ラーメン二郎とブランド品で AutoML Vision の認識性能を試す
Google Cloud Japan Team
この投稿は米国時間 3 月 26 日に投稿されたもの(投稿はこちら)の抄訳です。
Posted by Google Cloud デベロッパー アドボケイト 佐藤一憲
この 3 つのラーメンは、41 店舗あるラーメン二郎のうち 3 店舗で作られたものです。それぞれ、どの店舗で出されたものか分かりますか? データ サイエンティストの土井賢治さんが作成した機械学習(ML)によるラーメン識別器を使えば、それぞれの微妙な盛り付けの違いを見分けることで、95% の精度で店舗を特定できます。

この写真を見ても分かるとおり、ラーメン二郎の相当コアなファンでもなければ、ラーメン画像から 41 店舗のどこで作られたかを見分けることは簡単ではありません。テーブルやどんぶりの色、形にあまり違いのない場合が多いのです。
土井さんは、ディープ ラーニングを使ってこの問題を解けるか興味を持ち、インターネット上から 48,244 枚のラーメン二郎画像を集めました。ML モデルの学習に合わない画像(重複したもの、どんぶりが写ってないもの等)を取り除いたあと、1,170 枚 × 41 店舗 = 約 48,000 枚の画像とそれぞれの店舗ラベルを用意しました。
AutoML Vision で 94.5% の精度を達成
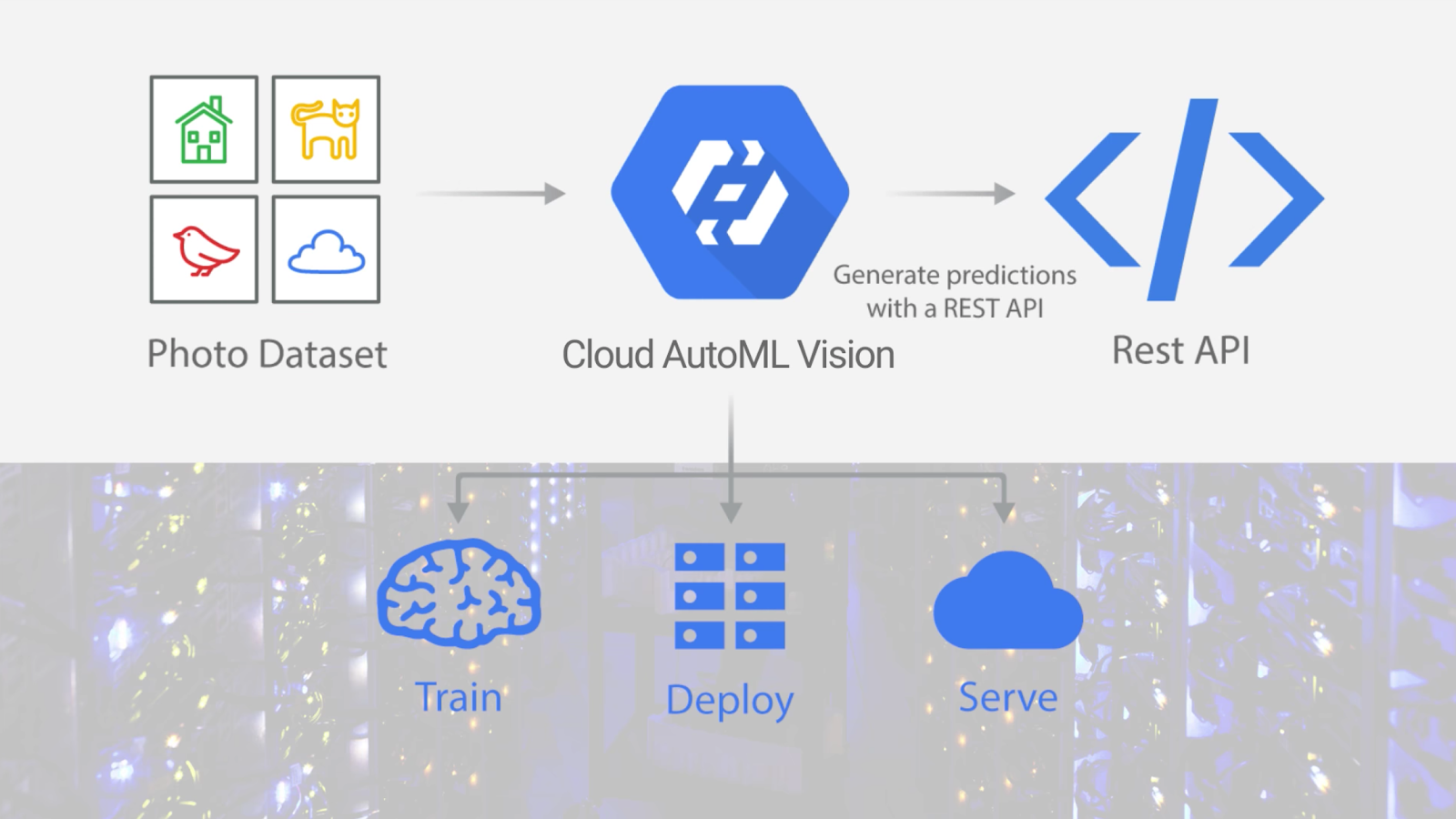
そして土井さんは、今年 1 月、Google が AutoML Vision のアルファ版を公開したことを知りました。AutoML Vision は、ML の知識のない方でも、任意の画像を用いて ML モデルの学習を簡単に行えるサービスです。学習用の画像ファイルとラベルをアップロードするだけで、学習を開始できます。学習が終わったら、その ML モデルをスケーラブルなプラットフォーム上で簡単に運用できます。このすべての手順を、データ サイエンティストや ML 専門家の知識なしで進められます。
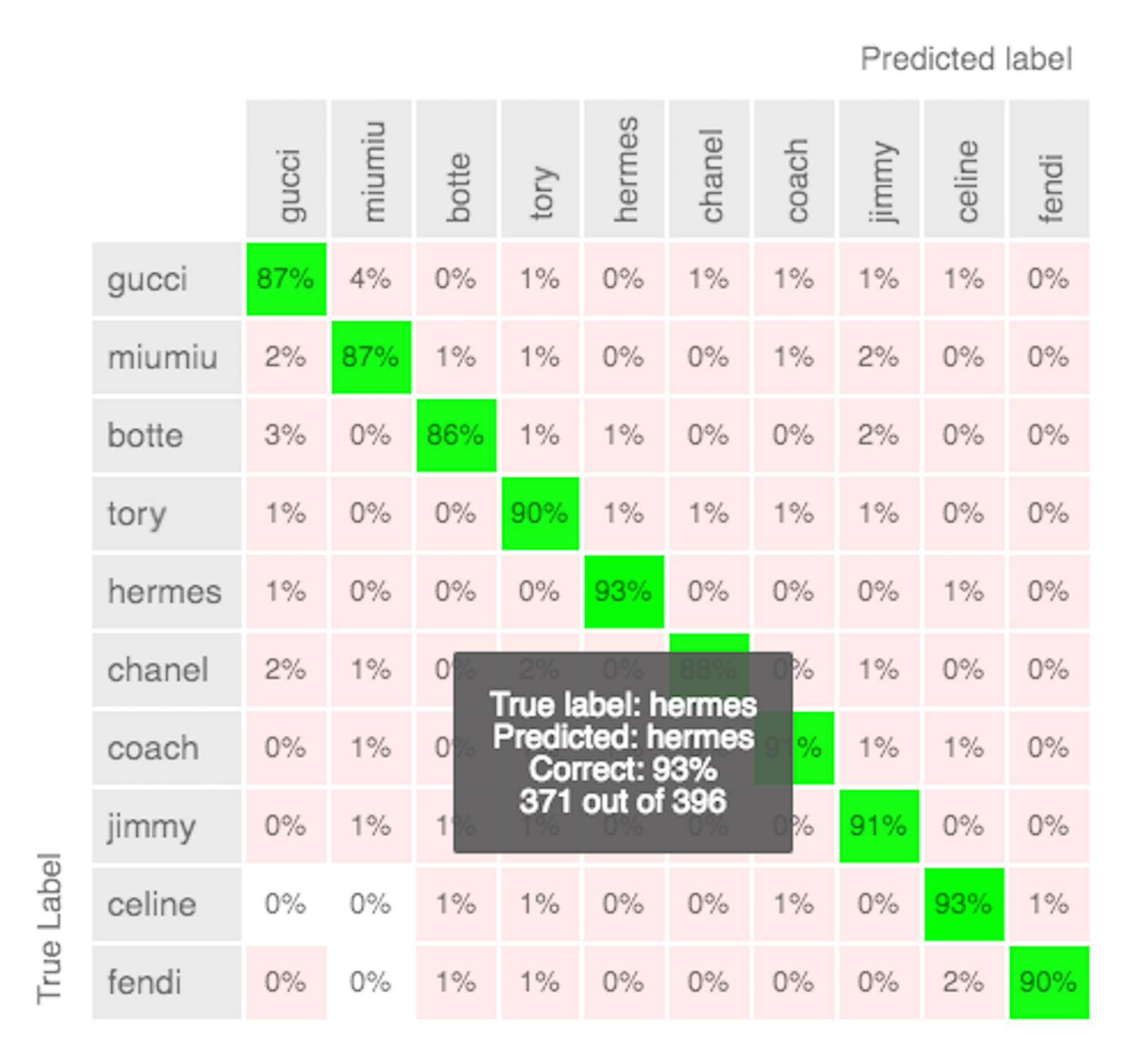
土井さんは AutoML Vision のアルファ版に申し込み、さっそくラーメン二郎画像でその性能を試してみました。上述の 48,000 枚の画像で学習したところ、94.5% の精度(94.8% precision、94.5% recall)がすぐさま得られました。
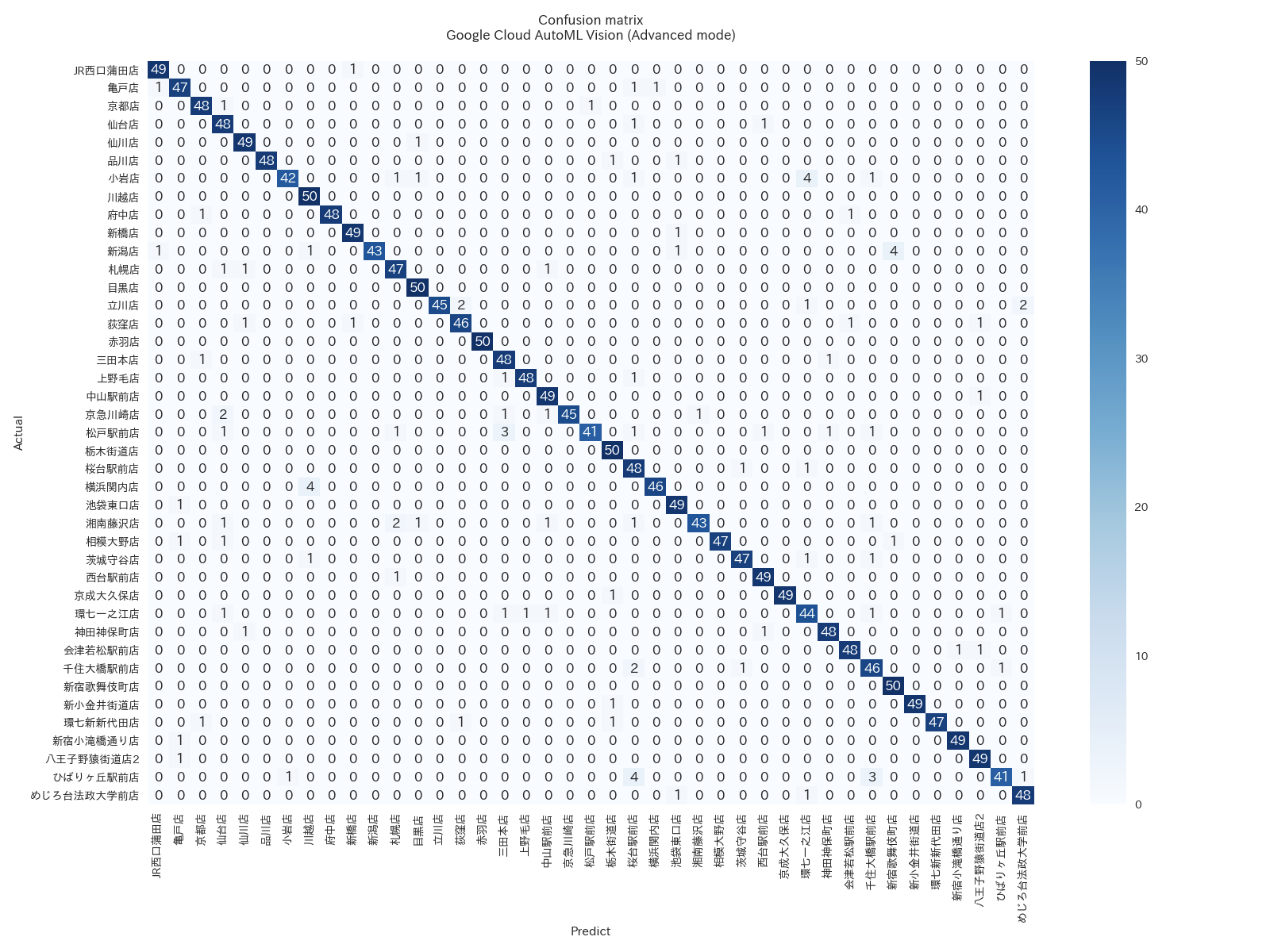
(各行は実際の店舗、各列は予測された店舗)
上記の混同行列を見ると、AutoML Vision がそれぞれのテスト ケースでごくわずかな間違いししか起こしていないことがわかります。
なぜディープ ラーニングはここまで高い精度で店舗を見分けられるのでしょうか? 個々の写真にどのような違いがあるのでしょう? 土井さんは当初、テーブルやどんぶりの色や形の違いを ML モデルが見ているのでは、と考えました。しかし冒頭の写真例のように、テーブルとどんぶりがまったく同じ場合でも高精度で識別できます。おそらくは、店舗ごとの盛り付け方や肉の切り方の微妙な違いを見分けているのでは、と彼は考えています。
データ サイエンティストの技を自動化
AutoML Vision を試すまで、土井さんは自分で設計した ML モデルを用いてラーメン識別器を開発していました。様々な試行錯誤の結果、Inception、ResNet、そして SE-ResNeXt を組み合わせたアンサンブル モデルを作成し、精度を上げるための データ オーギュメンテーション の仕組みを作り、そして時間と手間のかかるハイパーパラメータ チューニングを実施するなど、データ サイエンティストとしてのノウハウを投入して開発してきました。一方、AutoML Vision の場合は、画像とラベルをアップロードして、Train ボタンをクリックするだけです。学習にともなう面倒な試行錯誤や開発工程は不要でした。

AutoML Vision では、Base と Advanced の 2 種類の学習モードを選択できます。Base モードでは、土井さんの画像データの場合、18 分で学習が終わります。Advanced モードでは、およそ 24 時間を要します。いずれの場合も、さまざまな ML モデルを試したり、データ オーギュメンテーションやハイパーパラメータ チューニングに時間を費やしたりする必要はありません。データ サイエンティストの「技」が自動化されています。
この AutoML Vision が現場に与えるインパクトについて、土井さんは次のように説明します。「Base モードでは、そこそこの精度をとても短時間で得られます。一方、Advanced モードでは、最先端レベルの精度をデータ サイエンティストの知識なしに達成できます。このサービスを使えば、データ サイエンティストの仕事の生産性はぐんと上がるはずです。いま企業のデータ サイエンティストのもとにはたくさんの AI 案件が舞い込んでおり、それぞれの PoC でのディープ ラーニング適用を迅速にこなしていく必要があります。AutoML Vision があれば、学習や最適化に長い時間をとられることはありません。つまり、わずかな人数のデータ サイエンティストでも、より多くの案件をこなせるようになります」
また土井さんは、AutoML Vision が備える認識機能も高く評価しています。「学習したすぐ後に、その ML モデルを使ってスケーラブルなオンライン認識サービスを利用できる点も、とても便利です。通常、こうした実運用向けのサービス インフラの構築と運用は、データ サイエンティストにとってもうひとつの頭痛のタネなのです」
メルカリのブランド品を 91% の精度で分類
そして AutoML Vision は、まったく別の用途でもその威力を発揮しています。メルカリでのブランド品識別です。
メルカリでは、ブランド品向けの新しいアプリ、メルカリ メゾンズを提供開始しました。このアプリでの導入に向けて、12 種類の主要なブランド品を画像から識別できる ML モデルの開発を進めてきました。このモデルでは、 TensorFlow 上で VGG16 による転移学習を用いることで 75% の精度を得ていました。

一方、メルカリのデータ サイエンティストが 50,000 枚の画像を用いて AutoML Vision の Advanced モードを試したところ、91.3% の精度(precisionスコア)を達成。既存モデルより 15 ポイント高い成果が得られました。
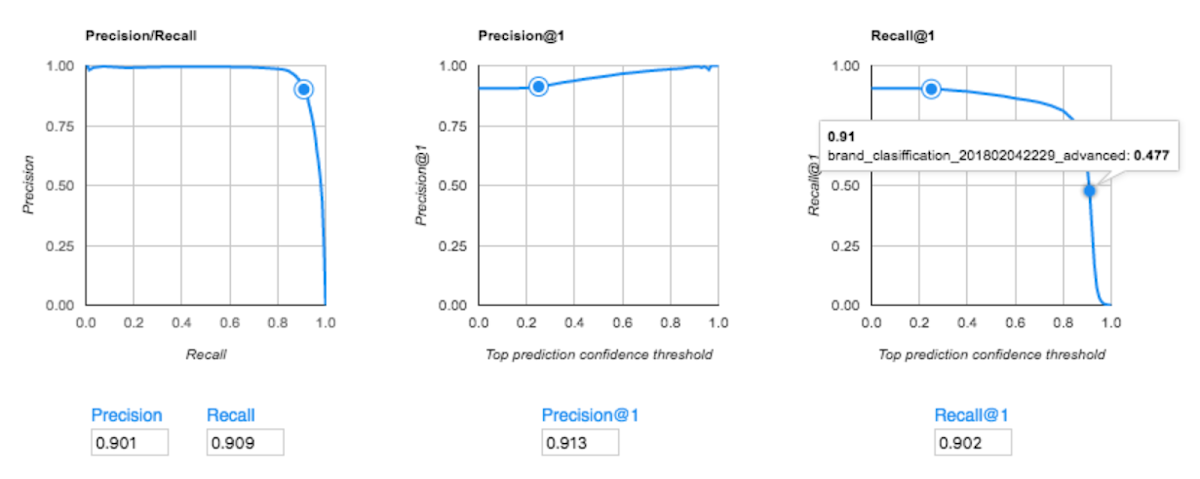
AutoML Vision の高精度の理由
メルカリのデータ サイエンティスト藤原秀平さんは、この結果を見て「Google はどんな仕組みを使ってこんな精度を出しているのか!」と驚いたそうです。AutoML Vision の Advanced モードの裏側では何が行われているのでしょうか。Advanced モードでは、一般的な転移学習だけでなく、NASNet と呼ばれる Google 最新の learning2learn 技術が投入されています。
NASNet では、ML で ML の最適化を行います。つまり、個々の学習画像について最適なディープ ラーニング モデルの設計を行う、メタレベルの ML モデルを使用します。これが Advanced モードの高精度のカギであり、Google が掲げる「AI の民主化」を象徴する技術と言えます。最先端のディープ ラーニング技術の習得に何年もの時間をかけずとも、その恩恵を多くのユーザーが得られます。
また藤原さんは、AutoML Vision の UI の使いやすさも評価しています。「とても使いやすい UI が気に入っています。ハイパーパラメータ チューニングも不要で、学習後の精度も混同行列ですぐに確認できるのが便利です。また、Google 側での手作業によるラベル付け作業もこの UI から依頼できるので、画像認識の開発でいちばん時間のかかるラベル付けを自前でやらずに済むのも助かります。AutoML Vision の公開ベータ版のローンチが待ち遠しいです」
メルカリの急成長を支えた要因のひとつに、そのスマホ アプリのユーザ エクスペリエンス品質の高さがあります。ブランド名検出の精度が高まれば、その価値はさらに引き上げられると期待されます。



