Pub/Sub キュー ベースの自動スケーリングを容易にするグループあたりの Stackdriver 指標
Google Cloud Japan Team
Compute Engine 環境でマネージド インスタンス グループを使用している場合でも、ワーカーの VM インスタンスをキュー内のジョブに応じて効率的にスケーリングすることは、依然として容易ではありません。時にはキューが空のこともあり、そうなると、お金やリソースを浪費しないようにワーカーをゼロにしたくなります。逆に、キューがいきなり満杯になり、確保できるワーカーがすべて必要になることもあります。また、継続的に発生する作業を一貫したペースで処理したい場合もあるでしょう。
こうした状況への対処を支援するため、私たち Google は先ごろ、マネージド インスタンス グループにおけるグループあたりのモニタリング指標に基づいた自動スケーリングをベータ リリースしました。
この自動スケーリングを使用すれば、上述のようなシナリオにも対応できるシンプルなキュー ベースのスケーリング システムを構築できます。この機能は、これまで未サポートだった Stackdriver のモニタリング指標(Cloud Pub/Sub キューの作業量など)に基づいて、マネージド インスタンス グループをスケーリングできるようにしたことで実現されています。
これは大きな進歩です。これまでの最善策は、大量の作業に備えてワーカー プールのサイズを静的に設定するか、あるいはキュー内のジョブをモニタリングするカスタム コードを作成し、現在の作業量に応じてワーカー プールを手動でスケールアップ / ダウンするかのいずれかでした。
グループあたりのモニタリング指標の使用例
グループあたりのモニタリング指標に基づいた自動スケーリングの設定方法を、例を通して見ていきましょう。ここではシンプルなセットアップを考えます。データ ジョブを受信し、受信したジョブを順次処理するとします。1 件のジョブを処理するのに数分かかり、到着するジョブは予測不能なタイミングで急増することがあります。新しいデータ ジョブが発生すると、Cloud Pub/Sub メッセージが作成されて送信され、これらのメッセージが増えると、Pub/Sub キュー内の未処理のメッセージ数が Stackdriver Monitoring の指標としてエクスポートされます。このエクスポートされた指標に基づいてワーカーの数を増やしていき、ワーカーは Pub/Sub メッセージをプルしてデータを処理し、Pub/Sub キューの長さを短くします。
以上を実行に移すには、最初に、自動スケーリングを有効にしたマネージド インスタンス グループを Cloud Console で作成します。この例では、Pub/Sub キューを構成済みで、使用するインスタンス テンプレートとワーカー イメージの準備が整っているものとします。
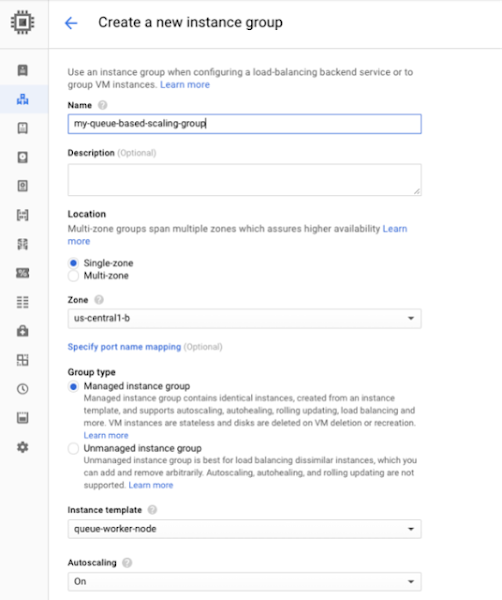
次に、“Autoscale based on”(自動スケーリングの基準)を“Stackdriver monitoring metric”(Stackdriver Monitoring の指標)に、“Metric export scope”(指標のエクスポート スコープ)を“Single time series per group”(グループあたりの単一時系列)に設定します。この設定により、個々のインスタンスから独立した指標に基づいてスケーリングされるようにマネージド インスタンス グループが構成されます。CPU 使用率のような一般的なスケーリング指標とは異なり、キューの長さはマネージド インスタンス グループ内のインスタンスから独立しています。
また、“Metric identifier”(指標 ID)を、特定のサブスクリプション名でフィルタリングされた未配送の Pub/Sub メッセージ数に設定します。これにより、オートスケーラはスケーリングの基準となる適切な Pub/Sub キューを見つけることができます。
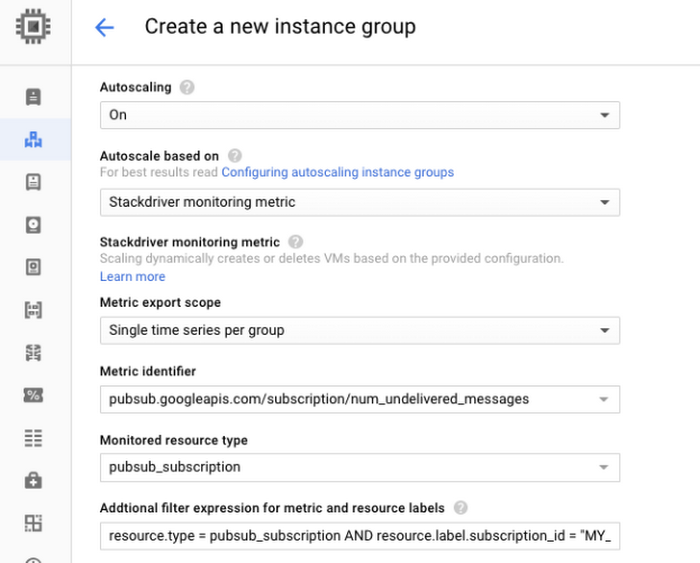
これで、マネージド インスタンス グループが適切な指標と関連づけられました。続いて、グループがスケールアップ / ダウンするタイミングを設定します。“Scaling policy”(スケーリング ポリシー)を“Single instance assignment”(単一インスタンスの割り当て)にして、それに “2” を指定します。これによってマネージド インスタンス グループは、キュー内の未処理メッセージ 2 件につき 1 つのワーカー インスタンスを持ちます。
最後に、マネージド インスタンス グループ内のインスタンスの最小数と最大数を設定します。この例では、作業がないときはグループ内のインスタンスをゼロにスケールダウンしたいので、“Minimum number of instances”(インスタンスの最小数)に “0” を指定します。また、“Maximum number of instances”(インスタンスの最大数)には、ワークロードにとって意味のある数を指定します(この例では “20” とします)。
グループあたりの指標に基づくスケーリングをプログラム的に設定することもできます。それには、Google Cloud SDK CLI ツールで記述された以下のコマンドを実行します。
これで準備完了です。Pub/Sub キューにメッセージが到着するとマネージド インスタンス グループがスケールアップし、メッセージが処理されるとスケールダウンします。すべてのメッセージが処理されてキューが空になると、マネージド インスタンス グループはグループ内のすべてのマシンをシャットダウンします。したがって、使っていないリソースの料金がかかることはありません。
下の図は、マネージド インスタンス グループ内のインスタンス数が Pub/Sub キューの長さに応じてどのように変わるかを示しています(タイムステップは 10)。
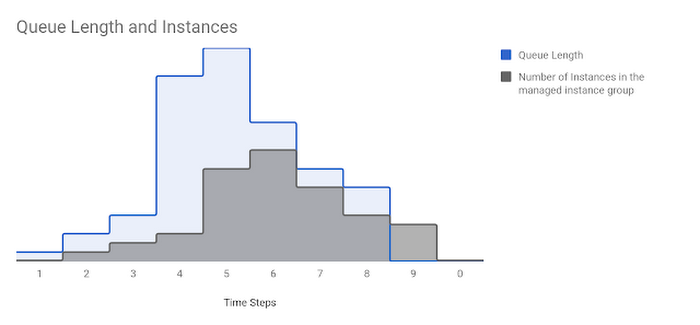
キュー内の作業が増え始めると、マネージド インスタンス グループは、キュー内の未処理メッセージ 2 件につき平均 1 インスタンス増のペースでスケールアップします。キュー内の作業量がタイムステップ 6 で減り始めると、マネージド インスタンス グループもそれに合わせてスケールダウンします。タイムステップ 9 でキューが空になると、マネージド インスタンス グループもタイムステップ 10 でインスタンス数がゼロになります。作業が新たに発生するまで、インスタンス数はゼロのままです。
他のキューイング システムにも有効
以上のように、キュー内のジョブに対応する形でマネージド インスタンス グループの自動スケーリングをセットアップすることは、このうえなく簡単です。作業量を測定する 1 つの指標とワーカーごとのシンプルな作業割り当てにより、応答性の高いスケーリング システムを数回のクリックでセットアップできます。さらに、このアプローチは Pub/Sub キュー以外のキューイング システムにも有効です。作業量を Stackdriver の指標としてエクスポートし、その指標に応じてノードごとに作業を割り当てることができれば、マネージド インスタンス グループの適切なスケーリングが可能になり、コストの最適化に役立ちます。
この機能を使ってみたい方は、詳細に関するドキュメントをご覧ください。
* この投稿は米国時間 3 月 2 日、Product Manager の Pawel Siarkiewicz によって投稿されたもの(投稿はこちら)の抄訳です。
- By Pawel Siarkiewicz, Product Manager



