チュートリアル公開 : Distributed TensorFlow と分散トレーニング
Google Cloud Japan Team
機械学習(ML)をめぐる最近の喧噪を踏まえれば、企業が独自の ML モデルの実験に着手し、それら企業の多くが TensorFlow を選んでいるのは決して意外なことではありません。TensorFlow はオープンソースであり、それゆえローカルで実行すればすばやくプロトタイプを作り、試行錯誤を重ねながら小規模で PoC(概念実証)を行うことができます。そして準備が整いしだい、TensorFlow、データ、コードを Google Cloud にプッシュすれば、マルチ CPU や GPU、あるいは TPU さえ利用できるのです。
ML プロジェクトを次のレベルに進められるところまで来たら、インフラストラクチャをどのようにセットアップするかについて、あれこれ決める必要があります。一般に、このときの決定は、運用に必要な作業と ML に必要な作業にかかる時間に影響を与えます。
そこで私たちは、Google Compute Engine で Distributed TensorFlow クラスタを作成、実行する方法と、Google Cloud ML Engine で同じモデルをトレーニングするために同じコードを実行する方法を説明したソリューション チュートリアルを公開しました。チュートリアルのソリューションは必ずしも面白いというわけではない MNIST を使っていますが、そのぶんソリューションの準備作業の側面を強調できているはずです。
オープンソースの TensorFlow がラップトップやプライベート データセンターのサーバー、さらには Raspberry PI でも実行できることはすでに触れました。TensorFlow はさらに分散クラスタでも実行できるため、トレーニングのワークロードを複数のマシンに分割すれば、結果待ちの時間を大幅に短縮することが可能です。
1 つ目のソリューション チュートリアルは、図 1 に示すように、再利用可能なカスタム イメージを作り、Cloud Shell で開始スクリプトを実行して、TensorFlow を実行する Compute Engine インスタンスのグループをセットアップする方法を説明しています。
環境を構築して正しく機能させるためには多くの手順を踏まなければなりません。それぞれのステップは決して複雑なものではありませんが、それらは運用作業のステップであり、そのぶん ML 開発の時間が短くなります。

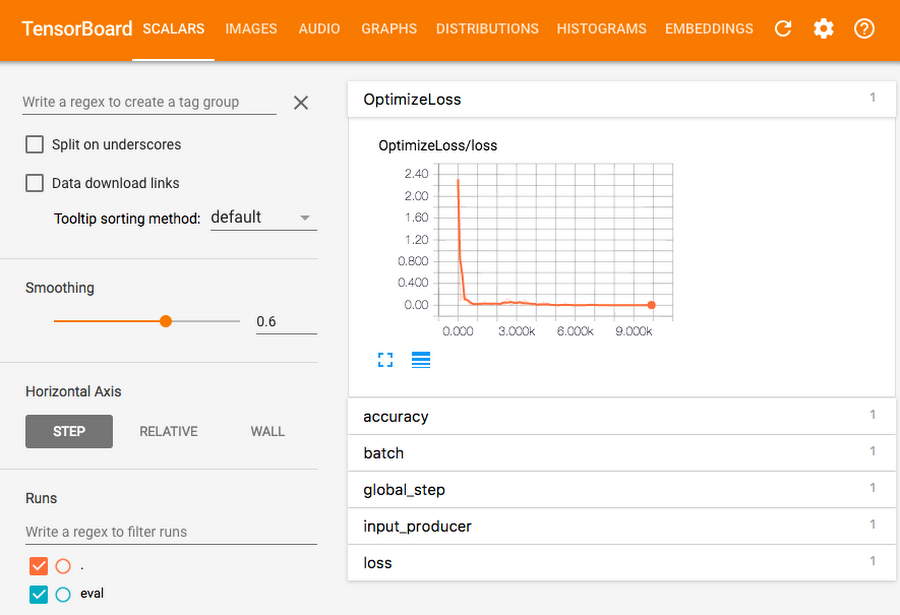
2 つ目のソリューション チュートリアルは、Cloud ML Engine で同じコードを使い、モデルのトレーニングに必要なコンピュート リソースを 1 つのコマンドで自動的にプロビジョニングする方法を説明しています。こちらのチュートリアルでは、ニューラル ネットワークと分散トレーニングに関する一般的な説明にも踏み込むとともに、図 2 に示すように、トレーニングや得られたモデルの可視化のために TensorBoard を試す機会も用意しています。コンピュート リソースのプロビジョニングに要する時間を削減したことで、そのぶん、ML 作業の深い分析に時間を使えるようになったわけです。
モデルをトレーニングする方法がどのようなものであれ、そのモデルを予測に使えなければ意味がありません。この部分は、伝統的に最も多くの作業が必要とされるところです。予測を実行するウェブ サービスを構築するには、少なくとも、複数のウェブ サーバー、ロード バランサ、モニタリング エージェントのプロビジョニングと構成を行い、セキュリティの網をかけて、何らかのバージョン管理のプロセスを作る必要があります。
上述した 2 つのソリューションは、いずれも Cloud ML Engine prediction service を使用することにより、信頼性が高くスケーラブルでセキュアな環境にモデルをホスティングするのに必要な運用面の作業を実質的に不要にしています。
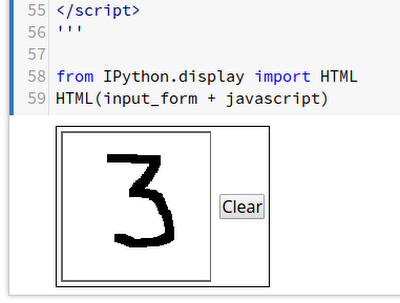
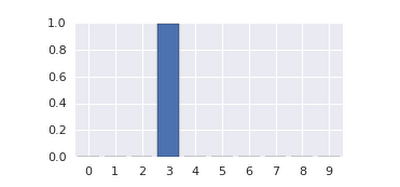
予測のためにモデルをセットアップできたら、Cloud Datalab インスタンスを立ち上げて、予測の実行とテストのためのシンプルなノートブックをダウンロードします。このノートブックでは、図 3 に示すように、マウスかトラックポイントで数字を描くことができます。描いたイメージは、MNIST のデータ形式と一致する適切なイメージ マトリクス形式に変換されます。ノートブックは新しい Prediction API にイメージを送り、図 4 のように、API が予測した数字がどれかを示します。
ここで、予測のモデルをホスティングする作業において最後に残った重要な部分に対処しなければなりません。とはいえ、ソリューション チュートリアルではあまり深く説明されていませんが、これも Cloud ML Engine と Cloud Dataflow が簡単に片づけてくれます。
標準データセットを処理できる事前構築済みの ML モデルを扱っていると、ML モデルのトレーニング、デプロイ、予測はデータ パイプラインの最後のほうになることが多いという点をつい忘れがちになります。しかし現実のシステムでは、使用するデータセットが、データからの学習という目的のためだけに集められた、汚れのないきれいなものであることはまずありえません。
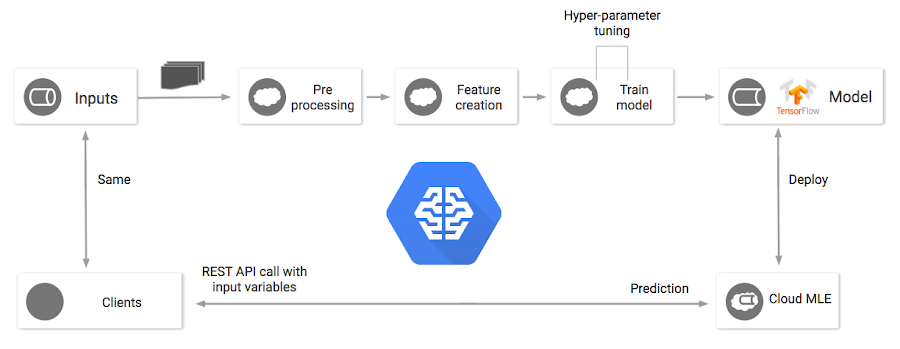
通常は、TensorFlow モデルにデータを渡す前に、データの前処理を行う必要があります。一般的な前処理ステップには、重複の除去、値のスケーリングと変換、語彙集の作成、特異な状況の処理などが含まれます。TensorFlow モデルをトレーニングできるのは、そのような前処理が終わってからです。
予測時にクライアントから送られてくるのも、同じように加工されていないデータです。しかし上述したように、TensorFlow モデルは、重複除去や変換、クリーンアップが行われ、特定の語彙とのマッピングを持つデータを対象としてトレーニングされます。
予測インフラストラクチャは Python で書かれていない場合があるため、使われている言語やシステムに関係なく、必要な水準の統一性や一貫性を確保して前処理を行うライブラリを構築するには、かなりの量の作業が必要です。実際、トレーニングのための前処理と予測のための前処理に一貫性がないことはよくあります。ほんのわずかな不統一があるだけで、予測の結果はさえないものになったり、予想もしなかったものになったりします。
Cloud Dataflow で前処理を行い、Cloud ML Engine で予測を行えば、この種の調整作業は最小限に抑えられ、まったく不要になることもあります。これは、トレーニング時の過去データと予測時のリアルタイム データの両方に対し、Dataflow によって同じ前処理変換コードを適用できるためです。
まとめ
新しい機械学習モデルの開発は、TensorFlow が追加した新しい API や抽象レイヤが、使いたい場所で使えるようになるにつれて簡単になってきています。TensorFlow をサポートした Cloud ML Engine であれば、プロプライエタリなマネージド サービスに縛られるおそれはありません。Compute Engine で独自の TensorFlow クラスタを構築する方法についても、必要に応じて習得することができます。しかし、お客様が本当に望んでいるのは、トレーニングや予測環境のセットアップ作業に取られる時間を減らし、モデルの調整や分析、仕上げにかける時間を増やすことだと私たちは考えています。Cloud ML Engine、Cloud Datalab、Cloud Dataflow を使用すれば、時間の使い方を最適化できます。
運用上の作業は私たち Google に任せ、データをすばやく手軽に分析、可視化して、トレーニングと予測に再利用できる前処理パイプラインを構築しましょう。
* この投稿は米国時間 8 月 18 日、Staff Cloud Solutions Architect である Brad Svee によって投稿されたもの(投稿はこちら)の抄訳です。
- By Brad Svee, Staff Cloud Solutions Architect



