Google I/O で注目の TensorFlow ロボット、その「賢さ」を支える機械学習
Google Cloud Japan Team
Google Cloud デベロッパーアドボケイト 佐藤一憲
ブレインパッド テクノロジー&ソフトウェア開発本部 基盤開発部 部長 下田 倫大
米国マウンテンビューで先月開催された開発者イベント Google I/O 2017 において、Google は機械学習を用いたロボットアームのデモ「Find Your Candy」を展示しました。来場者が自分の好きなお菓子の好みを音声でロボットに教えると、テーブルに並ぶお菓子の中から好みに一番近いものをつかんで渡してくれます。このデモは、6/14 から東京で開催される Google Cloud Next '17 Tokyo の体験エリアでも展示されます。


このロボットに「私はソフトキャンディが好きです」「甘いチョコが食べたい」「ハードミントはある?」といった具合にお菓子の好みを声で伝えると、ロボットは音声認識と自然言語処理を用いてそれを理解し、好みに一番合うお菓子はどれか判断し、画像認識を使ってお菓子を見つけます。これら一連の機械学習技術は、 Google Cloud が提供する Cloud ML Engine(フルマネージドの TensorFlow 実行環境)や 機械学習 API によって実装されています。
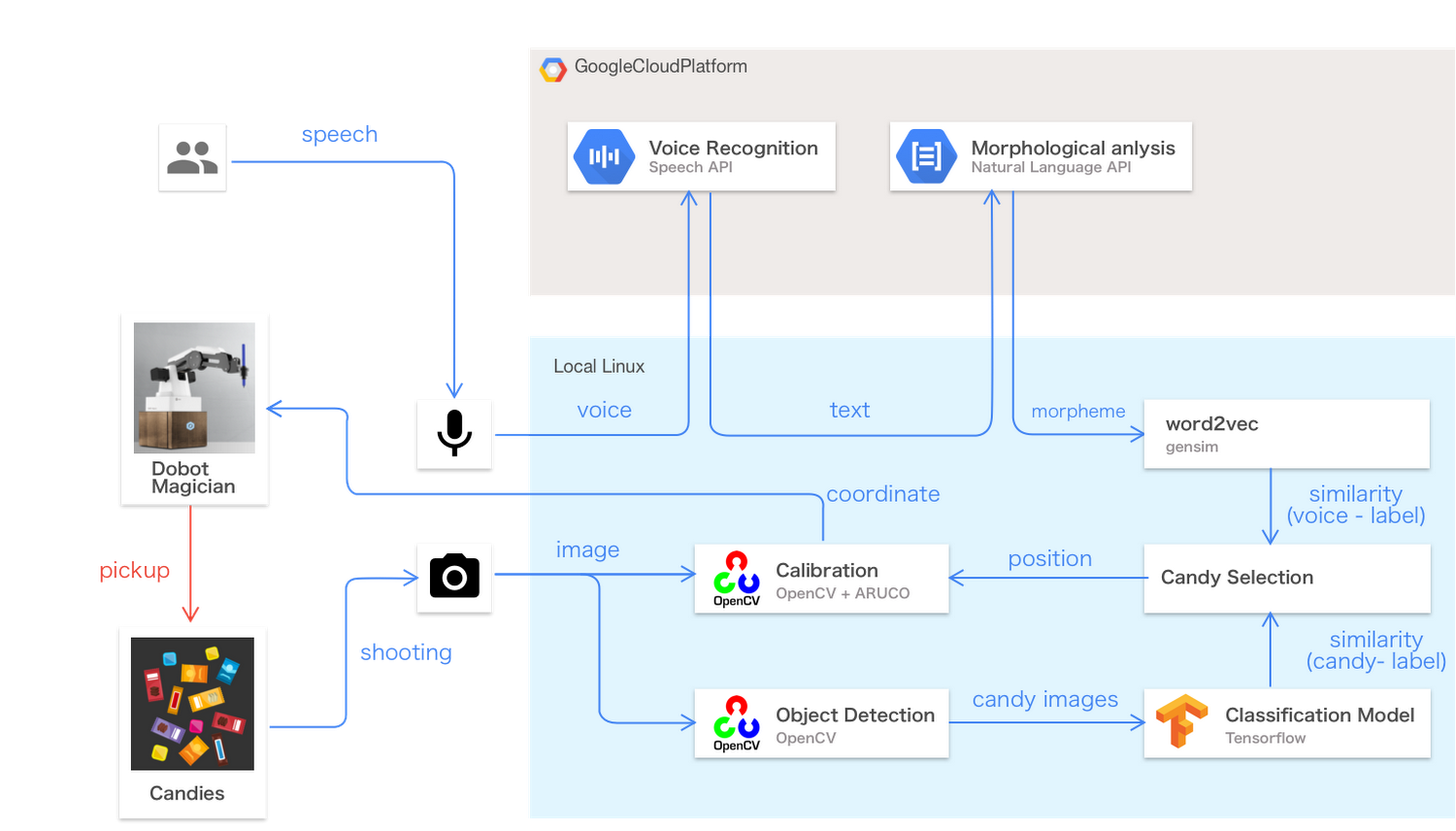
このデモは、実開発でも用いられる機械学習ソリューションのミニチュア版として製作されました。例えば、食品メーカー大手のキユーピーでは、このデモと同じ Google Cloud と TensorFlow による機械学習技術を用い、食品工場におけるダイスポテトの品質管理システムの試作を行っています(詳しくはこのビデオをご覧ください)。
またこのデモのソースコードは GitHub で公開されています。よって、ロボットアームや Linux PC などのハードウェア部品(およそ 27 万円ほど)を揃えれば、誰でも比較的簡単に同じデモを製作でき、各種の機械学習技術を組み合わせて実際に動くソリューションを完成させる過程を楽しみながら学べます。
以下この記事では、この Find Your Candy デモで用いられる機械学習技術について解説し、実際に Google I/O 会場での運用時に直面したトラブルや課題についても紹介します。
音声リクエストを理解する
このデモは、来場者からの音声リクエストを受けて動作を開始します。タブレットで動作する Web UI アプリにて Web Speech API (Cloud Speech API と同じディープラーニングによる音声認識機能を Web アプリに提供する API)を利用し、音声データをテキストに変換します。このテキストを Linux PC コントローラが受け取り、Cloud Natural Language API を用いて形態素解析(単語への分割)と構文解析(品詞と係り受けの推測)の処理結果を得ます。 例えば「私はミントキャンディが好きです」という文章を API に送ると、以下のような処理結果が返されます。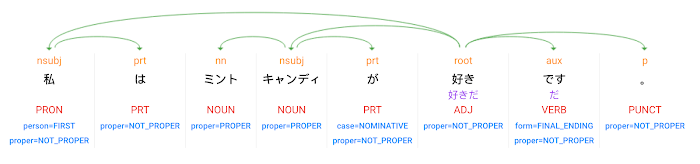
単語の「分散表現」による賢いリコメンド
ここまでの処理で、「ソフト」「ミント」「キャンディ」といった味の好みの情報を音声リクエストから取り出せました。これらの単語をそのまま使って、テーブルの上からマッチするお菓子を見つけることも可能です。しかしこのデモでは、さらに word2vec アルゴリズムを用いて単語の分散表現を計算することで、より賢いお菓子のリコメンドを実現しています。分散表現とは、数 100 個の数を並べたベクトルを用いて個々の単語の意味を表したものです。Embedding Projector のデモを開いて、どれかひとつの点をクリックすると、分散表現によって意味の近い単語が集められている様子を実際に見られます。
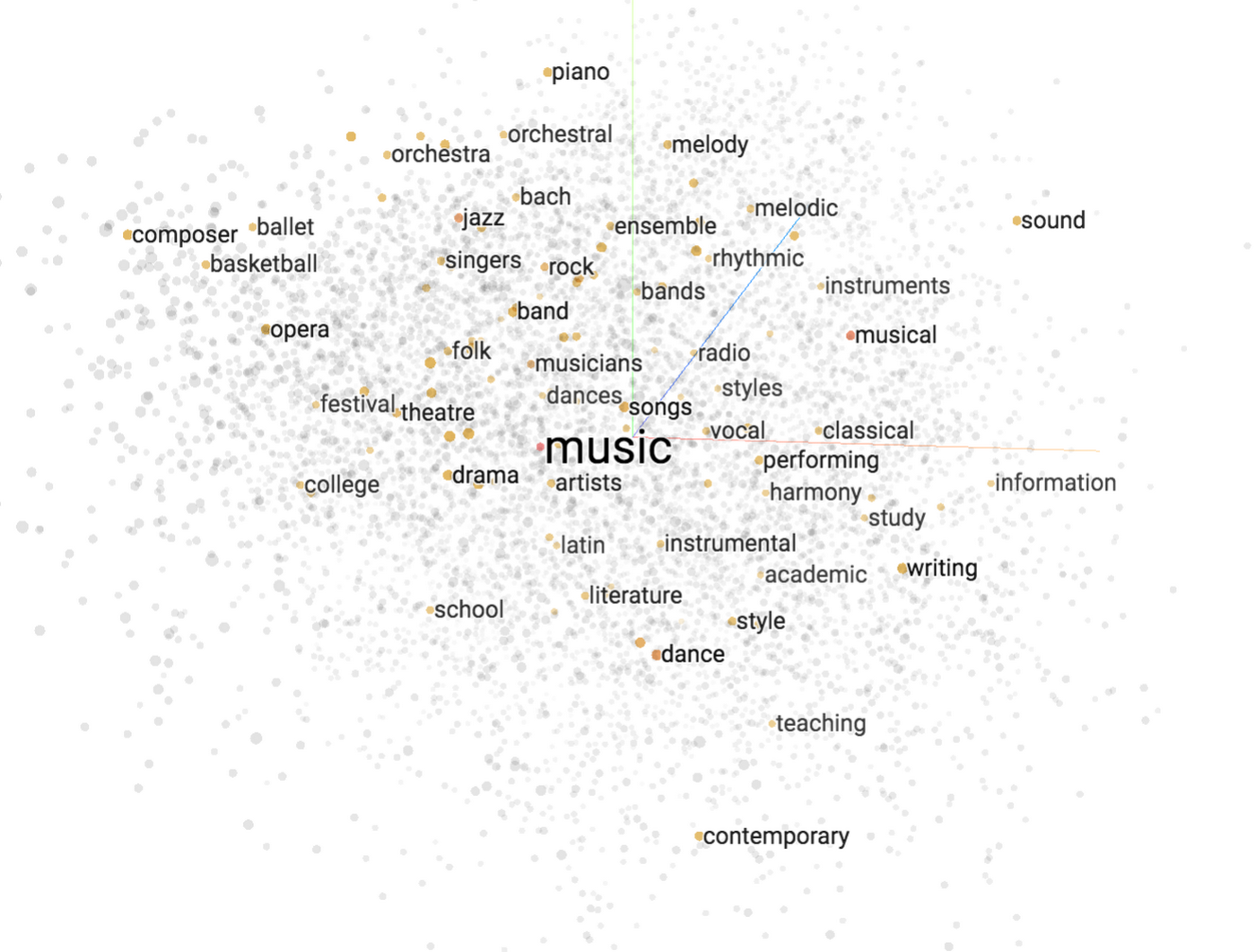
(ここをクリックして試せます)
このデモでわかるように、個々の単語のベクトルは、それに近い意味を持つ別の単語のベクトルと近い位置に現れます。例えば「music」という単語の周りには「songs」「artists」「dances」が集まります。こうした分散表現は、機械学習による自然言語処理の強力なツールのひとつで、ロボットアームがお菓子を選ぶときの「賢さ」を実現します。例えば、来場者が「甘い」「スパイシー」といった単語を使うと、それぞれ「スイート」「辛い」に近い意味であることをロボットアームは理解します。デモの Web UI には、そうした分散表現の分析結果が表示されます。

来場者がしゃべった単語をそのまま使うのではなく、分散表現を介してお菓子を選ぶことで、もし「そのものズバリ」のお菓子がテーブルに載っていない場合でもできるだけ近いものを探せます。
転移学習によりお菓子の味を数分で学習
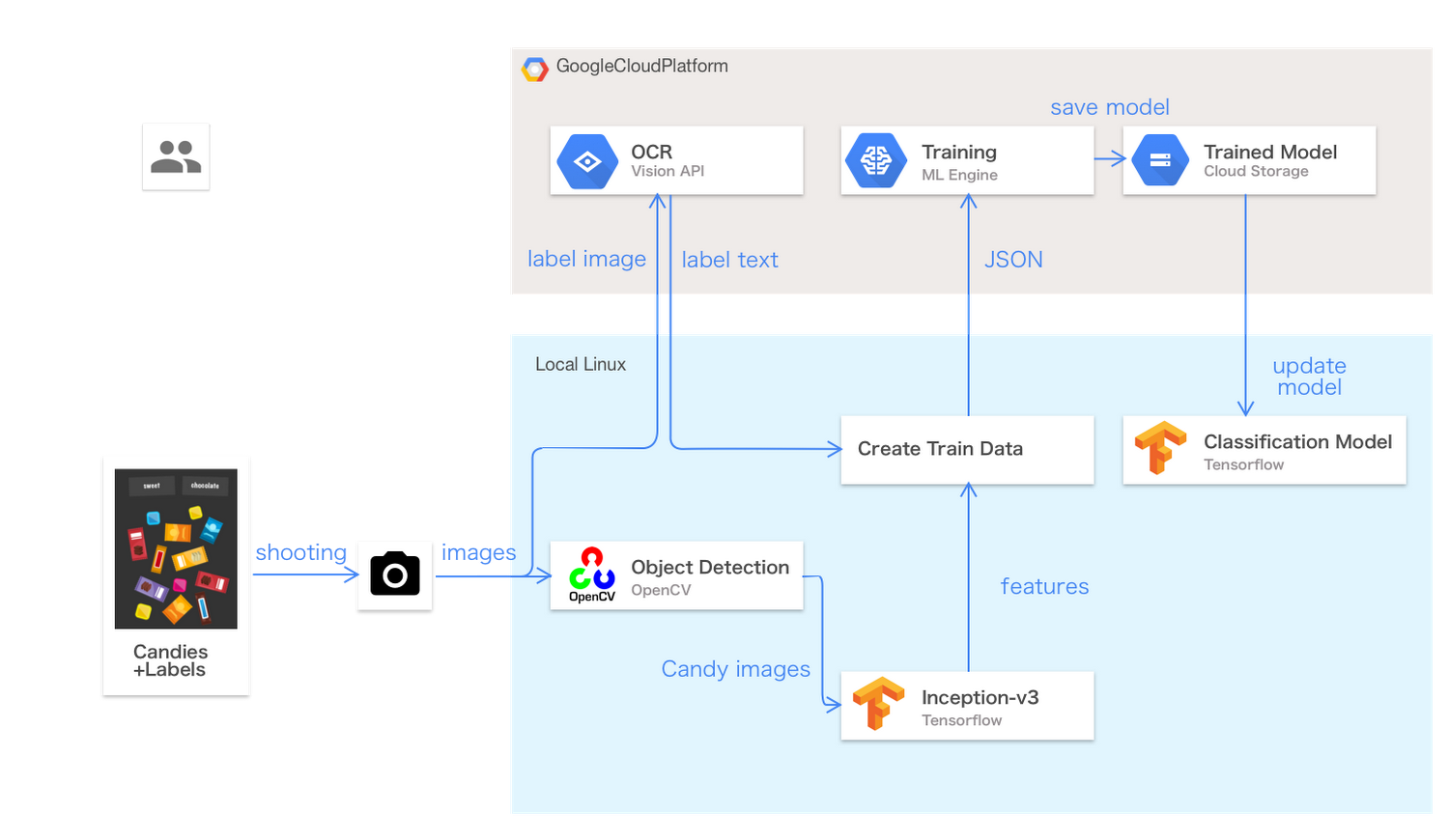
分散表現が得られたら、どの味のお菓子を選べばよいかが決まります。では、テーブルの上のお菓子の味をどうやってロボットは理解するのでしょうか? 実はこのロボットには「学習モード」が備わっており、デモを行う前にお菓子の味を覚えさせることができます。学習モードでは、テーブルの上に「フルーティ」「ミント」などのラベルを貼り、それらの味に対応したお菓子を並べておきます。

学習モードでは、以下の処理が行われます。
- 書画カメラでお菓子とラベルを撮影
- Linux PC が Cloud Vision API に画像を送り、ラベルの文字列を認識
- Linux PC が OpenCV を動作させ、画像から個々のお菓子の画像を切り出す
これにより、テーブル上のお菓子とその味のラベルのペアがいくつか得られます。ディープラーニングの基礎をご存知の読者ならば、これらのペアを使って Inception-v3 などの画像認識用ニューラルネットワークモデルの学習を行えばよいと思われるでしょう。しかし、モデルの学習をゼロから行なうには、こうしたペアを数万個ほど用意し、さらに長時間をかけて学習しなければならず、デモとしては現実的ではありません。
この問題を解決するため、このデモでは転移学習を用いて学習データの規模と学習時間を劇的に小さくしています。転移学習では、あらかじめ学習済みの汎用の画像認識モデルを用いて個々の画像の特徴ベクトルを抽出します。このベクトルには、画像に含まれる色や形、パターン、模様などの特徴を表す数値が並んでいます。これはちょうど単語に対する分散表現と同じ働きをします。
この特徴ベクトルとお菓子のラベルのペアを用いて、数層の隠れ層を持つぐんと小規模なニューラルネットワークモデルの学習を行います。つまり、まずは学習済みの大きな汎用モデルで画像の特徴を捉え、続いて個々の用途に特化した小さなモデルでお菓子の特定をする、という二段階構成が転移学習の仕組みです。
今回のデモでは、学習済みの Inception-v3 モデルでお菓子の画像を認識し、2,048 次元の特徴ベクトルを全結合層から取得、それを用いて TensorFlow 上で動作する小規模な全結合ニューラルネットを学習しています。これらの技法と ML Engine を組み合わせることで、ラベルごとの学習に必要なお菓子画像の数を数個にまで減らし、学習時間も数分に短縮できました。
学習モードで画像認識モデルの学習を行ったあとは、ロボットを実行モードで利用可能になります。実行モードでは、カメラで取得した画像から得られるお菓子のラベルと、音声リクエストと分散表現から得られたラベルのマッチングを行い、拾い上げるお菓子を選択します。
これでロボットがお菓子を拾う準備ができました。
ロボットアームの制御
このデモの目標のひとつは、一般の開発者の誰もが簡単に製作できるデモにすることでした。そこで、17万円ほどで入手できる安価なロボットアーム Dobot Magician を選択しました。これにさらにコントローラ用の Linux PC や書画カメラなど、 10 万円強のハードウェアを追加するだけで材料が揃います(GitHub リポジトリ上にすべてのコンポーネントのリストが掲載されています)。Dobot は制御用の API を公開しているので、そのシリアル通信プロトコルを用いてアームを制御するドライバを作成しました。また、位置調整やセットアップ、デバッグ用のツール群も用意しています。現場で発生した問題
このデモを Cloud Next SF と Google I/O 会場で展示した際には、いくつかの問題点が発生しました。- お菓子のテカリ:お菓子のパッケージのテカリによって認識精度の低下が発生します。そこで個々のお菓子について 2、3 個を違う向きで並べて学習させる必要があります
- 直射日光やスポットライト:デモ環境に強い直射日光やスポットライトが当たると、デモが正しく動作しません
- 騒音:イベント会場の騒音が大きいと音声認識が正しく動きません。元々はタブレットの内蔵マイクで動作する設計でしたが、騒音の大きい会場では外部マイクを設置しました
- つかみやすいお菓子を選ぶ:ロボットアームの吸引カップは様々なモノを掴むのに便利ですが、平らな面のあるモノに制限されます。アームが吸いやすいお菓子をコンビニで探し回りました
- 学習モードが人気:学習モードの実行には 5 分ほどの時間がかかるため、たくさんの来場者に見せることは想定していませんでした。しかし実際には、来場者の多くが学習モードを試してロボットにお菓子を教えることを楽しんでいました。そこで、学習モードをより使いやすくする改修を行いました



