業からすると、大幅なコストダウンを実現できるプリエンプティブル VM の価格モデルは画期的だ。全世界の作物の作況を確認、判定するための処理データが増えているだけに、将来もこのサービスを使い続けられるのはとてもすばらしい」
Google 自身の Chrome セキュリティチームは、数千の仮想マシンで実行されている Chrome 最新コードに対し、
Clusterfuzz
ツールを使ってノンストップの無作為なセキュリティテストを実行しています。計算能力を上げれば、セキュリティ バグを今までよりも早く見つけ早く修正できるようになります。プリエンプティブル VM の導入により、同チームはコストを半減させつつ、2 倍の規模でテストできるようになりました。
Google のデータセンターでは、さまざまな理由により予備リソースを維持していますが、プリエンプティブル VM はこの予備能力を活用します。Google のデータセンター利用率を最適化するために必要になったときには、Google が能力を回収できるようになっています。その代わり、Google はこの種の仮想マシンを大幅に値引きして提供します。ただし、プリエンプティブル VM の実行時間は 24 時間に制限され、それよりも早くプリエンプション(シャットダウン)される場合もあります。しかし、この制限を除けば、高速で簡単なプロビジョニング、一貫して高いパフォーマンス、永続ディスクに書き込まれるデータの常時暗号化など、Google Compute Engine のすべての機能が手に入ります。
プリエンプティブル VM は、今ある Google のツールを使って作ることができます。Google Developer Console で 1 つのボックスにチェックをいれるか、gcloud コマンドラインに
“
--preemptible
”
を追加するかです。プリエンプティブル VM が強制終了されるときには、
30 秒前に通知
が届くので、その時間を使ってクリーンにシャットダウンすることができます(保存も含みます)。
Hadoop on Google Compute Engine を使っているお客様には、さらに簡単な方法があります。オープンソースの
bdutil
ツールを使えば、
Connector for Hadoop
を介して Google Cloud Storage から直接データを取ってくる Hadoop クラスタを作れますが、bdutil はプリエンプティブル VM をミックスインできるようになりました。
“
--preemptible .25
”
を追加すれば、クラスタの 25 %をプリエンプティブル VM として実行することができます(割合は自由に設定できます)。
プリエンプティブル VM の詳細な使い方については
ドキュメント
を参照してください。価格体系の詳細については、
Compute Engine 価格ページ
を参照してください(価格計算機ツールとクラウドプロバイダー間の本当の価格比較の詳細も同じページにあります)。疑問、フィードバックなどがある場合には、
getting help page
をご利用ください。
プリエンプティブル VM は、Google Cloud Engine から最大限の価値を引き出すために間違いなく役立ちます。これを使ってすばらしい新アプリケーションを作られたら、是非お話をお聞かせください。
-Posted by Paul Nash, Senior Product Manager
分散 SQL データベースの Crate が Google Compute Engine で Click-to-Deploy 可能に
2015年5月18日月曜日
* この投稿は、米国時間 5 月 7 日、 ゲストの
Tyler Randles 氏によって投稿されたもの
の抄訳です。
今回のゲストは Tyler Randles 氏です。Tyler は、オープンソースの分散型 SQL データベース ソフトウェアである Crate のデベロッパー エバンジェリストです。
Crate
は、高可用性を特徴とする
シェアード ナッシング アーキテクチャ
にそって構築されたオープンソースの分散 SQL データベースです。Crate は、高可用性とフォールト トレランスを維持するために、すべてのノードに対して自動的にシャーディングと分散を実行し、レプリカをいくつか保持します。このことは、新しいノードが追加されたときにクラスタは自動的にリバランスし、一方、ノードが除去されたときに自己回復できることを意味します。すべてのデータは、インジェスチョンの際に、インデックス付け、最適化、および圧縮がなされ、RESTful API を介して、慣れ親しんだ SQL 構文 (SELECT * FROM...) を使用してアクセスできます。
Crate は、ドキュメントや BLOB を保存したりリアルタイム検索をサポートする際、デベロッパーが複数の技術を組み合わせて操作しなくても済むように作成されました。また、人手によるチューニング、シャーディング、複製、あるいは他の大規模なデータ保存の維持管理に必要な操作を不要にできるので Dev-Ops に役立ちます。ClearVoice や VoIPStudios のような企業は、
クエリのパフォーマンスを向上
させたり、
自社のテクノロジー スタックを簡略化
したりするために Crate を使用しています。
Google Compute Engine 上に構築された Crate は、2014 年末に
TechCrunch Disrupt を受賞
し、その後も Crate クラスタを Compute Engine で簡単に動かせるように取り組んでました。そして、このたび
Click-to-Deploy
ソリューションを発表し、クラスタサイズ、必要なデータ·ストレージ量、使用するマシンタイプを指定して数回クリックするだけで、Crate クラスタを立ち上げることを可能にしました。インスタンスとディスクが自動的にプロビジョニングされるので、Crate は数分でインストールされ、データをインポートする準備ができます。
1 台のマシンで処理できないデータ量だったり、回復機能を必要としたり、あるいは単に新しい分散型 SQL データベースを試してみたいのであれば、
Compute Engine
の Crate は始めるのにうってつけです。素早いスケール、クエリ時間の短縮、テクノロジー スタックの簡素化、などに役立ちます。Google Cloud Platform のアカウントを持っていれば誰でも、この新しい
Click-to-Deploy ソリューション
を使って簡単に Crate を試すことができ、セットアップ時間もわずか数分で済みます。
Crate と Google
についての最新ニュースをチェックして、
意見をお聞かせください
。
- Google Cloud Platform Japan Team
Google Cloud Debugger が Google App Engine に対応 - トラブルシューティングをもっと容易に
2015年5月15日金曜日
* この投稿は、米国時間 5 月 7 日、Product Manager の
Keith Smith によって投稿されたもの
の抄訳です。
時間が無いなかでの本番環境のバグ追跡には、
Cloud Debugger
が役に立ちます。Cloud Debugger は特別な設定が不要で、コード行を選択するだけで、その行が次に実行されたときにローカル変数とスタックトレース全体を返してくれます。これらはすべて、アプリケーションを停止させたり、他のリクエストを遅くさせたりすることなく行われます。
先月、
Google Cloud Debugger
で
Google Compute Engine
プロジェクトのトラブルシューティングをサポートするようになりましたが、今回より、
Google App Engine
でも同様にアプリケーションをデバッグすることができるようになりました。
Cloud Debugger は、デバッグがアクティブにされていない App Engine プロジェクトにオーバーヘッドを追加することはありません。また、アプリケーションの状態をキャプチャする際にレイテンシが 10ms 未満追加されるだけなので、アプリケーションへのリクエストをブロックすることもありません。
App Engine の Cloud Debugger は現在、Java ベースのプロジェクトで使用できます。他のプログラミング言語やフレームワークへのサポートもまもなく発表する予定です。いつも通り、
メールでのフィードバック
や
Stack Overflow
での相談をお待ちしてます。
-Posted by Keith Smith, Product Manager
Google Cloud Platform のグローバルイベント Next、6 月東京開催決定
2015年5月14日木曜日
2015 年 6 月 18 日(木) 東京六本木、アカデミーヒルズにおいて、Google Cloud Platform のグローバル イベント、
Next
を開催することとなりました。
Next は、Google Cloud Platform にフォーカスし、Google のテクノロジーやサービスの最新情報と活用方法、そしてトレーニングを提供するイベントです。
午前中の基調講演では、Google Cloud Platform 事業責任者が来日し Google のクラウド最新情報をご紹介します。午後からはデベロッパー向けセッションと IT 担当者向けのセッションに別れ、コンテナ技術、リアルタイム モバイル開発、データ分析や運用など様々なテーマのプレゼンテーションをお届けします。
さらに "Hands-on Lab" として、実際に Google Cloud Platform に触れ、その場で Google スタッフに質問できるブースもご用意。
デベロッパーや IT 担当者の皆様、Google のクラウド テクノロジーがどう今のサービスやツールに活かせるのかを知りたい方、ぜひご参加ください。基調講演はライブ配信も行います。
概要
【日時】6月18日(木)11:00~17:30 (10:00 受付開始)
【会場】六本木アカデミーヒルズ
東京都港区六本木6-10-1 六本木ヒルズ森タワー49F
【参加費】無料
【参加登録】
詳細、お申し込みはこちら
皆さまのご来場をお待ちしております!
AppScale と App Engine の協働で高い柔軟性を実現
2015年5月14日木曜日
* この投稿は、米国時間 5 月 5 日、 Google Cloud Platform の
Global Head of Solutions、Miles Ward によって投稿されたもの
の抄訳です。
+
Google App Engine
の開発背景には、Google が開発を行う環境と同じものを、世の中のデベロッパーが利用できるようにしたいという思いがありました。古いモデル、使いにくいソフトウェア、あるいは限られたインフラに制約されることなく、Google で生まれたイノベーションを開放しました。開発時の思いは今でも忘れず、私達の活動と目的となっています。
一方、ユーザーにとって、言語、使用する展開モデル、構築に使うツール、インフラ設計などがより柔軟になるのは大切だということも理解しています。
そこで今回、AppScale と
Google Cloud Platform
とのユニークなコラボレーションを発表します。AppScale と App Engine 間の互換性および相互運用性を促進するために、エンジニアの投資という直接的な投資を行っています。
AppScale と Google Cloud Platform で、アプリのための、より柔軟性の高いインフラが実現します。
AppScale を利用すると、App Engine アプリをどんなローカル / クラウドのインフラでも実行できるようになります。また、AppScale の設定も、自分で行ったり AppScale Systems でインフラを管理したりと、柔軟に行えます。
例えば、ある顧客はカスタム インテグレーションが必要なため自社のインフラが適していると思われる場合、それら特定の顧客に対しては要望に沿えるように AppScale を使い、それ以外の世界中の顧客には App Engine が持つ力を使ってサービスを提供することができます。
例えば、既存のデータセンターやコロケーションがある状態で、でもクラウドを想定してアプリ構築を始めたいと考えている場合、AppScale をインストールするだけで、クラウドに対応したアプリの構築が始められるのです。
App Engine の現在のバージョンは 1.9 ですが、今回は、AppScale は1.8 App Engine API のサブセットを発表しました。AppScale のエンジニアや幅広いコミュニティと共に取り組み、Versions や
Modules
を含む App Engine 1.9 との互換性を追加しています。今後の取り組みとしては、ユーザーからのフィードバックを参考にしていますが、特に
Managed VMs
を AppScale に統合し、相互運用性をさらに高めたいと考えています。
詳細について話したいことは山ほどありますので、今後少しずつ進捗をお知らせしていきますね。このブログと、AppScale
project wiki
、
AppScale Github page
、AppScale Systems ブログで最新情報をお伝えしていきます。もし今日にでも試してみたくなったら、まず
AppScale's Fast Start
を試した後
Google Compute Engine
上で AppScale を実行してください。
みなさんが Google と一緒になって Google の取り組みにワクワクしていただければ、またみなさんが新しくて素晴らしいものを次々と作り出していければ、嬉しく思います。いつものことですが、
フィードバック
もお待ちしております。どのようなご質問、アイデア、素敵なストーリーでも遠慮なくお寄せください。Thanks!
-Miles Ward, Global Head of Solutions, Google Cloud Platform
株式会社 Aiming(エイミング)の導入事例 (2): BigQuery で集計をリアルタイムに、コストを 1/5 に
2015年5月14日木曜日
* 5 月 19 日、一部内容を更新しました。
数百万のゲーム ユーザーに比例して、そこで生まれるデータの量も膨大なものとなります。それをどう活用しているのか、どう処理しているのか、気になるところですよね。
前半
では、
株式会社 Aiming
、企画・運営グループ インフラエンジニア マネージャー 野下 洋さんに、
Google Cloud Platform
の利用の仕方や、クラウド ベンダーの選定についてお聞きしました。後半では、開発グループ リードソフトウェアエンジニア 芝尾 幸一郎さんに
BigQuery
の利用方法をお聞きします。
BigQuery へ移行
芝尾さんはどういった仕事をされているのですか?
主にやっているのが、社内の横断的なデータ分析基盤を作ること。これが一段落すると分析作業をやるようになると思います。Aiming の前は、Hadoop を使ったデータ分析のシステムをやってました。
BigQuery はどのように利用されてるのですか?
社内の KPI ツールとして Monolith という、社内にサーバがある Web のツールなんですけど、社内の各タイトルの売上だとかが一覧で見れるツールがあります。そこで、BigQuery で集計した結果をグラフだとかで見れるようにしています。
BigQuery にデータをどう送っているのかというと、各ゲームのサーバーから td-agent (fluentd) を使って、ゲームによっては 1 度ログサーバーに集約するものもあるし、そのまま BigQuery に送っているものもあります。
どうして BigQuery を利用するようになったのですか?
以前の製品では、データを送って、集計のためのクエリーを製品上に保存する仕組みだったので、そこで売上集計の SQL だとかを 1 日に 1 回とか 1 時間に 1 回というタイミングで実行し、その集計結果を一旦社内の Web サーバーに貯めこんでおいて、売上とかイベント時の参加者グラフだとかを見るようになっていました。
そこで課題だったのが、以前の製品があまり速く集計を返せない、例えば売上などは前日の値になる、今の値が見たくても、何分か待って集計しないとわからない。これを BigQuery に変えたことで、社内にサーバがあることは変わらないのですが、今の値が見たいなら、集計の SQL は、その Web サーバ側で持っているので、直接 BigQuery に問い合わせにいきます。その問い合わせた結果は数秒で帰ってくるので、それをそのまま Hicharts を使ってグラフ化することで、前日じゃなくて今のデータが見れるようになりました。
移行を検討するとき BigQuery 以外にも選択肢はあったと思いますが、BigQuery を選んだ理由は?
理由はいくつかあって、まず速い。同僚は安いという点をあげていますね。1 Gで $0.020 ドル(編集注: 2015 年 4 月時点での
月毎のストレージ コスト
。ストリーミング インサートのときは、10 万行に対し $0.01)。以前の製品のときはもっとかかっていたのが、試算したら数分の 1 となって、これは本当か(笑)と。何かの冗談に違いないと。それが本当なら価格競争力がある、それで BigQuery にしようとなりました。
ゲームへの定着を測る
どういったデータを集計し、見ているのですか?
基本的にはユーザーのアクティブな行動を見てます。アクティブ ユーザー数、何日間継続して使ったか、新規登録ユーザー数だとか。その中でも重視しているのは、アクティブユーザー数から新規登録のユーザー数を引いたものです。それをよく見ていて、継続して利用するユーザーを知りたい。例えばリワードを打ったり、CM を打つと、1 万とか 2 万人が入ってくるんですけど、そのユーザーというのは次の日にはゲーム遊ばず、定着してくれないこともある。知りたいのはゲームにユーザーが定着しているか。そのためにアクティブユーザー数を取りたいというのはありますね。
ゲームにおけるデータの重要性をどう考えていますか?
今まで見えていなかったので、どんぶり勘定でやるしかなかった。例えばリワードを打つと一時的にユーザーは増えるものの減っていってしまう。それは定着していないからなんですけど、それが例えば 5 日間連続で利用したユーザーで線を引くことで、この施策が当たったかどうかわかるようになる。今まではなんとなく、増えているような感じがする、流行っているような感じがする、だったのが、実際に定着するところまで見れるようになったことは大きいと思います。
このツールは、社内の人誰でも見れるのですか?
許可を得れば見れます。会社の方針としても、みんながデータを見ることで、自分の会社のタイトル同士を比較して、リワードを打ったときの状況を予測したり、理解を深めることができますから。
芝尾さん個人として BigQuery に変更して、特に何が気に入りました?
個人的には、以前の製品は集計に数分かかって寝てしまうことがあったのが、BigQuery は数秒で終わるので試行錯誤がし易いことです。分析を主体にする人、企画運営する人、グラフが見たい人、経営者、いろいろ立場によって利点は違いますが、僕が利点だと思うのは、レスポンスが早いので分析するときにダレないこと。途中で眠くなる問題は結構大きいですからね(笑)。
以前はオンプレミスで Hadoop を使われていたそうですが、その観点で BigQuery や 以前の製品のようなクラウドのサービスとの違いをどう考えていますか?
だいぶ楽です。Hadoop でファイル システムを構築して、調子が悪くなってクラスターが落ちたから新しいクラスターを入れるとか、ノード数が大きくなれば速くなるけど、その分メンテナンスが大変になります。データセンターにハードウェア差し替えに行くだとか。結局 Hadoop を使うのは、社外にデータを出したくないというところからで、それが Hadoop を使う理由でしたから。実際に BigQuery を使うと、やっぱり社内で持つのはないなとという感じですね。こういう部分は会社としてのポリシーの柔軟さだと思います。やはり、自社で持ってるとラッキングから全部やらなければならないのが、クラウドではスケーリングを気にしなくていいのが大きいですね。
データを外に出すということで、クラウドのセキュリティについてどう考えていますか?
問題に思ったことはないですね。鍵の管理を徹底して、IP で絞れば外に漏れることもない。心理的な抵抗だとは思います。楽さには抗えないですから。
ゲームが面白かったことを数値化
今後 BigQuery をどう使っていく予定ですか?
ログレスのデータも BigQuery に入り始めたので、いろいろ分析していきたいです。当面の目標は各タイトルのデータを BigQuery に置いて横串で見れるようにすることですね。また、過去のデータを集計したものを見せるという形が残っているので、全てのタイトルのデータをリアルタイムに集計して、企画や運営の人に見せられればと思っています。まさにBigQueryを使ったリアルタイムな何かができるのではと。
データ分析を今後オンライン ゲームにどう活用していきたいですか?
面白いゲームを作ってなんぼですから、データ分析でも ”その面白さは数値として出ている” と言えるようになりたい。昔のクリック ゲームや、少し前のソーシャル ゲームはデータ分析の結果(結果が出ていることと)同じようにやれ、というのがありましたが、ユーザーの性質が変わってきて、スマートフォンでも、よりゲームらしいゲームをしたいとなってくると、データ分析は面白かったことを検証するために使われるようになると思います。
■ Google Cloud Platform のその他の
導入事例はこちら
から
シンプルで繰り返せるデプロイを。Google Cloud Deployment Manager ベータ版
2015年5月13日水曜日
* この投稿は、米国時間 5 月 5 日、 Technical Program Manager の
Chris Crall によって投稿されたもの
の抄訳です。
アプリケーションのテスト、ステージング、作成を行う環境を作りだすのは未だ困難なことです。現在では、それぞれの環境を設定するためのスクリプトを実行したり、あるいはオープンソースの構成ツールを実行するために別のサーバーをセットアップすることもあるでしょう。ツールのカスタマイズや設定をしたり、プロビジョニングのプロセスをテストしたりするには時間と労力がかかります。さらに、何かうまくいかない場合には、サーバーのデプロイメントやツールをデバッグしなければなりません。
Google Cloud Deployment Manager
(ベータ)では、ユーザーがデプロイしたい対象の記述をビルドし、それ以外の事を管理してくれます。またシンタックスは宣言型です。例えば、自動スケーリングする VM 群をプロビジョニングしたい場合は、必要な VM のインスタンス タイプを宣言して定義し、VM をグループに割り当て、オートスケーラーとロードバランサーを設定します。一連のコマンドライン インターフェースの呼び出しを使ってこれらの各項目を生成および設定したり、API を呼び出すコードを記述したりする代わりに、テンプレートにこれらのリソースを定義すれば、Deployment Manager へ 1 つのコマンドを実行するだけで、それらすべてをデプロイすることができます。
Deployment Manager の主な機能は次のとおりです。
インフラストラクチャのデプロイをテンプレートに定義し、コマンドラインまたは RESTful API を経由してデプロイする
テンプレートは jinja や Python をサポートしているので、デプロイメントが要求するロジックに、ループ、条件、パラメータ化された入力などのプログラミング構造を有効活用できる
デプロイメントの表示や削除を行う UI を
Google Developers Console
でサポート
ストレージへのコンピュートからネットワーキングまで、
Google Cloud Platform
のリソースとの緊密な統合により、デプロイメントのプロビジョニングおよび可視化を迅速に実行
デプロイメント例
Puppet、Chef、SaltStack、Ansible など既存のオープンソース構成管理システムと Deployment Manager の違いをよく尋ねられます。それぞれ構成管理のための強力なフレームワークですが、どれも Cloud Platform へネイティブに統合されません。本来の意図通りに管理できるシステムの力を最大限に発揮するためには、実行したいことを表現できて、かつそうしたハードワークを内部システムがユーザーに代わって実行してくれるような宣言型システムが必要です。
また、他の構成管理システムとは異なり、Deployment Manager は Developers Console で直接 UI をサポートするので、デプロイメントのアーキテクチャを表示させることができます。Deployment Manager は Cloud Platform でネイティブにサポートされているため、追加の構成管理ソフトウェアをデプロイまたは管理する必要がなく、またそれらを実行するにあたり要するの追加費用も不要です。
Deployment Manager
を試して Cloud Platform でのアプリケーションのデプロイをシンプルにしましょう!フィードバックは
こちら
まで。
-Posted by Chris Crall, Technical Program Manager
株式会社 Aiming(エイミング)の導入事例 (1): 安く、安定したクラウドへ。オンライン ゲームを Google Cloud Platform へ移行
2015年5月13日水曜日
今回の事例は、300 万人以上の人が遊んでいる “
剣と魔法のログレス
”、500 万ダウンロードを超えた “
ロードオブナイツ
”、成長を続けるオンラインゲーム市場、特にスマートフォンゲームの市場の中でさえもヒット作を生み出し続けている
株式会社 Aiming
さんです。
MMORPG やシュミレーション ゲームに強く、以前からオンライン ゲームを作ってきたチームが殆どで、スマートフォンにシフトしても同じように企画し、技術を使っていけていることが強みであると、企画・運営グループ インフラエンジニア マネージャー の野下 洋さんが説明してくれました。
前半はまず、野下さんに Aiming についてと、
Google Cloud Platform
の選定理由や利用方法をお聞きし、次回、開発グループ リードソフトウェアエンジニア 芝尾 幸一郎さんに
BigQuery
についてお聞きします。
ゲームをして、ゲームを作る会社
いくつか Aiming さんについて書かれた記事を読んでいると、仕事中でもゲームをするという習慣があるそうですね
ゲームをするのが偉い、という記事もありますよ(笑)。自分を含むインフラチームでもゲームしている人が多いですね。凄く面白いと思っているのが、ゲームをやっていることで、企画の人がいろんな意見を自分からも吸収していくし、みんながゲームをやっていることでいろいろな可能性が生まれる。そういう風通しの良さも含め面白い会社です。その中でも社長が負けず嫌いで、自分で率先してゲームをやりますし、取締役で、インフラチームのトップに萩原という人がいるんですが、とにかくゲームを知っていて、それだけゲームをしている。それを見ていても、もっとゲームをやらないと、となってきます。国内のゲームだけでなく海外のゲームも含めて。
その社長の椎葉さんの話は良く見聞きしますが、会社ではどういった方なんですか?
会社では、フレンドリーな人で、一緒に野球をやったり、フットサル一緒にやったり。大会に一緒に出たりもしてます。尊敬している人です。
大勢の人が遊んでいるゲームを運営されていますが、インフラチームは何人くらい?
東京に 5, 6 人、大阪に 2 人。AGS(Aiming Global Service Inc.)というフィリピンにある子会社に数十人。日本では高レベルの作業をして、週次のメンテナンスは AGS に実施してもらっていますが、まだまだ人材が不足しています。
インフラチームの仕事内容について教えてください。
多岐にわたっていますが、サービスのインフラ部分については、サーバーを構築していくことなのですが、そのとき 2 通りあって、1 つは、今後も増やしていく予定の海外のゲームの導入。このときまず、構成をチェックして、そのままでは問題がある部分が出てくるので、それを修正して構築します。もう一つは、自社で開発する国内向けのゲームを、開発メンバーと話し合ってこういう構成にしよう、こういうふうに作ろうと進めていくことが中心です。その後の運用は AGS にお願いしています。仕組みだけを作って AGS に、というのが理想ですが、そこまではまだ完全にはやれていないですね。
クラウドの採用基準
以前、別の方がされていた講演で、クラウドの採用基準は、様々な意見を集めて、ひたすらクラウド ベンダーの営業と話すという内容を聞きましたが、今はどうしているのですか?
当時は安さ、いかに安くするかを重要視してました。必要な要件をならべて、相見積とって、安くさせて、としていました。今は会社の状況や規模も変化して、コスト面だけでなく、もっと使い勝手だとか、運営までを見越した選定をしていくようにしています。難しいですけどね。
今回古いゲームを Google Cloud Platform に移行したそうですが、それはどういうきっかけから?
そのゲーム(ロードオブナイツの海外版)は、最初は一番実績のある AWS でやってみようかと EC2 を使っており、その後、とあるクラウドサービスへ移行しました。かなりコストに差があったんですよ。でも残念ながら安定性が低かった。それで Google Cloud Platform は使ったことなかったのですが、さらに安かったし、安定しているという話も聞いていたので、使おうとなりました。
それと Google Apps for Work を使っているので認証が楽ということもありました。なぜその点を重要視したかというと、今後セキュリティをさらに意識していく必要があって、認証を Google Apps と連携することで強固にできる、とっかかりとしてはそれもありましたね。
実際に移行の話があってから、どれくらいの期間で移行させたんですか?
社長から直接自分に、安いクラウドにしてほしいという話があって、一週間くらいで Google に決めて、そこから 1 ヶ月もしないうちに移行を終えてますね。2, 3 週間くらいで移行したのかな。Google Cloud Platform の事前評価というのも簡単な評価しかしていないですね。とりあえずゲームを動かすというところにフォーカスして、動けば使ってみようという感じでした。
移行というとプログラムだけじゃなくてデータの移行もあったと思います。それぞれのクラウドの違いからくる、問題はありましたか?
それはないですね。クラウドに依存する作り方はしてないので、CentOS の環境があれば動く構成になっています。ただ、これまで移行してきた中でモレがあったことはありましたけど、それはナレッジ化していたので、ほぼノーミスで今回は移行できましたね。
まだ使われて間もないですが、Google Cloud Platform を利用した感想は?
(
Compute Engine
の)インスタンスを 30 くらい立ち上げていて、以前のクラウドサービスから移行後もサービスに影響を与える問題はゼロ。多少再起動したりということはありましたけど、特に問題なく、ほぼ何の問題もなく動いてますね。
他に利用している Google Cloud Platform のサービスはありますか?
特に BigQuery を使っています。
Cloud Storage
はまだ使っていないのですが、Amazon の S3 をずっと使ってきて、転送量が高く移行しようかという話は出ています。
オンラインゲームのためのクラウド選定
今後も新しいアプリケーションをリリースしていくと思いますが、オンプレミスも含めて、今後サーバの選び方についてどういう考えを持っていますか。そしてその中での Google Cloud Platform について。
これまで検証をしてきた中で、MMORPG とシュミレーションゲームという 2 つの大きなゲームジャンルで、MMO ではデータベース負荷が激しく、クラウドではまだ怖いところがある。他のプロジェクトでは Fusion IO を使い、物理サーバーを買って、Fusion IO を挿してという形なので、それをそのままクラウドに持って行こうとすると、それに対する知見がないこともあって、クラウドではまだ難しい。でも、もう 1 つ、シュミレーションゲームの方向だと Google を使っていく方向になるかとは思います。あと日本でリリースするときに、日本リージョンがないこと、実際それで特に問題はないことははわかりつつも、海外リージョンの Google を国内向けのタイトルで使う程のこだわりはなくて、そのゲームにあわせた最適なクラウドを選ぶときに、最適であるという観点から日本のリージョン使えるベンダーを選ぶことも、その 1 つの要素であるので。
その他に、英語対応しているのも必須です。AGS でも使えるようにしなければならないので。それと料金が安いのと、中には無茶苦茶なプロジェクトもあって、リリースするまでの期間が長い、例えば 4 月にリリースするとと言っていたのが 1 年延期みたいなことがあるので、無料期間設けてもらったりとか、そういったところを柔軟に対応してもらえると本当に助かりますね。
作りの面でも、共有ストレージを作れない、1 つのサーバ上に何台かの仮想サーバーを立てて、スケールアウトしていくクラウドがあるのですが、そうなると物理サーバがメンテするとき全部止めないといけない。でも共有ストレージ化されているのだったら、vMotion のような機能で動かせ続けられるので、そういったメンテナンス性がどの程度かというのは意識しています。セキュリティ面では、コントロール パネルに対してどういうセキュリティが設定できるかということは見てて、例えば IP 制限がかけられるとか、パスワードの定期変更の通知があるかといったことは見てますね。性能はあまり見れていないですが、ベンチマークして、指標を立てるということはやっています。
サーバーは、自動でスケールさせるようにしているのですか、それともあらかじめ必要なリソースを確保しておく?
前もって確保させていますね。うちのゲーム、例えばログレスを見るとわかると思うのですが、ワールドという概念があるゲームが多くて、それはインフラエンジニアからすると素晴らしいと思っていて、人数を制御できるので。ゲームとしては、良い面も悪い面もあって、ユーザーのみんなが同じところで遊べた方が絶対にいいですけど、ただそうはいってもサーバ障害が起こるよりはいいですから。それで、ローンチする前に 2, 3 ワールド準備しておくんですね。ある程度のユーザーが集まってきたら負荷をみて、別のワールドに流すようにしながら、ある程度ワールド増やしていく。その後、時間がたって、サーバに対してのデイリーのアクティブが下がってきたら、今度はユーザーをマージさせるようにしてるんですよ。そこで気になるのが、サーバーが最初増えるので、ワールド区切るようにしていくと、サーバの台数に制限があるクラウドは使えないです。そういう運営を見据えた選定はしてますね。
高速なリージョン間通信を活かしたゲーム作り
今後 Google Cloud Platform をどう使っていきたいか、何かあれば教えてください。
他のリージョン間でもローカル通信できるというのはいいですね。結局なくなってしまったんですけど、使いたいというプロジェクトもあったんですよ。でも、それを使ったゲームが作れたらとは思っています。
あと、サーバーを立てて MySQL をインストールして使うわけですけど、Google なら
Cloud SQL
があるように、そういうものを使っていくのがベストだと思うので、使っていく方向を探りたいですね。以前、my.cnf をいじる職人さんがいましたが、そういうことに頭を使わずに済むようになったらいい。何億というレコードになると性能という問題に直面しますが、そこは Google が良きに計らってくれて、こちらはデータを入れておけばいいというような。仕事なくなるかもしれないですけど(笑)
次回後半は、BigQuery の利用について話していただきます!
■ Google Cloud Platform のその他の
導入事例はこちら
から
Industriromantik と Compute Engine を使ってクラウドで 3D 画像をレンダリング
2015年5月12日火曜日
* この投稿は、米国時間 5 月 1 日、
Google Cloud Platform US Team によって投稿されたもの
の抄訳です。今回のゲストは、
Industriromantik
のテクニカル ディレクター Fredrik Averpil 氏です。Industriromantik は静止画および動画のコンピュータ生成を専門とするデジタル制作会社で、Fredrik はカスタムのコンピュータ グラフィックス パイプラインを開発しています。
我々は小さなデザインおよび視覚化スタジオで、高解像度の製品画像やテレビ コマーシャルなどの美しい 3D 画像を制作することに注力しています。制作を成功させるためには十分なレンダリング能力が必要ですが、時に社内のレンダリング能力では対応できないという状況がでてきます。これが
Google Compute Engine
を採用した理由です。
3D グラフィックスのパイプライン、アプリケーション、およびプロジェクト ファイルを Compute Engine で処理するようにしたことで、一気にレンダリングのキャパシティをオンデマンドで拡大・伸縮できます。このため、コスト効率を維持しながらプロジェクトのスループットを向上させ、クライアントの要求を満たし、レンダリングのピーク時にも容易に対応することできます。夕食の時間を家庭で過ごせる、というおまけつきです。
図1. これらの高解像インテリアは、我々のカスタム コンピュータ グラフィックス パイプラインを
使用してレンダリング・制作したものです
セットアップ方法
ローカルのレンダリング ジョブの管理ソフトには、非常に堅牢な
Pixar Tractor
を使っています。スケーリング向けに設計されていて、多数のタスクを同時処理できるからです。ローカルのサーバー(アプリケーション、カスタムツール、およびプロジェクトファイルに対応)は、あらかじめレンダリング時間の前に Compute Engine にミラーリングされます。こうすることにより、クラウド レンダリングはローカル レンダリングと同等の速さで応答できます。Compute Engine のインスタンスで Tractor クライアントを実行させることにより、ローカルのオフィスにある Tractor の管理ダッシュボードにそれらがシームレスに表示されます。1600 コア相当のインスタンスを 800 コアのローカルのレンダリング施設に追加できると考えれば、その技術がいかにパワフルかがわかるでしょう。
図2. Google Compute Engineのインスタンスは VPN トンネルを介して
ローカルオフィスの
ネットワークにアクセスする
ファイルサーバーの基本的なセットアップでは、インスタンスに、良好なファイル キャッシング性能を得るのに十分な RAM を搭載しています。50 個 の n1-standard-32 レンダリング インスタンスに対応するファイルサーバーとして n1-highmem-4 インスタンスを使用しています。その後、プロジェクトやアプリケーションを保持させるために、ファイルサーバーのインスタンスに(高い IOPS を得るために 1.5TB の単位で)追加のパーシステント ディスクストレージを接続しています。このパーシステント ディスクのプールに ZFS を使用しているので、レンダリングが進行中であっても、ファイルサーバーのストレージをオンデマンドで増やすことができます。
ZFS
のキャッシュ性能を向上させるために、ローカル SSD ディスクをファイルサーバーのインスタンスに接続することができます(ベータ版機能)。以上はプロジェクトに何を必要としているかによります。つまり、どれだけの数のインスタンスを使用するか、どんなパフォーマンスを必要としているかによってセットアップは異なります。
次に示すように、ファイルサーバーとファイル転送の操作は Google Compute Engine の認証セッションから SSH 経由で行うことが可能で、最終的には Tractor を介して自動化されます。
# Create folder on GCE file server running on public IP address 1.2.3.4 over SSH port 22
ssh -p 22 -t -t 1.2.3.4 -o UserKnownHostsFile=/dev/null -o CheckHostIP=no -o StrictHostKeyChecking=no -i /home/fredrik/.ssh/google_compute_engine "sudo mkdir -p /projects/projx/"
# Upload project files to GCE file server running on public IP address 1.2.3.4 over SSH port 22
rsync -avuht -r -L --progress -e "ssh -p 22 -o UserKnownHostsFile=/dev/null -o CheckHostIP=no -o StrictHostKeyChecking=no -i /home/fredrik/.ssh/google_compute_engine" /projects/projx/ 1.2.3.4:/projects/projx/
バケットにプロジェクト データを保存すると、次のようにしてそこから取り出すこともできます。
# Copy files from bucket onto file server running on public IP address 1.2.3.4 over SSH port 22
ssh -p 22 1.2.3.4 -t -t -o UserKnownHostsFile=/dev/null -o CheckHostIP=no -o StrictHostKeyChecking=no -i /home/fredrik/.ssh/google_compute_engine "gsutil -m rsync -r gs://your-bucket/projects/projx/ /projects/projx/"
Compute Engine 上で実行される(Tractor によって管理された)ソフトウェアは、インターネットを介して、ローカル オフィスが提供するソフトウェア ライセンスにアクセスします。また、Tractor クライアントを実行中のインスタンスは、ローカルの Tractor サーバーに接続できるようにする必要があります。上の図 2 に示すように、これらすべては
VPN
のベータ版を使用することによって実行できます。
ソフトウェア ライセンス数はインスタンス数のようにはオンデマンドでスケールできないので、利用可能な最速のマシン、つまり 32 コアのインスタンスを利用しています。我々が選択した主要なレンダラーである
V-Ray for Maya
でレンダリングすると、16 コアよりも 97-98% のスピードアップになります(素晴らしいスケーリングです!)。
レンダリング タスクが完了すると、ファイルは簡単にローカルの元の場所へコピーバックすることができます。この場合も、フレーム レンダリング完了後に直接 Tractor で管理されます。
# Copy files from Google Compute Engine file server "fileserver-1" onto local machine
gcloud compute copy-files username@fileserver-1:/projects/projx/render/*.exr /local_dest_dir
図3. Tractor のダッシュボード。待機ジョブと標準的な
レンダリング ジョブのタスクツリーを示している
自動化
Compute Engine のレンダリングでは、手作業や細かい管理は避けることを強くお勧めします。複雑なプロセスの自動化は Tractor が優れています。ファイルサーバのスピンアップ、ストレージの割り当て、ファイル転送、などのデイジーチェーン タスクを Tractor で実行させることにより、大規模かつ同時ジョブの管理が容易になります。
図4. Tractorのタスクツリー
図 4 にタスクのデイジーチェーンを示します。Google Compute Engine のファイルサーバーへプロジェクトがアップロードされると、ディスクがファイルサーバーに接続され、ZFS プールに追加されます。必要なソフトウェアの特定のバージョンと共にプロジェクト ファイルがアップロードされます。ディスク ストレージが接続されてからでないとファイルはアップロードされないので、この場合には、いくつかのプロセスは他のプロセスが完了するのを待ってから開始します。
Compute Engine と分単位の課金とによって懸念は解消し、インスタンスの自動スケーリングを好きになることができました。ときどき保留中のタスクのために Tractor を使って(その
query Python API
を使用して)スクリプトをチェックインさせることにより、(
Google Cloud SDK
を介して)インスタンスをスピンアップして、レンダリングを実行させたり、不要になったときにすぐに停止させたりすることができます。このようにして細かな管理を行なうことができます。
図5. ストックホルム、Etaget でのエクテリアの高解像 3D レンダリング
Compute Engine のレンダリングを利用したいけれどもターンキーの管理ソリューションを必要とする人には、 Google Cloud Platform の優れたインフラを利用する
Zync Render
のベータ版を検討することをお勧めします。Zync Render は、ファイル転送を管理する独自のフロントエンド UI を持ち、レンダリングに必要なソフトウェア ライセンスを提供するので、Compute Engine 固有の統合機能を実装する必要はありません。このため、レンダリングの部分が非常に簡単になります。最終的には Zync Render が Google Compute Engine ユーザー向けにソフトウェア ライセンス サーバーを提供し、インスタンスがいくつあってもシームレスにライセンスを拡張できるようになることを願っています。
まとめ
今日 3D レンダリングを扱うすべてのデジタル制作会社は、その規模に関係なく、競争力を維持するためになんらかの形で手頃な価格のクラウド レンダリングを活用する必要があると考えています。また、成功の鍵は自動化に重点を置くことであると信じています。
Google Cloud SDK
は、パワフルな
Google Compute Engine
を
Pixar Tractor
などの先進的で高度にカスタマイズ可能なレンダリング ジョブ管理ソフトと組み合わせることで、これを実行する優れたツールです。これらの先進的なキューイング システムを自分で維持したくない中小企業や個人のために、
Zync Render
は Compute Engine のインフラを利用しています。
コンピュータ グラフィックス パイプラインに関する他の記事やヒントについては、
http://fredrik.averpil.com
で Fredrik のブログを参照してください。また、Industriromantik の詳細については、
http://www.industriromantik.se
を参照してください。
-- Google Cloud Platform Japan Team
Cloud Logging Connector ベータ公開: Cloud Pub/Sub へストリーム
2015年5月11日月曜日
* この投稿は、米国時間 4 月 30 日、Product Manager の
Deepak Tiwari によって投稿されたもの
の抄訳です。
今年の初めに
Google Cloud Logging
のベータ版を発表しました。その特長は次のようなものです。
Google BigQuery
へリアルタイムでログをストリームできるので、ログデータを分析して直ちにインサイトを見つけることができる。
Google Cloud Storage
(
Nearline
を含む)へログをエクスポートできるので、長期にわたってログデータをアーカイブして、バックアップやコンプライアンス要件を満たすことができる。
そして今回は Cloud Logging の拡張機能、Cloud Logging Connector のベータ版を発表します。この機能で、ログを
Google Cloud Pub/Sub
へストリームすることができるようになります。ログデータを指定したエンドポイントにストリームできるので、ビッグデータをさらに広く有効活用することができます。例えば、分析を行うために BigQuery へデータを送信する前に、
Cloud Dataflow
の中でデータを変換・修正したり、すべてのログデータにリアルタイムでアクセスできるので、プライベートなクラウドやサードパーティーのアプリケーションにエクスポートすることもできます。
Cloud Pub/Sub
Google Cloud Pub/Sub
は、1 つのグローバルなマネージド サービスでリアルタイムかつ信頼性の高いメッセージングを提供するもので、シンプルでより信頼性が高く、より柔軟なアプリケーションを作成することができます。多対多の、送信側と受信側を分離する非同期メッセージングを提供することにより、個別アプリケーション間で安全かつ可用性の高い通信が可能になります。Cloud Pub/Sub によって、ログのイベントを他の Webhook へ送信したり、イベントが発生したときに受信したりすることができます。詳細については、Google Cloud Pub/Sub の
ドキュメンテーション
を参照してくださ
Cloud Pub/Subへのエクスポートを設定する
Cloud Pub/Sub へのログエクスポートの設定は容易で、
Logs Viewer
のユーザー インターフェースから行うことができます。
Developers Console
の中からエクスポート設定をするには、「監視」の下の「ログ」に移動し、トップメニューで「エクスポート」をクリックします。現時点では、
Google App Engine
と
Google Compute Engine
のログのエクスポート設定をサポートしています。
Developers Consoleの中でエクスポートをワンクリックで設定
Dataflowの中でログデータを変換する
Google Cloud Dataflow
を使用すると、任意のスケールでデータ処理パイプラインを構築、デプロイ、および実行することができます。ETL や分析などの大規模なデータ処理シナリオを高い信頼性で実行し、パイプラインをストリーミングまたはバッチモードのいずれかを選択して実行することができます。
Cloud Pub/Sub のエクスポート メカニズムを使用すれば、Cloud Dataflow へログデータをストリームし、動的にフィールドを生成し、相関のために別のログテーブルを結合し、カスタムニーズに合わせてデータを分析および修正することができます。Cloud Dataflow の中のログデータで実行可能な例を次にいくつか紹介します。
トップカスタマーの主要なデータだけを表示:
Cloud Dataflow では、カスタマ ID やアプリケーション ID によってログをグループ分けし、特定のログをフィルタで除外し、システムレベルまたはアプリケーションレベルの基準を特定の形で組み合わせて適用できます。
ログデータを分析しやすいように加工:
販売キャンペーン情報を顧客対話のログや他のユーザープロファイル情報に追加できます。
リアルタイムの分析:
詳細な分析のためにデータを準備することに加えて、Cloud Dataflow ではリアルタイムで分析することもできます。従って、異常の監視、セキュリティ侵入の検知、アラートの生成、リアルタイムでのダッシュボードの更新、などが可能です。
Cloud Dataflow は処理済みデータを BigQuery にストリームできるので、すでに加工されたデータで分析することができます。詳細については、Google Cloud Dataflow の
ドキュメンテーション
を参照してください。
はじめるには
現在、
Google Cloud Platform
のユーザーなら、Cloud Pub/Sub へのログのストリーム機能は追加料金なしで利用できます。Cloud Pub/Sub および Cloud Dataflow の使用は有料です。詳細については、
Cloud Logging ドキュメンテーション
を参照してください。
フィードバック
をお寄せください。
-Posted by Deepak Tiwari, Product Manager
Google Cloud Bigtable をベータ公開:Google の検索や Gmail をサポートするデータベースが Google Cloud Platform で利用可能に
2015年5月8日金曜日
* この投稿は、米国時間 5 月 7 日、Product Manager の
Cory O’Connor によって投稿
されたものの抄訳です。
今のビジネスはますますデータ セントリックになり、
IoT
(Internet of Things)の時代の到来とともに、データから効率的にインサイトを引き出せるようになる必要性がでてきました。こういった状況で、アプリケーションよりもインフラの構築や管理に時間を費やすのは機会を逃しているようなものです。
そこで、今回、
Google Cloud Bigtable
ベータ版の公開を発表します。Google Cloud Bigtable は、業界標準かつオープンソースの
Apache HBase
API を介してアクセス可能な、フルマネージドの高性能できわめてスケーラブルな NoSQL データベースサービスです。Cloud Bigtable の裏側は、Google が提供するサービスのほぼすべてに使用されているデータベース、
Bigtable
です。
Google Cloud Bigtable
は、大規模なインジェスチョン、分析、およびデータ処理量の多いワークロードに優れており、膨大なデータを処理しなければならない企業やデータ主導型の組織、例えば金融サービスやアドテクノロジー、エネルギー、生物医学、電気通信業界の企業などに最適です。
Cloud Bigtable の特長は以下の通りです。
高いパフォーマンス
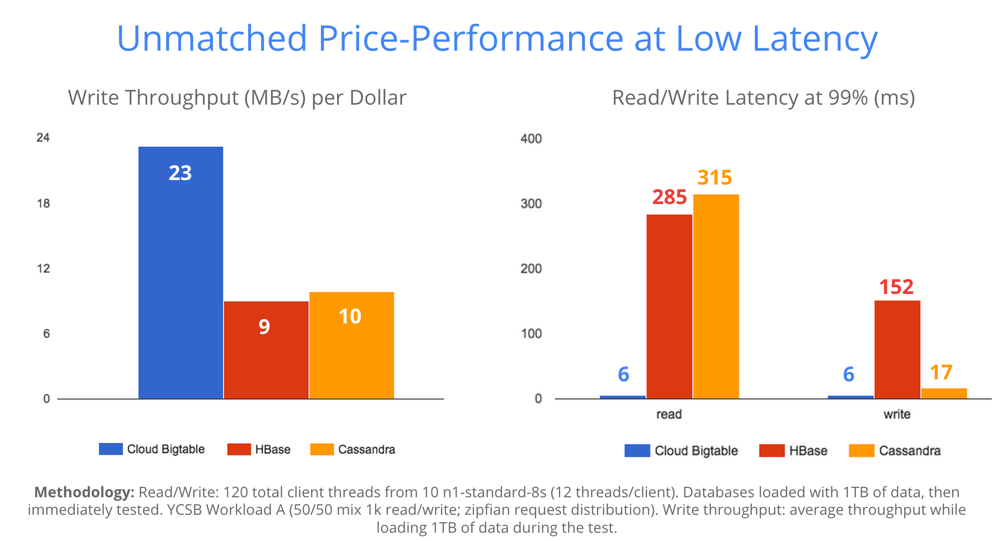
:アンマネージド NoSQL データベースの 1 桁のミリ秒のレイテンシおよび
2 倍以上のコストパフォーマンス
を得られます。
オープンソース インターフェース
:Cloud Bigtable は HBase API を介してアクセスされるので、既存のビッグデータや
Hadoop
エコシステムの多くとネイティブに統合され、Google の
ビッグデータ
製品
をサポートします。さらに、業界標準のフォーマットを使用し、シンプルなバルク インジェスチョン ツールを介して、既存の HBase クラスタとの間でデータをインポート/エクスポートすることができます。
低コスト
:フルマネージド サービスと優れた効率性で、Cloud Bigtable の総所有コストは直接競合する製品の半分以下で済みます。
セキュリティ
:Cloud Bigtable は、複製型ストレージ戦略で構築され、すべてのデータは操作中および休止中の両方で暗号化されます。
シンプル
: Cloud Bigtable クラスターの作成や再構成は、シンプルな UI を介して行え、10 秒未満で完了できます。データが Cloud Bigtable に入るとストレージがオートでスケールし、複雑なキャパシティ要件の見積りを行う必要はありません。
製品としての実績と高い完成度
:過去 10 年以上にわたり、 Bigtable は Google の最も重要なサービスに使用されてきました。また、
HBase API
は運用と分析が組み合わされたワークロードのための業界標準インタフェースとなっています。
Cloud Bigtable を提供するサービス パートナーもおり、ユーザーが独自の環境でデータストレージに取組むための、新しいアプローチをサポートします。
SunGard
は大手の金融ソフトウェアおよびサービス会社であり、スケーラブルかつ管理が容易な金融データのプラットフォームを Cloud Bigtable で構築する際に助けになります。実際、毎秒 250 万という大量の取引メッセージをインジェストすることが可能な金融監査証跡システムをすでに Cloud Bigtable で構築しています。
Pythian
は世界的なデータコンサルティング会社であり、
OpenTSDB
と Cloud Bigtable を統合して、モニタリングおよびメトリック収集のプラットフォームを提供しています。
CCRi
はオープンソースの時空間データベース “
GeoMesa
” のコントリビュータおよびサポーターです。GeoMesa と Cloud Bigtable を統合することで、CCRi はリアルタイムな地理空間分析のためのスケーラブルなプラットフォームをクラウドで提供しています。
Telit Wireless Solutions
は IoT において世界的なリーダーであり、IoT EAP (アプリケーション イネーブルメント プラットフォーム)である "
m2mAIR
" を Cloud Bigtable と統合して、データ インジェスチョンにおいて高いパフォーマンスを可能にしています。
今回の発表で、どなたでも
Google Cloud Bigtable
ベータ版を利用できます。Google ではすでに
Qubit
のようなユーザーが Cloud Bigtable にペタバイト級の HBase デプロイメントを移行するのをサポートしています。こうしたパワフルな Google の技術を使って、驚くべき革新的なアプリケーションが作成されるのを楽しみにしています。技術的な質問があれば、’google-cloud-bigtable’ というタグを付けて
Stack Overflow
にポストしてください。また、フィードバックや機能のご要望があれば、
フィードバック リスト
に送ってください。
-Posted by Cory O’Connor, Product Manager
Streak による App Engine の 6 つのポイントをご紹介
2015年5月1日金曜日
* この投稿は、米国時間 4 月 28 日、Streak の CEO であり co-founder である
Aleem Mawani によって投稿されたもの
の抄訳です。
Streak
(CRM in your inbox ) が 2012 年 3 月に発表されると、当社のユーザーは 4 ヶ月連続で毎週 30% 増加しました。現在、Streak はわずか 1.5 人のバックエンドのエンジニアで数百万のユーザーをサポートしています。このアプリケーションを機能させるのに
Google App Engine
を選択したのは、迅速な構築が可能で、ユーザー増加に伴ってスケールできるという理由からです。そのうえ、インフラについても心配する必要がありません。
App Engine 上に構築する際に学んだ 6 つのポイントを以下に示します。さらに詳しく知りたい場合は(アプリケーションのアーキテクチャ概要および 15 分間の Q&A を含め)
webinar
を参照してください。
1. ユーザーの GET リクエストへの高速対応
これは App Engine に固有のものではなく、ほとんどの Web アプリケーションにも言えることです。ユーザーの GET リクエストには迅速に対応しなければなりませんが、App Engine の場合すべてのリクエストに対して
60 秒でタイムアウト
します。実際、ユーザーとの対話後の全待ち時間が 200ms 以上にもなれば、ユーザーはアプリが遅いと思うでしょう。リクエストに高速に対応するには、計算や複雑なクエリなどの重い処理をバックグラウンドあるいは書き込み時のいずれかで行う必要があります。そうすれば、ユーザーがデータをリクエストしたときには(読み出し時には)、すでに事前に計算されており、提供する準備ができていることになります。
2. Managed VMs の利用
次に Managed VMs についてみてみましょう。
Managed VMs
は App Engine のための新しいホスティング環境で、大規模なコンピューティング リソースを活用したり、カスタムのランタイムを実行したりすることができます。例えば、我々はバックエンドのデータ処理モジュールを
App Engine のフロントエンド インスタンス
ではなく、n1-standard-1 マシン(1 CPU と 3.75 GB のメモリ)のインスタンスにホストしています。これは、
sustained use discounts
という継続割引を利用することで優れたコストパフォーマンスが得られます。Managed VMs は App Engine のフロントエンド インスタンスよりも起動が速く、我々のバックグラウンド処理のニーズに最適です。
3. 高速読み出しのための非正規化
Cloud Datastore
は NoSQL データベースですので、データモデリングに関しては RDBM とは異なったアプローチが必要になります。SQL の join が存在しないので、データの
非正規化
と複製は行わなければなりません。データの複製が面倒に感じることがあっても、読み出しを非常に高速にすることができます。
4. アプリケーションのモジュールへの分割
Modules
によって App Engine のアプリをさまざまなコンポーネントに簡単に分割できます。例えば、ユーザーサイドのトラフィックとバックグラウンド処理とに別々のモジュールを持たせることができます。各モジュールはそれぞれ yaml ファイルを持っているので、インスタンスのサイズ、バージョン番号、使用するランタイム言語、など多くのパラメータを設定することができます。前述のように、バックエンド モジュールには性能対コスト比に優れた Managed VMs を使用する一方で、フロントエンド モジュールには素早くスケール可能な App Engine のフロントエンド インスタンスを使用しています。ドキュメントでは
アプリ構築の方法
を説明しています。
5. 積極的なデプロイとトラフィック分割の使用
App Engine ではバージョン管理、デプロイメント、およびロールアウトが簡単にできますので、Streak のデプロイメントは始終行っています。実際、変更を顧客に提供するために、ときには 1 日に 20 回デプロイを実行することがあります。積極的にデプロイを行ってアプリの多くのバージョンを作成し、選択的に新機能を有効にしてユーザーに提供しています。
トラフィック分割
により新しいバージョンのトラフィックはわずかしか増加しないので、問題があっても早期かつ高頻度で補足できます。それぞれの新しいコードのデプロイは小さな機能しか持たないので簡単に対処することができます。従って、コードベースで関連する問題を見つけるのも容易です。また、
Google Cloud Monitoring
と(下記の #6 をベースとした)当社独自のシステムを使用して、これらデプロイの変更を監視しています。
6. BigQuery を用いたログファイルの分析
アプリケーションとリクエストのログはパフォーマンスを知るうえで貴重な情報となり、製品の改善に役立ちます。スタートしたばかりなら、最新のリクエストに関するログビューアのリストだけでも役立ちますが、ある規模に達したら、集計データや特定ユーザーのリクエストを分析する必要がでてくるでしょう。我々は
Google BigQuery
にログをエクスポートするためのカスタムコードを作成しましたが、今では Developers Console から直接
ログをストリーム
することができます。これらによって、優れたユーザー エクスペリエンスを構築することができます。
Webinar を見てみる
App Engine は我々の成功にとって不可欠なものとなっています。アプリケーションがスケールするにつれて App Engine もスケールするので、運用に対してではなく、顧客に提供する機能の構築に焦点を当てることができます。当社のアーキテクチャ概要と 15 分間の Q&A を含め、App Engine 利用のポイントの詳細については、
webinar
をご確認ください。
-Posted by Aleem Mawani, CEO and co-founder, Streak
12 か月間のトライアル
300 ドル相当が無料になるトライアルで、あらゆる GCP プロダクトをお試しいただけます。
Labels
.NET
.NET Core
.NET Core ランタイム
.NET Foundation
#gc_inside
#gc-inside
#GoogleCloudSummit
#GoogleNext18
#GoogleNext19
#inevitableja
Access Management
Access Transparency
Advanced Solutions Lab
AI
AI Hub
AlphaGo
Ansible
Anthos
Anvato
Apache Beam
Apache Maven
Apache Spark
API
Apigee
APIs Explore
App Engine
App Engine Flex
App Engine flexible
AppArmor
AppEngine
AppScale
AprilFool
AR
Artifactory
ASL
ASP.NET
ASP.NET Core
Attunity
AutoML Vision
AWS
Big Data
Big Data NoSQL
BigQuery
BigQuery Data Transfer Service
BigQuery GIS
Billing Alerts
Bime by Zendesk
Bitbucket
Borg
BOSH Google CPI
Bower
bq_sushi
BreezoMeter
BYOSL
Capacitor
Chromium OS
Client Libraries
Cloud API
Cloud Armor
Cloud Audit Logging
Cloud AutoML
Cloud Bigtable
Cloud Billing Catalog API
Cloud Billing reports
Cloud CDN
Cloud Client Libraries
Cloud Console
Cloud Consoleアプリ
Cloud Container Builder
Cloud Dataflow
Cloud Dataflow SDK
Cloud Datalab
Cloud Dataprep
Cloud Dataproc
Cloud Datastore
Cloud Debugger
Cloud Deployment Manager
Cloud Endpoints
Cloud Firestore
Cloud Foundry
Cloud Foundry Foundation
Cloud Functions
Cloud Healthcare API
Cloud HSM
Cloud IAM
Cloud IAP
Cloud Identity
Cloud IoT Core
Cloud Jobs API
Cloud KMS
Cloud Launcher
Cloud Load Balancing
Cloud Machine Learning
Cloud Memorystore
Cloud Memorystore for Redis
Cloud monitoring
Cloud NAT
Cloud Natural Language API
Cloud Networking
Cloud OnAir
Cloud OnBoard
cloud Pub/Sub
Cloud Resource Manager
Cloud Resource Manager API
Cloud SCC
Cloud SDK
Cloud SDK for Windows
Cloud Security Command Center
Cloud Services Platform
Cloud Source Repositories
Cloud Spanner
Cloud Speech API
Cloud Speech-to-Text
Cloud SQL
Cloud Storage
Cloud Storage FUSE
Cloud Tools for PowerShell
Cloud Tools PowerShell
Cloud TPU
Cloud Translation
Cloud Translation API
Cloud Virtual Network
Cloud Vision
Cloud VPC
CloudBerry Backup
CloudBerry Lab
CloudConnect
CloudEndure
Cloudflare
Cloudian
CloudML
Cluster Federation
Codefresh
Codelabs
Cohesity
Coldline
Colossus
Compute Engine
Compute user Accounts
Container Engine
Container Registry
Container-Optimized OS
Container-VM Image
Couchbase
Coursera
CRE
CSEK
Customer Reliability Engineering
Data Studio
Databases
Dbvisit
DDoS
Debugger
Dedicated Interconnect
deep learning
Deployment Manager
Developer Console
Developers
DevOps
Dialogflow
Disney
DLP API
Docker
Dockerfile
Drain
Dreamel
Eclipse
Eclipse Orion
Education Grants
Elasticsearch
Elastifile
Energy Sciences Network
Error Reporting
ESNet
Evernote
FASTER
Fastly
Firebase
Firebase Analytics
Firebase Authentication
Flexible Environment
Forseti Security
G Suite
Gartner
gcloud
GCP
GCP Census
GCP 移行ガイド
GCP 認定資格チャレンジ
GCPUG
GCP導入事例
gcsfuse
GEO
GitHub
GitLab
GKE
Go
Go 言語
Google App Engine
Google Apps
Google Certified Professional - Data Engineer
Google Cloud
Google Cloud Certification Program
Google Cloud Client Libraries
Google Cloud Console
Google Cloud Dataflow
Google Cloud Datalab
Google Cloud Datastore
Google Cloud Endpoints
Google Cloud Explorer
Google Cloud Identity and Access Management
Google Cloud INSIDE
Google Cloud INSIDE Digital
Google Cloud INSIDE FinTech
Google Cloud Interconnect
Google Cloud Launcher
Google Cloud Logging
Google Cloud Next '18 in Tokyo
Google Cloud Next '19 in Tokyo
Google Cloud Platform
Google Cloud Resource Manager
Google Cloud Security Scanner
Google Cloud Shell
Google Cloud SQL
Google Cloud Storage
Google Cloud Storage Nearline
Google Cloud Summit '18
Google Cloud Summit ’18
Google Cloud Tools for IntelliJ
Google Code
Google Compute Engine
Google Container Engine
Google Data Analytics
Google Data Studio
Google Date Studio
Google Deployment Manager
Google Drive
Google Earth Engine
Google Genomics
Google Kubernetes Engine
Google maps
google maps api
Google Maps APIs
Google Maps Platform
Google SafeSearch
Google Service Control
Google Sheets
Google Slides
Google Translate
Google Trust Services
Google VPC
Google マップ
Google 公認プロフェッショナル
GoogleNext18
GPU
Gradle
Grafeas
GroupBy
gRPC
HA / DR
Haskell
HEPCloud
HIPAA
Horizon
HTCondor
IaaS
IAM
IBM
IBM POWER9
icon
IERS
Improbable
INEVITABLE ja night
inevitableja
InShorts
Intel
IntelliJ
Internal Load Balancing
Internet2
IoT
Issue Tracker
Java
Jenkins
JFrog
JFrog Artifactory SaaS
Jupiter
Jupyter
Kaggle
Kayenta
Khan Academy
Knative
Komprise
kubefed
Kubeflow Pipelines
Kubernetes
KVM
Landsat
load shedding
Local SSD
Logging
Looker
Machine Learning
Magenta
Managed Instance Group
Managed Instance Group Updater
Maps API
Maps-sensei
Mapsコーナー
Maven
Maxon Cinema 4D
MightyTV
Mission Control
MongoDB
MQTT
Multiplay
MySQL
Nearline
Network Time Protocol
Networking
neural networks
Next
Node
NoSQL
NTP
NuGet パッケージ
OCP
OLDISM
Open Compute Project
OpenCAPI
OpenCAPI Consortium
OpenShift Dedicated
Orbitera
Organization
Orion
Osaka
Paas
Panda
Particle
Partner Interconnect
Percona
Pete's Dragon
Pivotal
Pivotal Cloud Foundry
PLCN
Podcast
Pokemon GO
Pokémon GO
Poseidon
Postgre
PowerPoint
PowerShell
Professional Cloud Network Engineer
Protocol Buffers
Puppet
Pythian
Python
Qwiklabs
Rails
Raspberry Pi
Red Hat
Redis
Regional Managed Instance Groups
Ruby
Rust
SAP
SAP Cloud Platform
SC16
ScaleArc
Secure LDAP
Security & Identity
Sentinel-2
Service Broker
Serving Websites
Shared VPC
SideFX Houdini
SIGOPS Hall of Fame Award
Sinatra
Site Reliability Engineering
Skaffold
SLA
Slack
SLI
SLO
Slurm
Snap
Spaceknow
SpatialOS
Spinnaker
Spring
SQL Server
SRE
SSL policies
Stack Overflow
Stackdriver
Stackdriver Agent
Stackdriver APM
Stackdriver Debugger
Stackdriver Diagnostics
Stackdriver Error Reporting
Stackdriver Logging
Stackdriver Monitoring
Stackdriver Trace
Stanford
Startups
StatefulSets
Storage & Databases
StorReduce
Streak
Sureline
Sysbench
Tableau
Talend
Tensor Flow
Tensor Processing Unit
TensorFlow
Terraform
The Carousel
TPU
Trace
Transfer Appliance
Transfer Service
Translate API
Uber
Velostrata
Veritas
Video Intelligence API
Vision API
Visual Studio
Visualization
Vitess
VM
VM Image
VPC Flow Logs
VR
VSS
Waze
Weave Cloud
Web Risk AP
Webyog
Wide and Deep
Windows Server
Windows ワークロード
Wix
Worlds Adrift
Xplenty
Yellowfin
YouTube
Zaius
Zaius P9 Server
Zipkin
ZYNC Render
アーキテクチャ図
イベント
エラーバジェット
エンティティ
オンライン教育
クラウド アーキテクト
クラウド移行
グローバル ネットワーク
ゲーム
コードラボ
コミュニティ
コンテスト
コンピューティング
サーバーレス
サービス アカウント
サポート
ジッター
ショート動画シリーズ
スタートガイド
ストレージ
セキュリティ
セミナー
ソリューション ガイド
ソリューション: メディア
データ エンジニア
データセンター
デベロッパー
パートナーシップ
ビッグデータ
ファジング
プリエンプティブル GPU
プリエンプティブル VM
フルマネージド
ヘルスケア
ホワイトペーパー
マイクロサービス
まっぷす先生
マルチクラウド
リージョン
ロード シェディング
運用管理
可用性
海底ケーブル
機械学習
金融
継続的デリバリ
月刊ニュース
資格、認定
新機能、アップデート
深層学習
深層強化学習
人気記事ランキング
内部負荷分散
認定試験
認定資格
料金
Archive
2019
8月
7月
6月
5月
4月
3月
2月
1月
2018
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2017
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2016
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2015
12月
11月
10月
9月
8月
7月
6月
5月
4月
3月
2月
1月
2014
12月
11月
10月
9月
8月
6月
5月
4月
3月
2月
Feed
月刊ニュースレターに
登録
新着ポストをメールで受け取る
Follow @GoogleCloud_jp