MIT の数学教授が 22 万コアの Compute Engine クラスタを構築
Google Cloud Japan Team
MIT(米国マサチューセッツ工科大学)に在籍する数学の教授が先ごろ、プリエンプティブル VM 上で 22 万コアという Google Compute Engine クラスタの新記録を打ち立てました。これは、パブリック クラウド上で稼働する HPC(ハイパフォーマンス コンピューティング)クラスタとしては史上最大規模となります。
この記録を生み出した Andrew V. Sutherland 氏は計算数論学者で、MIT で主任リサーチ サイエンティストを務めています。同氏は Compute Engine を使い、より高い種数の曲線に対して佐藤・テイト予想やバーチ・スウィンナートン=ダイアー予想の一般論を模索しました。
Sutherland 氏は最近の研究で、L- 函数が簡単に計算でき、面白そうな佐藤・テイト分布を持つ可能性のある曲線を見つけるために、種数 3 の超楕円曲線を 10 の 17 乗個調査しました。これによって約 7 万個の興味深い曲線が得られ、それぞれが最終的に L- 函数および Modular Forms Database(LMFDB)にて独自のエントリを持つとされています。
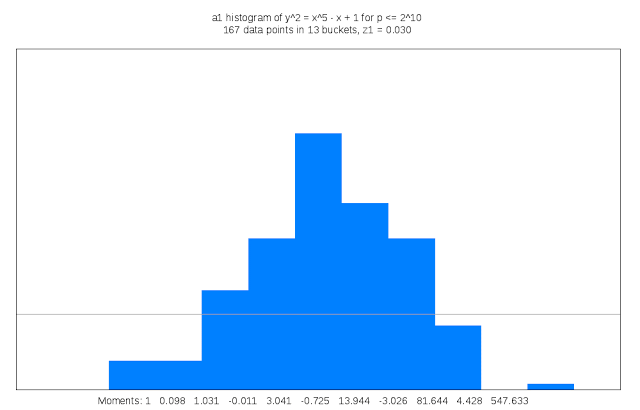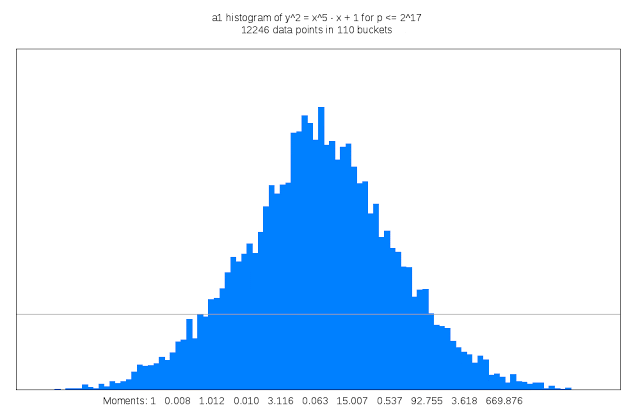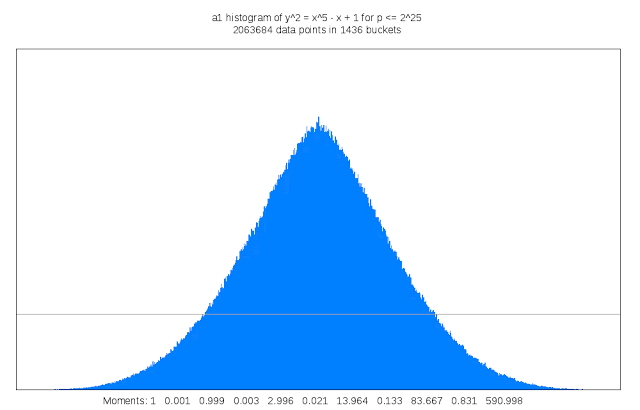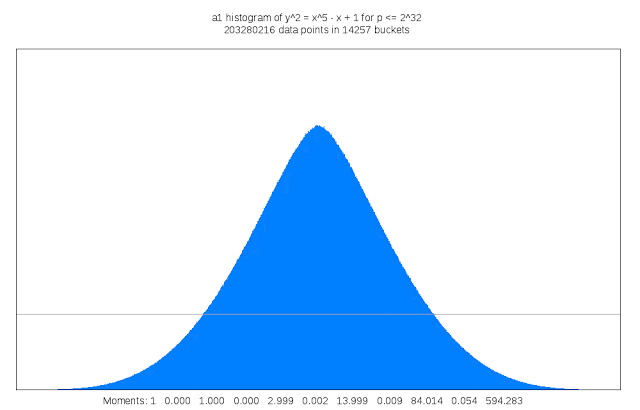
適切な種数 3 の曲線を見つけ出すことは、15 次元の干し草の山から針を探すようなものだと Sutherland 氏は述べています。「私はしばしば、自分の仕事を数学者向けの望遠鏡を作るようなものだと表現したくなることがあります」。
この作業には多大な計算サイクルも必要です。検査対象となる各曲線の判別式を計算するためです。曲線の判別式は、L- 函数を計算する複雑さにおける上界の役割を果たします。この作業は種数 1 においては些細なものですが、種数 3 では 15 変数における 5,000 万の多項式の評価がかかわることもあります。LMFDB に含まれる可能性のある各曲線は、他にも算術的かつ幾何学的な不変式の計算なども必要で、それには L- 函数や佐藤・テイト分布の近似値や曲線が有する対称性の情報なども含まれます。その結果はかなり膨大になる可能性があり、情報の一部は Google Cloud Storage Nearline のオブジェクトとして保管されます。
研究者は LMFDB 内の曲線に関するホーム ページで結果のサマリーを見ることができるほか、より詳しい情報を自身のコンピュータにダウンロードし、さらに調査を進めることが可能です。LMFDB は、Compute Engine 上で稼働する MongoDB データベース内に保管された約 400 GB のメタデータへのオンライン インターフェースを提供します。
Sutherland 氏が Compute Engine を使い始めたのは 2015 年のことです。同氏が最初に手がけたのは、32 コアのインスタンスを 2,250 個起動させ、CPU が 60 年かかる計算を半日で完了させたことでした。
Compute Engine を使うようになるまで、Sutherland 氏は自分の 64 コア マシンを使って何か月もかけてジョブをこなしたり、MIT 内のクラスタの演算時間を巡って論争したりしていました。ただ、同氏が必要としたコア数はたいてい眉をひそめるようなものだったので、同氏が使えるソフトウェア構成の範囲内に限られていました。
Compute Engine に移行すれば、こうした制限から解放され、まさに必要とする OS やライブラリ、アプリケーションをインストールでき、ルート アクセスを介して自由に環境を更新できます。
Sutherland 氏は Google を選択する前に、AWS 上でジョブを稼働させることも考えましたが、AWS のスポット インスタンスが理由で断念しました。スポット インスタンスの場合、言い値価格で事前に利用料金を支払うことが求められ、しかもその価格はリージョンごとに大きく異なり、時期によって変動します。
そこで、Sutherland 氏の同僚が Compute Engine のプリエンプティブル VM を勧めたのです。プリエンプティブル VM はさまざまな機能が備わったインスタンスで、価格も同様のものに比べると最大で 80 % も安価です。これには Compute Engine の割り込みがあるのですが、Sutherland 氏にとっては問題のないことでした。
Sutherland 氏の演算は “Embarrassingly parallel”(簡単に複数の個別タスクに分けることが可能なほど並列)であり、Google Cloud のどのリージョンからも利用可能なインスタンスを使っています。同氏のインスタンスのうち平均で約 2~3 % はだいたい毎時間プリエンプション(シャットダウン)されており、全ジョブが完了するまでシンプルなスクリプトが自動的にインスタンスを再稼働させています。
Sutherland 氏は、ジョブ処理中のインスタンスをコーディネートする際に Cloud Storage と Cloud Datastore を組み合わせて使用しています。インスタンスにタスクを割り当てるシンプルなチケット システムを、Python クライアント API を使って Cloud Datastore に実装しました。インスタンスはローカル ディスク上で定期的に状況をチェックし、プリエンプションした場合はローカル ディスクから復帰できます。また、インスタンスの最終的なアウトプット データは Cloud Storage のバケットに保存され、ジョブが終了すればさらに事後処理にかけることも可能です。
こうして Sutherland 氏は、Compute Engine の高い拡張性や柔軟性により、自身の広大な研究に取り組めるようになったのです。同氏は次回のジョブで検索の範囲を種数 3 の非超楕円曲線にまで拡大させたいとしており、うまくいけば 40 万コア クラスタという構成で自身の記録を更新することになるでしょう。
「質問に対する回答が数か月ではなく数時間で得られるのであれば、研究の展望は完全に変わってきます。いろんな質問ができますからね」(Sutherland 氏)。
* この投稿は米国時間 4 月 20 日、GCP Blog Editor である Alex Barrett と、Compute Engine の Product Manager である Michael Basilyan によって投稿されたもの(投稿はこちら)の抄訳です。
- By Alex Barrett, GCP Blog Editor & Michael Basilyan, Product Manager, Compute Engine



